Hadoop(一)—— 启动与基本使用
一、安装&启动
安装
下载hadoop2.7.2
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
2.7.2-官方文档
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
安装ssh
## 检查是否有ssh
## 若返回结果有openssh-clients、openssh-server说明安装
rpm -qa | grep ssh
## 检查ssh是否可用
ssh localhost
启动
查看hadoop版本
./bin/hadoop version
运行一个例子
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
输出结果

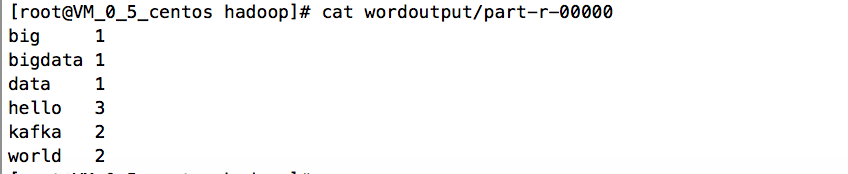
运行WordCount样例
创建文件夹wordinput以及在文件夹下创建word.txt文本,文本内容如下:
hello
world
hello
kafka kafka
hello world
big data
bigdata
执行脚本
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wordinput wordoutput
得到运行结果
Hadoop 配置文件
hadoop core-default配置文件介绍
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/core-default.xml
配置etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中的NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
启动HDFS
执行脚本
./bin/hdfs namenode -format
下面两种方式是等价的
./sbin/start-dfs.sh
或
## 启动namenode进程
./sbin/hadoop-daemon.sh start namenode
