SQLite入门与分析(二)---设计与概念(续)
SQLite入门与分析(二)---设计与概念(续)
写在前面:本节讨论事务,事务是DBMS最核心的技术之一.在计算机科学史上,有三位科学家因在数据库领域的成就而获ACM图灵奖,而其中之一Jim Gray(曾任职微软)就是因为在事务处理方面的成就而获得这一殊荣,正是因为他,才使得OLTP系统在随后直到今天大行其道.关于事务处理技术,涉及到很多,随便就能写一本书.在这里我只讨论SQLite事务实现的一些原理,SQLite的事务实现与大型通用的DBMS相比,其实现比较简单.这些内容可能比较偏于理论,但却不难,也是理解其它内容的基础.好了,下面开始第二节---事务.
2、 事务(Transaction)
2.1、事务的周期(Transaction Lifecycles)
程序与事务之间有两件事值得注意:
(1) 哪些对象在事务下运行——这直接与API有关。
(2) 事务的生命周期,即什么时候开始,什么时候结束以及它在什么时候开始影响别的连接(这点对于并发性很重要)——这涉及到SQLite的具体实现。
一个连接(connection)可以包含多个(statement),而且每个连接有一个与数据库关联的B-tree和一个pager。Pager在连接中起着很重要的作用,因为它管理事务、锁、内存缓存以及负责崩溃恢复(crash recovery)。当你进行数据库写操作时,记住最重要的一件事:在任何时候,只在一个事务下执行一个连接。这些回答了第一个问题。
一般来说,一个事务的生命和statement差不多,你也可以手动结束它。默认情况下,事务自动提交,当然你也可以通过BEGIN..COMMIT手动提交。接下来就是锁的问题。
2.2、锁的状态(Lock States)
锁对于实现并发访问很重要,而对于大型通用的DBMS,锁的实现也十分复杂,而SQLite相对较简单。通常情况下,它的持续时间和事务一致。一个事务开始,它会先加锁,事务结束,释放锁。但是系统在事务没有结束的情况下崩溃,那么下一个访问数据库的连接会处理这种情况。
在SQLite中有5种不同状态的锁,连接(connection)任何时候都处于其中的一个状态。下图显示了相应的状态以及锁的生命周期。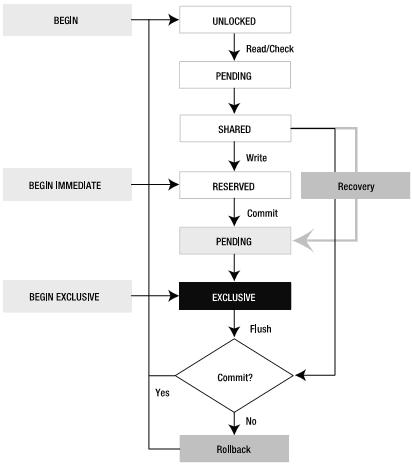
关于这个图有以下几点值得注意:
(1) 一个事务可以在UNLOCKED,RESERVED或EXCLUSIVE三种状态下开始。默认情况下在UNLOCKED时开始。
(2) 白色框中的UNLOCKED, PENDING, SHARED和 RESERVED可以在一个数据库的同一时存在。
(3) 从灰色的PENDING开始,事情就变得严格起来,意味着事务想得到排斥锁(EXCLUSIVE)(注意与白色框中的区别)。
虽然锁有这么多状态,但是从体质上来说,只有两种情况:读事务和写事务。
2.3、读事务(Read Transactions)
我们先来看看SELECT语句执行时锁的状态变化过程,非常简单:一个连接执行select语句,触发一个事务,从UNLOCKED到SHARED,当事务COMMIT时,又回到UNLOCKED,就这么简单。
考虑下面的例子(为了简单,这里用了伪码):
db = open('foods.db')
db.exec('BEGIN')
db.exec('SELECT * FROM episodes')
db.exec('SELECT * FROM episodes')
db.exec('COMMIT')
db.close()
由于显式的使用了BEGIN和COMMIT,两个SELECT命令在一个事务下执行。第一个exec()执行时,connection处于SHARED,然后第二个exec()执行,当事务提交时,connection又从SHARED回到UNLOCKED状态,如下:
UNLOCKED→PENDING→SHARED→UNLOCKED
如果没有BEGIN和COMMIT两行时如下:
UNLOCKED→PENDING→SHARED→UNLOCKED→PENDING→ SHARED→UNLOCKED
2.4、写事务(Write Transactions)
下面我们来考虑写数据库,比如UPDATE。和读事务一样,它也会经历UNLOCKED→PENDING→SHARED,但接下来却是灰色的PENDING,
2.4.1、The Reserved States
