JVM垃圾回收器理论分析与详解【纯理论】
继续上次【https://www.cnblogs.com/webor2006/p/10740084.html】的理论继续。。有点吐血的感觉,都不知道学了这么一大堆理论有何实际意义,本身JVM就是个理论体系比较多的东东,所以理论不得不去面对,继续硬着头皮往前进。
内存结构

这个在之前的学习中都已经学习过了,复习一下。
内存分配
- 堆上分配
大多数情况在eden【年轻代中的一个区域】上分配,偶尔会直接在old【老年代】上分配,细节取决于GC的实现。 - 栈上分配
原子类型的局部变量。
内存回收
1、GC要做的是将那些dead的对象所占用的内存回收掉。
- Hotspot认为没有引用的对象是dead的。
- Hotspot将引用分为四种:Strong【强引用】、Soft【软引用】、Weak【弱引用】、Phantom【虚引用】,这是大伙熟知的。
1、Strong既默认通过Object o = new Object()这种方式赋值的引用。
2、Soft、Weak、Phantom这三种则是继续Reference。
2、在Full GC时会对Reference类型的引用进行特殊处理。
- Soft:内存不够时一定会被GC、长期不用也会被GC。
- Weak:一定会被GC,当被mark为dead,会在ReferenceQueue中通知。
- Phantom:本来就没引用,当从jvm heap中释放时会通知。
以上的概念会在未来举例进行代码说明的,先有个印象。
垃圾收集算法

以上是一些比较经典的垃圾收集算法,下面会逐个进行说明。
GC的时机
1、在分代模型的基础上,GC从时机上分为两种:Scavenge GC和Full GC。
2、Scavenge GC(Minor GC)
- 触发时机:新对象生成时,Eden空间满了。
- 理论上Eden区大多数对象会在Scavenge GC回收,复制算法的执行效率会很高,Scavenge GC时间比较短。
3、Full GC【这个在实际中一定得要避免】
- 对整个JVM进行整理,包括Young、Old和Perm。
- 主要的触发时机:1)Old满了;2)Perm满了;3)system.gc()
- 效率很低,尽量减少Full GC。
垃圾回收器(Garbage Collector)
- 分代模型:GC的宏观愿景。
- 垃圾回收器:GC的具体实现。
- Hotspot JVM提供多种垃圾回收器,我们需要根据具体应用的需要采用不同的回收器。
- 没有万能的垃圾回收器,每种垃圾回收器都有自己的适用场景。
垃圾收集器的“并行”和“并发”
- 并行(Parallel):指多个收集器的线程同时工作,但是用户线程处于等待状态。
- 并发(Concurrent):指收集器在工作时同时,可以允许用户线程工作。
并发不代表解决了GC停顿的问题,在关键的步骤还是要停顿。比如在收集器标记垃圾的时候。但在清除垃圾的时候,用户线程可以和GC线程并发执行。
Serial收集器
- 单线程收集器,收集时会暂停所有工作线程(Stop The World,简单STW),使用复制收集算法,虚拟机运行在Client模式时的默认新生代会采用此收集器。
- 最早的收集器,单线程进行GC。
- New和Old Generation都可以使用。
- 在新生代,采用复制算法:在老年代,采用Mark-Compact算法。
- 因为是单线程GC,没有多线程切换的额外开销,简单实用。
- Hotspot Client模式缺省的的收集器
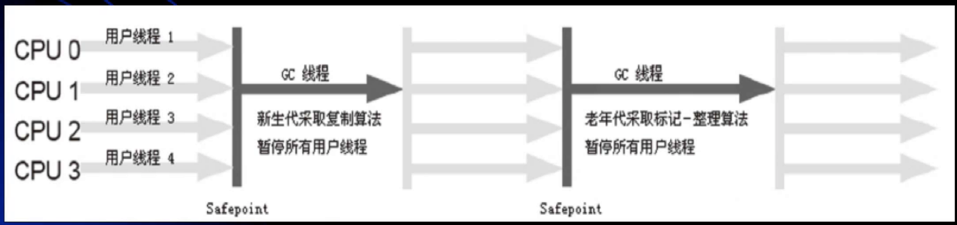
如图中出现了一个词:“Safepoint”,安全点,在之后会举具体的实例来说明安全点的作用。
ParNew收集器
- ParNew收集器就是Serial的多线程版本,除了使用多个收集线程外,其余行为包括算法、STW、对象分配规则、回收策略等都与Serial收集器一模一样。
- 对应的这种收集器是虚拟机运行在Server模式的默认新生代收集器,在单CPU的环境中,ParNew收集器并不会比Serial收集器有更好的效果。
- Serial收集器在新生代的多线程版本。
- 使用复制算法(因为针对新生代)。
- 只有在多CPU的环境下,效率才会比Serial收集器高。
- 可以通过-XX:ParallelGCThreads来控制GC线程数的多少。需要结合具体CPU的个数。
- Server模式下新生代的缺省收集器。
Parallel Scavenge收集器
- Parallel Scavenge收集器也是一个多线程收集器,也是使用复制算法,但它的对象分配规则与回收策略都与ParNew收集器有所不同,它是以吞吐量最大化(既GC时间占总运行时间最小)为目标的收集器实现,它允许较长时间的STW换取总吞吐量最大化。
Serial Old收集器
- Serial Old是单线程收集器,使用标记-整理算法,是老年代的收集器。
Parallel Old收集器
- 老年代版本吞吐量优先收集器,使用多线程和标记一整理算法,JVM1.6提供,在此之前,新生代使用了PS收集器的话,老年代除Serial Old外别无选择,因为PS无法与CMS收集器配合工作。【了解既可】
- Parallel Scavenge在老年代的实现
- 在JVM1.6才出现Parallel Old
- 采用多线程,Mark-Compact算法
- 更注重吞吐量
- Parallel Scavenge + Parallel Old = 高吞吐量,但GC停顿可能不理想