## 启动datanode进程
./sbin/hadoop-daemon.sh start datanode
namenode是什么?datanode是什么?为什么必须要格式化namenode才能启动成功?
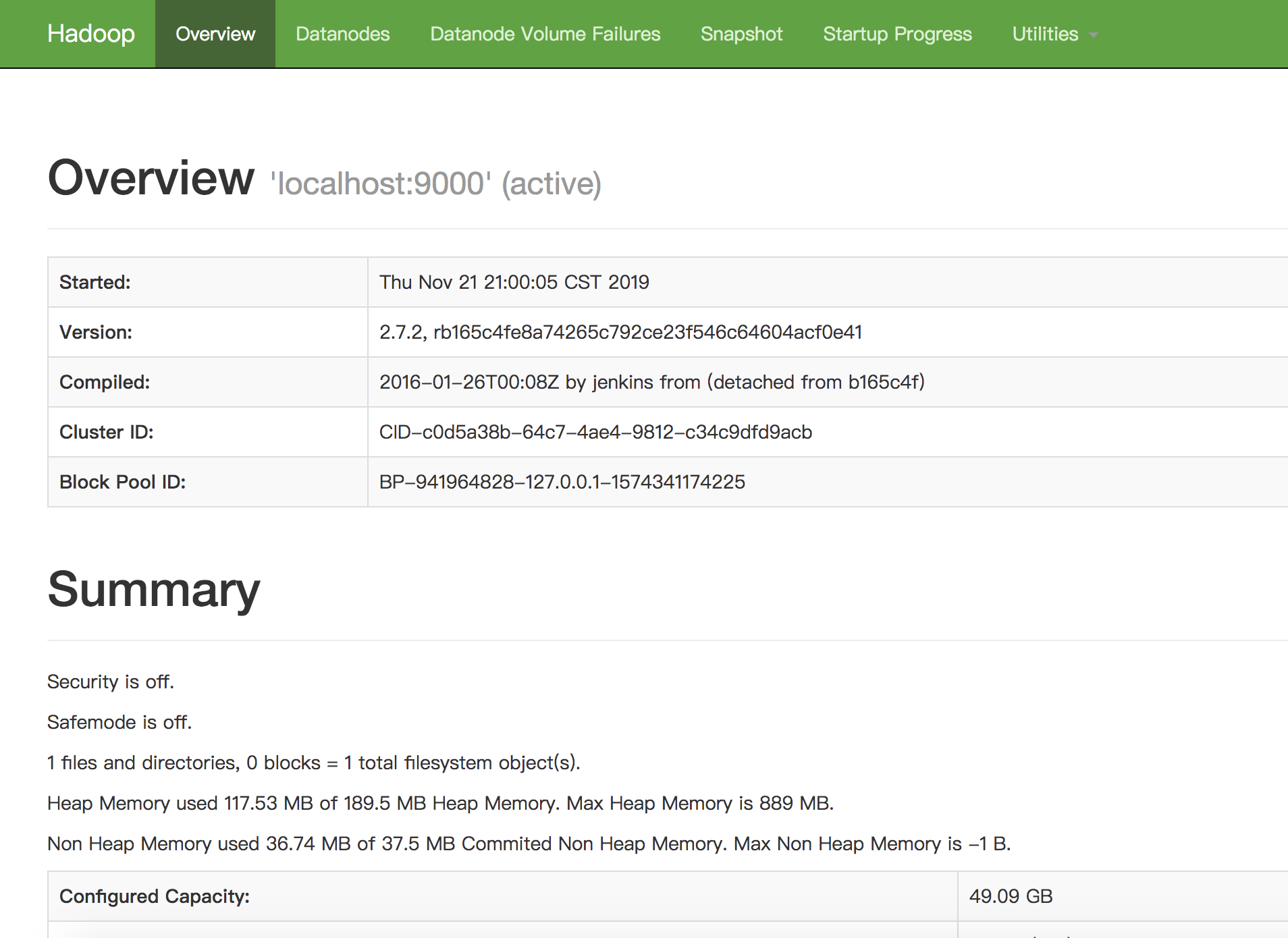
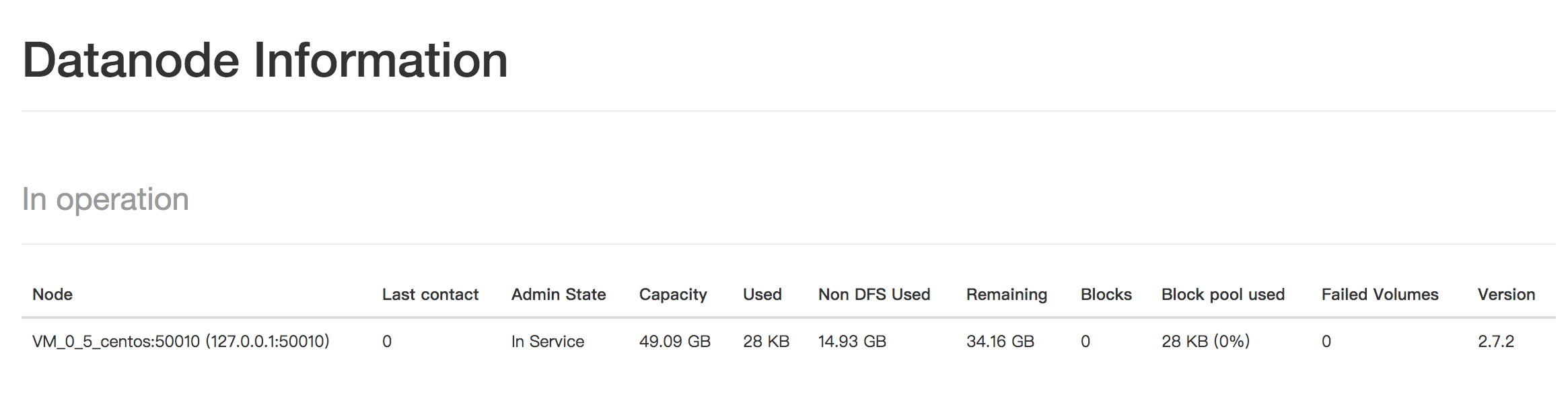
访问 http://127.0.0.1:50070/dfshealth.html#tab-overview
看到DFS的面板。
启动Yarn
配置etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动 ResourceManager daemon and NodeManager daemon:
sbin/start-yarn.sh
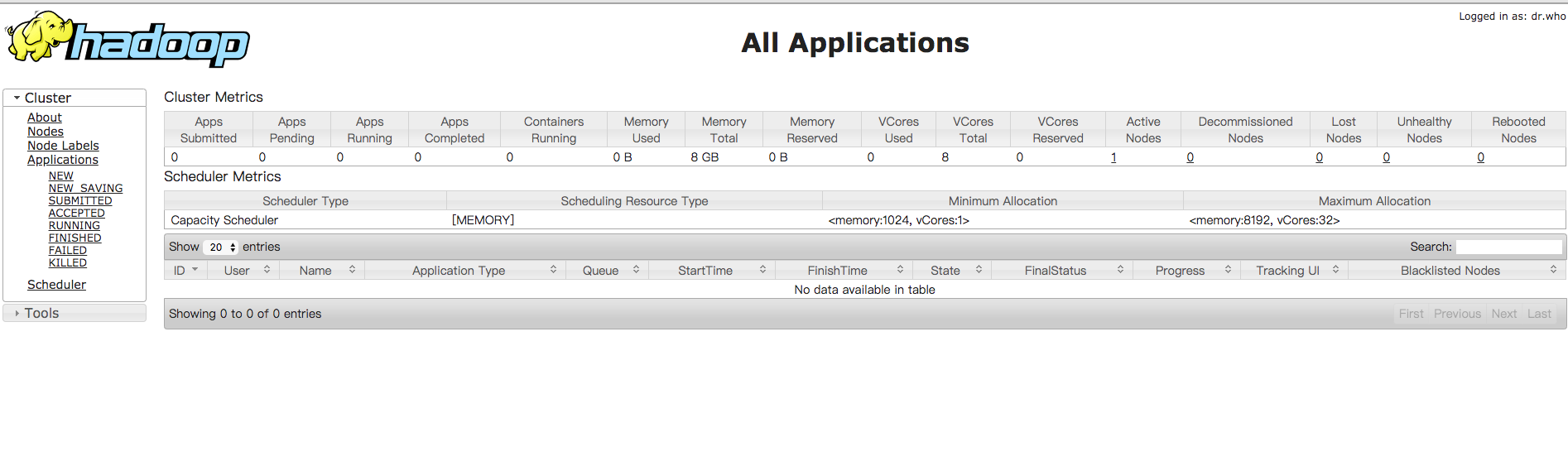
打开资源管理的web页面,http://localhost:8088/
问题解决
每次启动HDFS,都必须格式化,才能启动NameNode
原因是,配置HDFS时,只配置了DataNode目录,没有配置NameNode相关信息。默认的tmp文件每次重新开机都会被清空,导致集群找不到NameNode信息,所以需要每次都重新格式化。
解决方法:
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/Hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
参考文档
Hadoop官网-Hadoop: Setting up a Single Node Cluster
Hadoop官网2.7.3
《Hadoop权威指南》
尚硅谷大数据之Hadoop
运行第一个MapReduce程序
MapReduce过程详解(基于hadoop2.x架构)
Hadoop(一)—— 启动与基本使用的更多相关文章
- Hadoop的启动和停止说明
Hadoop的启动和停止说明 sbin/start-all.sh 启动所有的Hadoop守护进程.包括NameNode. Secondary NameNode.DataNode.ResourceM ...