当一个连接(connection)向数据库写数据时,从SHARED状态变为RESERVED状态,如果它得到RESERVED锁,也就意味着它已经准备好进行写操作了。即使它没有把修改写入数据库,也可以把修改保存到位于pager中缓存中(page cache)。
当一个连接进入RESERVED状态,pager就开始初始化恢复日志(rollback journal)。在RESERVED状态下,pager管理着三种页面:
(1) Modified pages:包含被B-树修改的记录,位于page cache中。
(2) Unmodified pages:包含没有被B-tree修改的记录。
(3) Journal pages:这是修改页面以前的版本,这些并不存储在page cache中,而是在B-tree修改页面之前写入日志。
Page cache非常重要,正是因为它的存在,一个处于RESERVED状态的连接可以真正的开始工作,而不会干扰其它的(读)连接。所以,SQLite可以高效的处理在同一时刻的多个读连接和一个写连接。
2.4.2 、The Pending States
当一个连接完成修改,就真正开始提交事务,执行该过程的pager进入EXCLUSIVE状态。从RESERVED状态,pager试着获取PENDING锁,一旦得到,就独占它,不允许任何其它连接获得PENDING锁(PENDING is a gateway lock)。既然写操作持有PENDING锁,其它任何连接都不能从UNLOCKED状态进入SHARED状态,即没有任何连接可以进入数据(no new readers, no new writers)。只有那些已经处于SHARED状态的连接可以继续工作。而处于PENDING状态的Writer会一直等到所有这些连接释放它们的锁,然后对数据库加EXCUSIVE锁,进入EXCLUSIVE状态,独占数据库(讨论到这里,对SQLite的加锁机制应该比较清晰了)。
2.4.3、The Exclusive State
在EXCLUSIVE状态下,主要的工作是把修改的页面从page cache写入数据库文件,这是真正进行写操作的地方。
在pager写入modified pages之前,它还得先做一件事:写日志。它检查是否所有的日志都写入了磁盘,而这些通常位于操作的缓冲区中,所以pager得告诉OS把所有的文件写入磁盘,这是由程序synchronous(通过调用OS的相应的API实现)完成的。
日志是数据库进行恢复的惟一方法,所以日志对于DBMS非常重要。如果日志页面没有完全写入磁盘而发生崩溃,数据库就不能恢复到它原来的状态,此时数据库就处于不一致状态。日志写入完成后,pager就把所有的modified pages写入数据库文件。接下来就取决于事务提交的模式,如果是自动提交,那么pager清理日志,page cache,然后由EXCLUSIVE进入UNLOCKED。如果是手动提交,那么pager继续持有EXCLUSIVE锁和保存日志,直到COMMIT或者ROLLBACK。
总之,从性能方面来说,进程占有排斥锁的时间应该尽可能的短,所以DBMS通常都是在真正写文件时才会占有排斥锁,这样能大大提高并发性能。
SQLite入门与分析(二)---设计与概念(续)的更多相关文章
- SQLite入门与分析(二)---设计与概念
写在前面:谢谢各位的关注,没想到会有这么多人关注.高兴的同时,也感到压力,因为我接触SQLite也就几天,也没在实际开发中用过,只是最近项目的需求才来研究它,所以我很担心自己的文章是否会有错误,误导别 ...
- SQLite 入门教程(二)创建、修改、删除表 (转)
转于 SQLite 入门教程(二)创建.修改.删除表 一.数据库定义语言 DDL 在关系型数据库中,数据库中的表 Table.视图 View.索引 Index.关系 Relationship 和触发器 ...
- SQLite入门与分析(三)---内核概述(2)
写在前面:本节是前一节内容的后续部分,这两节都是从全局的角度SQLite内核各个模块的设计和功能.只有从全局上把握SQLite,才会更容易的理解SQLite的实现.SQLite采用了层次化,模块化的设 ...
- SQLite入门与分析(三)---内核概述(1)
写在前面:从本章开始,我们开始进入SQLite的内核.为了能更好的理解SQLite,我先从总的结构上讨论一下内核,从全局把握SQLite很重要.SQLite的内核实现不是很难,但是也不是很简单.总的来 ...
