Hadoop(一)—— 启动与基本使用
一、安装&启动
安装
下载hadoop2.7.2
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
2.7.2-官方文档
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
安装ssh
## 检查是否有ssh
## 若返回结果有openssh-clients、openssh-server说明安装
rpm -qa | grep ssh
## 检查ssh是否可用
ssh localhost
启动
查看hadoop版本
./bin/hadoop version
运行一个例子
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
输出结果

运行WordCount样例
创建文件夹wordinput以及在文件夹下创建word.txt文本,文本内容如下:
hello
world
hello
kafka kafka
hello world
big data
bigdata
执行脚本
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wordinput wordoutput
得到运行结果
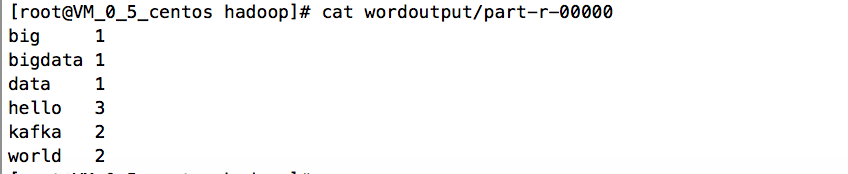
Hadoop 配置文件
hadoop core-default配置文件介绍
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/core-default.xml
配置etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中的NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
启动HDFS
执行脚本
./bin/hdfs namenode -format
下面两种方式是等价的
./sbin/start-dfs.sh
或
## 启动namenode进程
./sbin/hadoop-daemon.sh start namenode
