大数据之路【第十四篇】:数据挖掘--推荐算法(Mahout工具)
数据挖掘---推荐算法(Mahout工具)
一、简介
- Apache顶级项目(2010.4)
- Hadoop上的开源机器学习库
- 可伸缩扩展的
- Java库
- 推荐引擎(协同过滤)、聚类和分类

二、机器学习介绍
- 通常问题都归为这几类问题
- 分类问题
- 回归问题
- 聚类问题
- 推荐问题
三、安装方法
3.1 下载Mahout
wget http://archive.apache.org/dist/mahout/0.9/mahout-distribution-0.9.tar.gz
3.2 解压
tar -zxvf mahout-distribution-0.9.tar.gz
四、配置环境变量
4.1 配置mahout环境变量
# set mahout environment
export MAHOUT_HOME=/usr/local/src/mahout-distribution-0.9
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
4.2 配置Mahout所需的Hadoop环境变量
# set hadoop environment
export HADOOP_HOME=/usr/local/src/hadoop-1.2.1
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_HOME_WARN_SUPPRESS=not_null
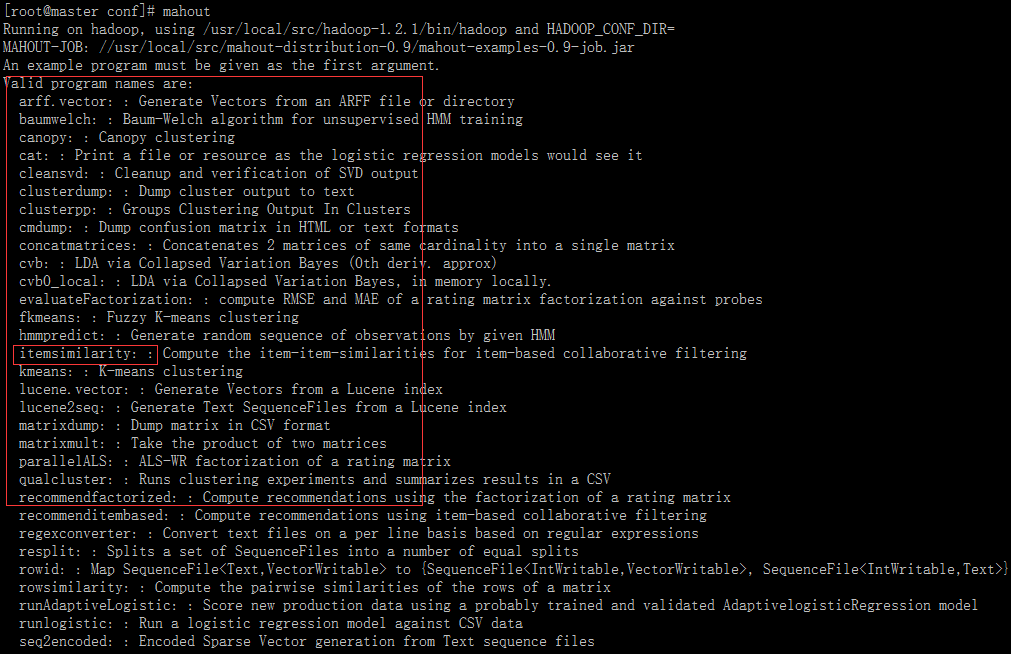
五、验证是否成功
直接执行mahout命令
支持算法列表
六、准备数据
数据格式:
1,100001,5
1,100002,3
1,100003,4
1,100004,3
1,100005,3
1,100007,4
1,100008,1
1,100009,5
1,1000011,2
七、训练
INPUT="/movie_lens.data"
TMP_DIR="/mahout_temp"
OUTPUT="/cf_mahout_output"
MAHOUT_CMD="/usr/local/src/mahout-distribution-0.9/bin/mahout“
$MAHOUT_CMD itemsimilarity
-i $INPUT
-o $OUTPUT
--maxSimilaritiesPerItem 1000
--threshold 0.0000001
--similarityClassname SIMILARITY_COSINE
--tempDir $TMP_DIR
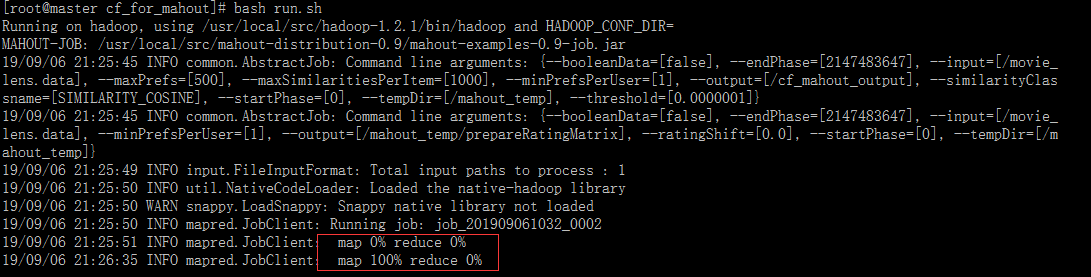
八、输出结果

大数据之路【第十四篇】:数据挖掘--推荐算法(Mahout工具)的更多相关文章
- Python之路【第二十四篇】Python算法排序一
什么是算法 1.什么是算法 算法(algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出.简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果. ...