CMS(Concurrent Mark Sweep)收集器【特别复杂的一种收集器】
- CMS是一种以最短停顿时间为目标的收集器,使用CMS并不能达到GC效率最高(总体GC时间最小),但它能尽可能降低GC时服务的停顿时间,CMS收集器使用的是标记-清除算法。
- 追求最短停顿时间,非常适合Web应用。
- 只针对老年区,一般结合ParNew使用。
- Concurrent,GC线程和用户线程并发工作(尽量并发)。
- Mark-Sweep。
- 只有在多CPU环境下才有意义 。
- 使用-XX:+UseConcMarkSweepGC打开。
- CMS以牺牲CPU资源的代价来减少用户线程的停顿。当CPU个数少于4的时候,有可能对吞吐量影响非常大。
- CMS在并发清理的过程中,用户线程还在跑。这时候需要预留一部分空间给用户线程。
- CMS用Mark-Sweep,会带来碎片问题。碎片过多的时候会容易频繁触发Full GC。
GC垃圾收集器的JVM参数定义

Java内存泄漏的经典原因
1、对象定义在错误的范围(Wrong Scope)。
- 如果Foo实例对象的生命较长,会导致临时性内存泄漏。(这里的names变量其实只是临时作用)

- JVM喜欢生命周期短的对象,这样做已经足够高效【调整】

这样一改之后,只要是doIt()方法一结束names的临时变量就立马会被回收。
2、异常(Exception)处理不当。
- 错误的做法

对于有经验的程序员应该不会出现上面的问题,但是这里只是抛出泄漏的场景。 - 正确的做法
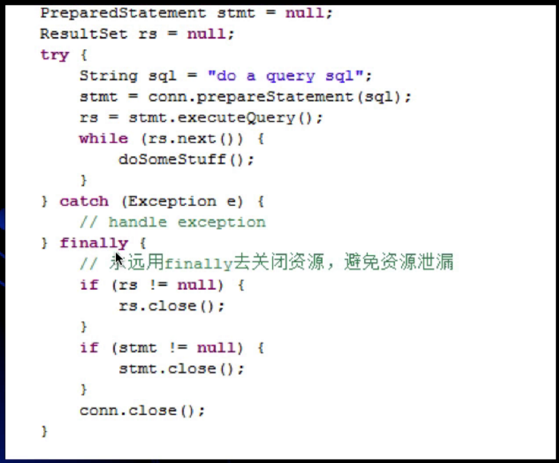
3、集合数据管理不当。
- 当使用Array-based的数据结构(ArrayList,HashMap等)时,尽量减少resize:
a、比如new ArrayList时,尽量估算size,在创建的时候把size确定。
b、减少resize可以避免没有必要的array copying,gc碎片等问题。 - 如果一个List只需要顺序访问,不需要随机访问(Random Access),用LinkedList代替ArrayList
a、LInkedList本质是链表,不需要resize,但只适用于顺序访问。
以上是对JVM垃圾回收相关理论的整体了解,说实话看完其实头晕晕的,没关系,接下来则会用实践来反证理论。
JVM垃圾回收器理论分析与详解【纯理论】的更多相关文章
- 7种jvm垃圾回收器,这次全部搞懂
前言 之前我们讲解了jvm的组成结构与垃圾回收算法等知识点,今天我们来讲讲jvm最重要的堆内存是如何使用垃圾回收器进行垃圾回收,并且如何使用命令去配置使用这些垃圾回收器. 堆内存详解 上面这个图大家应 ...
- Jvm垃圾回收器(算法篇)
在<Jvm垃圾回收器(基础篇)>中我们主要学习了判断对象是否存活还是死亡?两种基础的垃圾回收算法:引用计数法.可达性分析算法.以及Java引用的4种分类:强引用.软引用.弱引用.虚引用.和 ...
- JVM 垃圾回收器工作原理及使用实例介绍(转载自IBM),直接复制粘贴,需要原文戳链接
原文 https://www.ibm.com/developerworks/cn/java/j-lo-JVMGarbageCollection/ 再插一个关于线程和进程上下文,待判断 http://b ...
- Jvm垃圾回收器(终结篇)
知识回顾: 第一篇<Jvm垃圾回收器(基础篇)>主要讲述了判断对象的生死?两种基础判断对象生死的算法.引用计数法.可达性分析算法,方法区的回收.在第二篇<Jvm垃圾回收器(算法篇)& ...
- 【转】Java学习---垃圾回收算法与 JVM 垃圾回收器综述
[原文]https://www.toutiao.com/i6593931841462338062/ 垃圾回收算法与 JVM 垃圾回收器综述 我们常说的垃圾回收算法可以分为两部分:对象的查找算法与真正的 ...
- 垃圾回收算法与 JVM 垃圾回收器综述(转)