## 启动datanode进程
./sbin/hadoop-daemon.sh start datanode
namenode是什么?datanode是什么?为什么必须要格式化namenode才能启动成功?
访问 http://127.0.0.1:50070/dfshealth.html#tab-overview
看到DFS的面板。
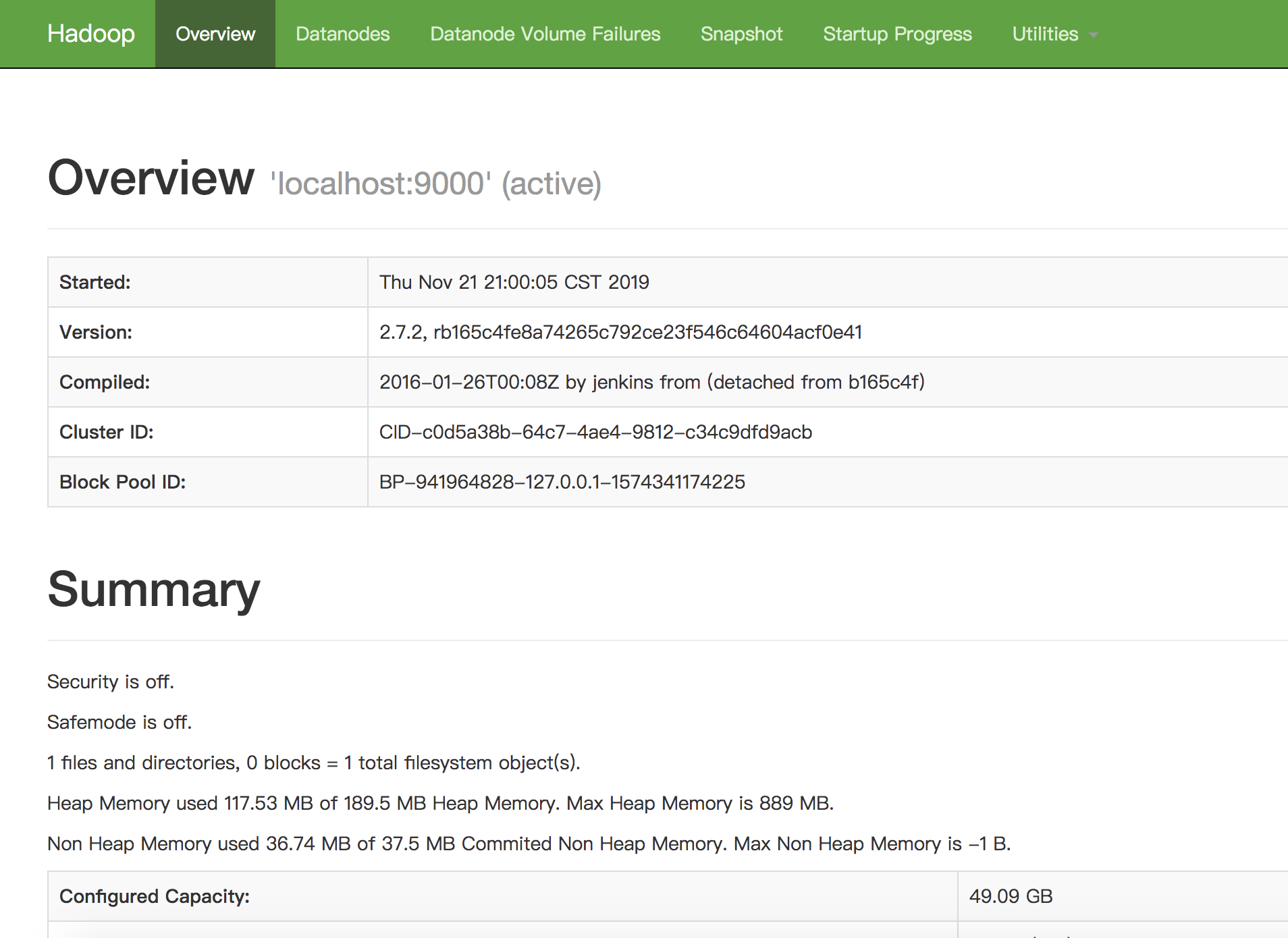
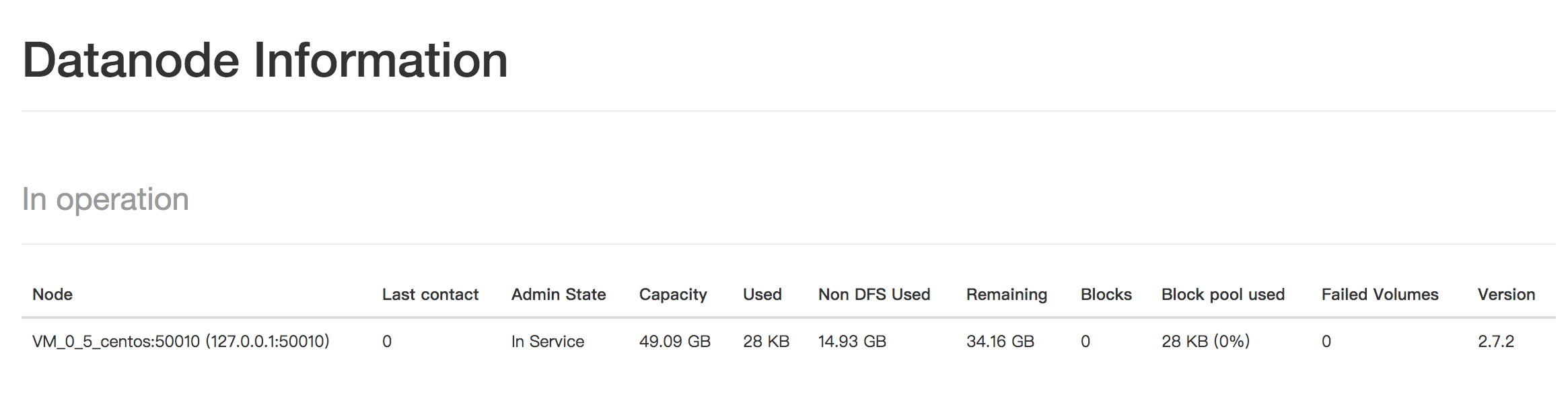
启动Yarn
配置etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动 ResourceManager daemon and NodeManager daemon:
sbin/start-yarn.sh
打开资源管理的web页面,http://localhost:8088/
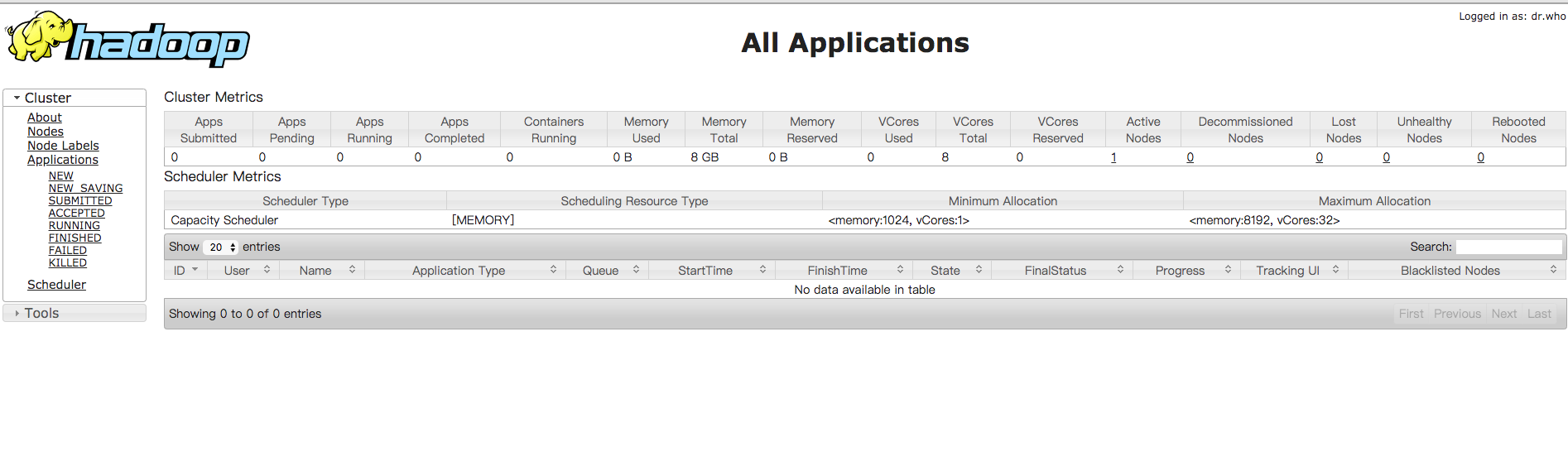
问题解决
每次启动HDFS,都必须格式化,才能启动NameNode
原因是,配置HDFS时,只配置了DataNode目录,没有配置NameNode相关信息。默认的tmp文件每次重新开机都会被清空,导致集群找不到NameNode信息,所以需要每次都重新格式化。
解决方法:
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/Hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
参考文档
Hadoop官网-Hadoop: Setting up a Single Node Cluster
Hadoop官网2.7.3
《Hadoop权威指南》
尚硅谷大数据之Hadoop
运行第一个MapReduce程序
MapReduce过程详解(基于hadoop2.x架构)
Hadoop(一)—— 启动与基本使用的更多相关文章
- Hadoop的启动和停止说明
Hadoop的启动和停止说明 sbin/start-all.sh 启动所有的Hadoop守护进程.包括NameNode. Secondary NameNode.DataNode.ResourceM ...