- 大数据笔记(二十四)——Scala面向对象编程实例
===================== Scala语言的面向对象编程 ======================== 一.面向对象的基本概念:把数据和操作数据的方法放到一起,作为一个整体(类 c ...
- Python之路(第二十四篇) 面向对象初级:多态、封装
一.多态 多态 多态:一类事物有多种形态,同一种事物的多种形态,动物分为鸡类,猪类.狗类 例子 import abc class H2o(metaclass=abc.ABCMeta): def _ ...
- Python之路(第十四篇)os模块
一.os模块 1.os.getcwd() 获取当前工作目录(当前工作目录默认都是当前文件所在的文件夹) import os print(os.getcwd()) 2.os.chdir(path) 改变 ...
- Vue学习之路第十四篇:v-for指令中key的使用注意事项
1.学前准备: JavaScript中有一个方法:unshift() ,其作用是向数组的开头添加一个或更多元素,并返回新的长度.该方法的第一个参数将成为数组的新元素 0,如果还有第二个参数,它将成为新 ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- Python之路【第十四篇】:AngularJS --暂无内容-待更新
Python之路[第十四篇]:AngularJS --暂无内容-待更新
- 解剖SQLSERVER 第十四篇 Vardecimals 存储格式揭秘(译)
解剖SQLSERVER 第十四篇 Vardecimals 存储格式揭秘(译) http://improve.dk/how-are-vardecimals-stored/ 在这篇文章,我将深入研究 ...
- Spring Cloud第十四篇 | Api网关Zuul
本文是Spring Cloud专栏的第十四篇文章,了解前十三篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring C ...
随机推荐
- Java中lambda表达式学习
一.Lambda表达式的基础语法: Java8中引入了一个新的操作符"->"该操作符称为箭头操作符或Lambda操作符,箭头操作符将Lambda表达式拆分为两部分: 左侧:L ...
- 常用方法 Excel转换为DataSet
注意一下Excel格式,我平时导入的是xlsx /// <summary> /// Excel 转换为 DataSet /// </summary> /// <param ...
- 【概率DP】$P2059$ 卡牌游戏
链接 题目描述 N个人坐成一圈玩游戏.一开始我们把所有玩家按顺时针从1到N编号.首先第一回合是玩家1作为庄家.每个回合庄家都会随机(即按相等的概率)从卡牌堆里选择一张卡片,假设卡片上的数字为X,则庄家 ...
- pytest以函数形式形成测试用例
#coding=utf- from __future__ import print_function #开始执行该文件时,该函数执行 def setup_module(module): print(' ...
- sysmain服务怎么启动 & Win7 SuperFetch无法启动
在控制面板/管理工具/服务中,只需找到Superfetch这个服务,双击,然后将其启动类型改为自动,并点击启动按钮并确定即可. Superfetch无法启动,系统找不到指定档案 ms-windows ...
- SpringBoot之文件上传体积过大问题(解决方案)
错误信息如下(关键): org.apache.tomcat.util.http.fileupload.FileUploadBase$SizeLimitExceededException: the re ...
- JS简单获取当前日期时间的方法(yyyy-MM-dd hh:mm:ss)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xht ...
- poi导入读取时间格式问题
万能处理方案: 所有日期格式都可以通过getDataFormat()值来判断 yyyy-MM-dd-----14 yyyy年m月d日--- 31 yyyy年m月-------57 m月d日 ---- ...
- sql脱库的几种方法
当发现sql注入之后,脱库的方法,有以下几种: (1)当目标主机支持外部连接时,使用Navicat 进行连接!当时目标主机不同,使用的Navicat种类不一样: mysql : Navicat f ...
- Unity2019.1中文技术手册离线版
使用离线版优质.系统化的教程.经验文档.参考手册,为开发者节省时间,提高效率! 解压后打开UnityDocumentation_2019.1/Manual/index.html 需要的自取,下载地址: ...