- 虚拟机搭建和安装Hadoop及启动
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 使用root配置的hadoop并启动会出现报错
1.使用root配置的hadoop并启动会出现报错 错误: Starting namenodes on [master] ERROR: Attempting to op ...
- hadoop datanode启动失败
问题导读: 1.Hadoop出现问题时,该如何入手查看问题?2.datanode无法启动,我们该怎么解决?3.如何动态加入DataNode或TaskTracker? 一.问题描述当我多次格式化文件系统 ...
- hadoop namenode启动过程详细剖析及瓶颈分析
NameNode中几个关键的数据结构 FSImage Namenode 会将HDFS的文件和目录元数据存储在一个叫fsimage的二进制文件中,每次保存fsimage之后到下次保存之间的所有hdfs操 ...
- Hadoop--有关Hadoop的启动
这里我们已经安装好Hadoop,并且已经配置好了环境变量. 安装相关文章:http://blog.csdn.net/gaopeng0071/article/details/10216303 参考网站: ...
- hadoop datanode 启动出错
FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block po ...
- Hadoop 配置文件 & 启动方式
配置文件: 默认的配置文件:相对应的jar 中 core-default.xml hdfs-default.xml yarn-default.xml mapred-default.xml 自定义配置文 ...
- Hadoop在启动时的坑——start-all.sh报错
1.若你用的Linux系统是CentOS的话,这是一个坑: 它会提示你JAVA_HOME找不到,现在去修改文件: .修改hadoop配置文件,手动指定JAVA_HOME环境变量 [${hadoop_h ...
随机推荐
- webpack-dev-server的使用
1.安装 npm install webpack-dev-server --save-dev ps:为保证webpack-dev-server能正常运行,请确认在本地项目中下载了webpack的包,可 ...
- js求对象数组的交集/并集/差集/去重
1.求交集 var arr1 = [{name:'name1',id:1},{name:'name2',id:2},{name:'name3',id:3}]; var arr1Id = [1,2,3] ...
- Python学习日记(十三) 递归函数和二分查找算法
什么是递归函数? 简单来说就是在一个函数中重复的调用自己本身的函数 递归函数在调用的时候会不断的开内存的空间直到程序结束或递归到一个次数时会报错 计算可递归次数: i = 0 def func(): ...
- centos 7.6 修改vim配色方案
cd ~ vim .vimrc colorscheme desert
- RabbitMQ java 原生代码
rabbitMQ 的交换器有四种类型:direct.fanout.topic.headers 以下是具体的代码: direct:路由键只能全部匹配,才能进入到指定队列中.其他使用 direct生产者 ...
- springboot引用三方jar包
在springboot项目中可能会用到三方工具类(比如接入短信网关时给出的工具jar包),这时候需要在springboot项目中手动引入进来 1. springboot工程目录, lib/ucpaas ...
- zabbix-web界面显示中文
转载:https://www.cnblogs.com/miclesvic/p/6145171.html 1.确认zabbix是否开启了中文支持功能(/var/www/html/zabbix/inclu ...
- node+express 搭建本地服务
首先,得有node环境,其次建个项目 目录例如 酱紫! 再次 写server.js,当然你可以换个名字a.js .b.js.why.js随你喜欢 var express = require('exp ...
- 项目(二)--完成练手feed流网站开发部署
样式需要优化,最简版,还需新增逻辑. 点击跳转 源码
- vscode常用快捷键总结
记住快捷键能够提高工作效率 Ctrl+Shift+P,F1 展示全局命令面板 Ctrl+P 快速打开最近打开的文件 Ctrl+Shift+N 打开新的编辑器窗口 Ctrl+Shift+W 关闭编辑器 ...