- 虚拟机搭建和安装Hadoop及启动
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 使用root配置的hadoop并启动会出现报错
1.使用root配置的hadoop并启动会出现报错 错误: Starting namenodes on [master] ERROR: Attempting to op ...
- hadoop datanode启动失败
问题导读: 1.Hadoop出现问题时,该如何入手查看问题?2.datanode无法启动,我们该怎么解决?3.如何动态加入DataNode或TaskTracker? 一.问题描述当我多次格式化文件系统 ...
- hadoop namenode启动过程详细剖析及瓶颈分析
NameNode中几个关键的数据结构 FSImage Namenode 会将HDFS的文件和目录元数据存储在一个叫fsimage的二进制文件中,每次保存fsimage之后到下次保存之间的所有hdfs操 ...
- Hadoop--有关Hadoop的启动
这里我们已经安装好Hadoop,并且已经配置好了环境变量. 安装相关文章:http://blog.csdn.net/gaopeng0071/article/details/10216303 参考网站: ...
- hadoop datanode 启动出错
FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block po ...
- Hadoop 配置文件 & 启动方式
配置文件: 默认的配置文件:相对应的jar 中 core-default.xml hdfs-default.xml yarn-default.xml mapred-default.xml 自定义配置文 ...
- Hadoop在启动时的坑——start-all.sh报错
1.若你用的Linux系统是CentOS的话,这是一个坑: 它会提示你JAVA_HOME找不到,现在去修改文件: .修改hadoop配置文件,手动指定JAVA_HOME环境变量 [${hadoop_h ...
随机推荐
- Part_four:redis主从复制
redis主从复制 1.redis主从同步 Redis集群中的数据库复制是通过主从同步来实现的 主节点(Master)把数据分发从节点(slave) 主从同步的好处在于高可用,Redis节点有冗余设计 ...
- 重置文件reset
body { margin:0; padding:0; font-family: Helvetica, STHeiti, Droid Sans Fallback; // font-family: '微 ...
- Springboot默认定时任务——Scheduled注解
1.pom配置 <dependencies> <dependency> <groupId>org.springframework.boot</groupId& ...
- layui 单选框、复选框、下拉菜单 不显示问题 记录
1. 如果是 ajax嵌套了 页面, 请确保 只有最外层的页面引入了 layui.css 和 layui.js 内层页面 切记不要再次引入 2. layui.use(['form', 'upload ...
- Spring Boot 笔记 (2) - 使用 log4j2 记日志
日志框架的选用 Spring 使用的默认日志框架是 logback, 默认情况下会采取默认的 autoconfiguration; 即便想对日志的一些配置进行修改也比较方便, 详细可以参考: Spri ...
- three.js展示三维模型
1.概要 最近学习Three.js,尝试加载一些3d max导出的obj.stl模型,在展示模型的时候遇到了一些问题,模型的尺寸.位置和旋转角度每次都靠手工调整,非常的不方便,就想着写一个方法来随心所 ...
- c#版本23个设计模式
一.引言 对设计模式的学习,自己的感触还是很多的,因为我现在在写代码的时候,经常会想想这里能不能用什么设计模式来进行重构.所以,学完设计模式之后,感觉它会慢慢地影响到你写代码的思维方式.这里对设计模式 ...
- abp学习(三)——文档翻译一
地址:https://aspnetboilerplate.com/Pages/Documents 什么是ASP.NET样板?ASP.NET Boilerplate(ABP)是一个开放源代码且文档齐全的 ...
- Dubbo源码分析(1):Spring集成Dubbo
spring与dubbo事件 类图
- C# 接收C++ dll 可变长字节或者 字符指针 char*
网络上查找到的几乎都是 需要提前固定知道 接收字符(字节)数据的大小的方式,现在的数据大小方式 不需要提前知道如下 思路: 1 .C++,返回变长 指针或者字节 的地址给C# 接收,同时返回 该地址的 ...