- SQLite入门与分析(一)---简介
写在前面:出于项目的需要,最近打算对SQLite的内核进行一个完整的剖析,在此希望和对SQLite有兴趣的一起交流.我知道,这是一个漫长的过程,就像曾经去读Linux内核一样,这个过程也将是辛苦的,但 ...
- SQLite入门与分析(四)---Page Cache之事务处理(1)
写在前面:从本章开始,将对SQLite的每个模块进行讨论.讨论的顺序按照我阅读SQLite的顺序来进行,由于项目的需要,以及时间关系,不能给出一个完整的计划,但是我会先讨论我认为比较重要的内容.本节讨 ...
- SQLite入门与分析(八)---存储模型(2)
3.页面结构(page structure) 数据库文件分成固定大小的页面.SQLite通过B+tree模型来管理所有的页面.页面(page)分三种类型:要么是tree page,或者是overflo ...
- SQLite入门与分析(七)---浅谈SQLite的虚拟机
写在前面:虚拟机技术在现在是一个非常热的技术,它的历史也很悠久.最早的虚拟机可追溯到IBM的VM/370,到上个世纪90年代,在计算机程序设计语言领域又出现一件革命性的事情——Java语言的出现,它与 ...
- SQLite 入门教程(二)创建、修改、删除表
一.数据库定义语言 DDL 在关系型数据库中,数据库中的表 Table.视图 View.索引 Index.关系 Relationship 和触发器 Trigger 等等,构成了数据库的架构 Schem ...
随机推荐
- Remote Desktop Organizer远程桌面管理软件的基本使用和介绍
<Remote Desktop Organizer>是一款用于远程桌面管理的软件.软件支持windows平台运行. Remote Desktop Organizer 是一款 Windows ...
- JQ批量控制form禁用
<script type="text/javascript" src="http://www.joy-city.com.cn/templets/default/sc ...
- 关于html的下载功能
新项目基本告一段落,第一次完成前后端分离的集成,遇到的坑自然不少. 来说说第一天遇到的其中一个坑吧. ——关于下载的问题... 以前的做法,大家都喜爱用<a></a>标签吧.而 ...
- PhantomJS实现最简单的模拟登录方案
以前写爬虫,遇到需要登录的页面,一般都是通过chrome的检查元素,查看登录需要的参数和加密方法,如果网站的加密非常复杂,例如登录qq的,就会很蛋疼 在后面,有了Pyv8,就可以把加密的js文件扔给它 ...
- PAT乙级真题1002. 写出这个数 (20)(解题)
读入一个自然数n,计算其各位数字之和,用汉语拼音写出和的每一位数字. 输入格式:每个测试输入包含1个测试用例,即给出自然数n的值.这里保证n小于10100. 输出格式:在一行内输出n的各位数字之和的每 ...
- AJAX 原理(转摘)
在写这篇文章之前,曾经写过一篇关于AJAX技术的随笔,不过涉及到的方面很窄,对AJAX技术的背景.原理.优缺点等各个方面都很少涉及null.这次写这篇文章的背景是因为公司需要对内部程序员做一个培训.项 ...
- Eclipse中propedit插件安装(解决property中文问题)
Eclipse Help--Install New Software... Add... propedit -- http://propedit.sourceforge.jp/eclipse/up ...
- (转)《深入理解java虚拟机》学习笔记7——Java虚拟机类生命周期
C/C++等纯编译语言从源码到最终执行一般要经历:编译.连接和运行三个阶段,连接是在编译期间完成,而java在编译期间仅仅是将源码编译为Java虚拟机可以识别的字节码Class类文件,Java虚拟机对 ...
- 在一个工程管理多个应用-b
Demo:http://download.csdn.net/detail/u012881779/9166527 本文的产生是因产品经理提出的特殊需求: 一个针对多所学校的应用,对不同学校需要分别使用一 ...
- VS 2005部署应用程序提示“应用程序无法正常启动( 0x0150002)” 解决方案
遇到这个问题,一定是缺少了CRT.MFC.ATL的DLL,不同版本的VS是不一样的.系统自带这些库的Release版,如果没有自带,打补丁就有了:系统不自带这些库的Debug版,所以Debug版的程序 ...