垃圾回收算法与 JVM 垃圾回收器综述 我们常说的垃圾回收算法可以分为两部分:对象的查找算法与真正的回收方法.不同回收器的实现细节各有不同,但总的来说基本所有的回收器都会关注如下两个方面:找出所有的存 ...
- JVM垃圾回收器原理及使用介绍
JVM垃圾回收器原理及使用介绍 垃圾收集基础 引用计数法(Reference Counting) 标记-清除算法(Mark-Sweep) 复制算法(Copying) 标记-压缩算法(Mark-Comp ...
- JVM基础系列第9讲:JVM垃圾回收器
前面文章中,我们介绍了 Java 虚拟机的内存结构,Java 虚拟机的垃圾回收机制,那么这篇文章我们说说具体执行垃圾回收的垃圾回收器. 总的来说,Java 虚拟机的垃圾回收器可以分为四大类别:串行回收 ...
- 【Java】HashMap源码分析——常用方法详解
上一篇介绍了HashMap的基本概念,这一篇着重介绍HasHMap中的一些常用方法:put()get()**resize()** 首先介绍resize()这个方法,在我看来这是HashMap中一个非常 ...
随机推荐
- 认识随机函数rand()和srand(unsigned int )
rand函数 int rand( void ); 函数名: rand 功 能: 随机数发生器 用 法: int rand(void); 所在头文件: stdlib.h 函数说明 : ...
- Scala 在挖财的应用实践
编者按:本文是根据ArchSummit 大会上挖财资深架构师王宏江的演讲<Scala 在挖财的应用实践>整理而成. 这次分享有三个方面,一是介绍一下挖财当前的开发情况和后端的架构, 二是挖 ...
- 【Docker】涨姿势,深入了解Dockerfile 中的 COPY 与 ADD 命令
参考资料:https://www.cnblogs.com/sparkdev/p/9573248.html Dockerfile 中提供了两个非常相似的命令 COPY 和 ADD,本文尝试解释这两个命令 ...
- TreeMap源码分析2
package map; import org.junit.Test; import com.mysql.cj.api.x.Collection; import map.TreeMap1.Ascend ...
- sqlException 使用relace 替换单引号
我们从前端输入数据的时候,可能会输入一些 单引号 ,的字符 导致直接进行执行sql 语句保存的时候出现错误 如: 输入的有 单引号 保存按钮小代码 <asp:Button ID="bt ...
- 存储过程中的BeginEnd
存储过程中的BeginEnd和其它语言中的花括号,本身没有事务作用,主要有两个作用1.使语句结果清晰2.语句块作用,比如在 if 后面使用.
- Logback获取SkyWalking的全局唯一标识 trace-id 记录到日志中
为什么要获取trace-id 通过上文Docker-Compose搭建单体SkyWalking我们搭建了SkyWalking服务,我们需要在日志中记录下来每次请求的唯一标识(trace-id),这样就 ...
- k8s创建pod和service的过程
一.概念介绍 更详细的参见:https://www.kubernetes.org.cn/5335.html 1.K8s K8s 是一种用于在一组主机上运行和协同容器化应用程序的系统,提供应用部署.规划 ...
- http://www.cnblogs.com/xdp-gacl/p/4200090.html
孤傲苍狼 只为成功找方法,不为失败找借口! JavaWeb学习总结(五十)——文件上传和下载 在Web应用系统开发中,文件上传和下载功能是非常常用的功能,今天来讲一下JavaWeb中的文件上传和下载功 ...
- React 父/子窗体参数传递
1.父窗体 import Modal from './Modal' onModalRef = ref => { this.modal = ref } onCallback = msg => ...