3.资源调度框架yarn
既然要分析yarn,无非是从以下方面分析
(一).yarn产生背景
(二).yarn概述
(三).yarn架构
(四).yarn执行流程
(五).yarn环境搭建
(六).提交作业到yarn上运行
(一).yarn产生的背景
1.在Mapreduce1.x版本中,单点故障以及节点压力大不容易扩展
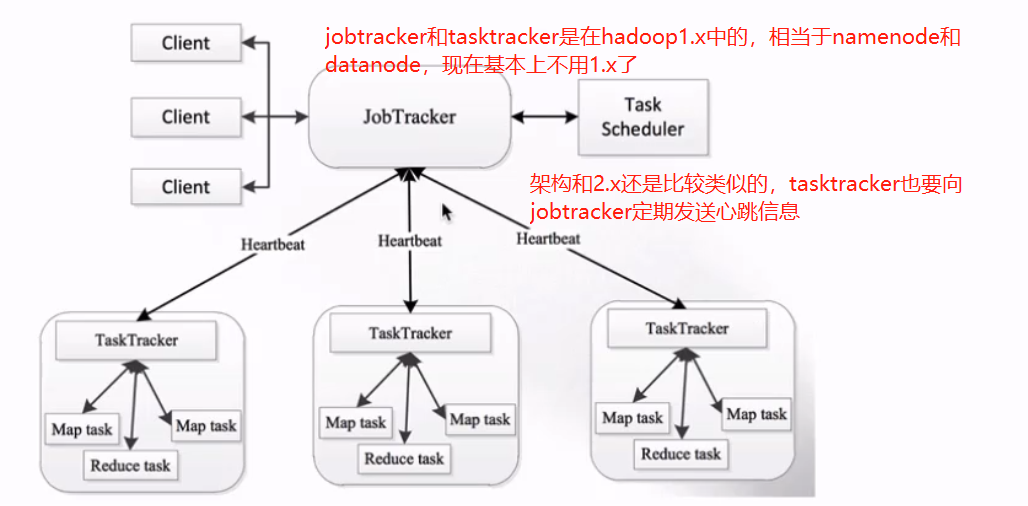
而且这种架构只支持MapReduce,像spark就无法支持
2.资源利用率低,以及运维成本高
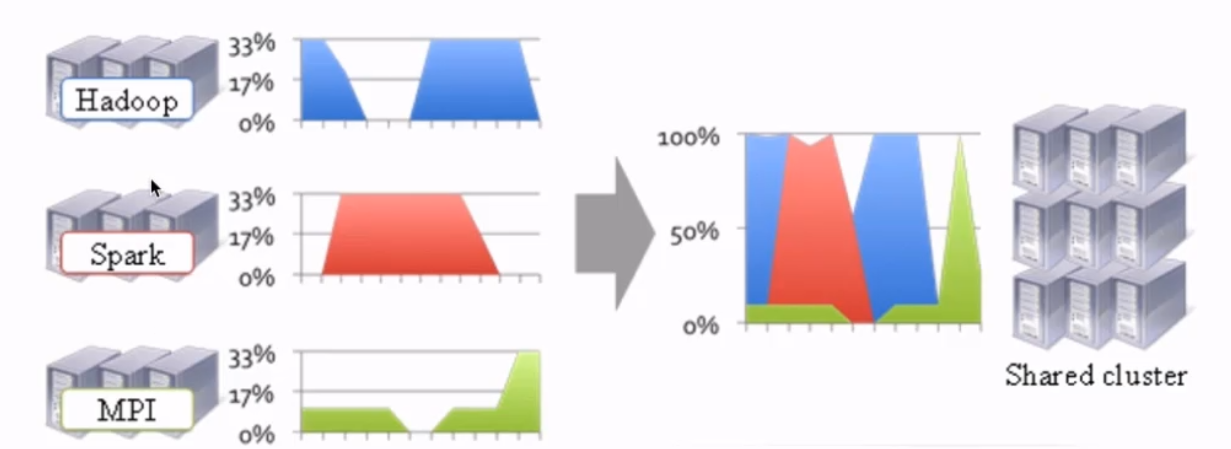
可以看到多个集群之间空闲比较多,资源利用率低,并且集群之间资源无法共享。hadoop空闲的时候无法给spark用,并且如果spark相对hadoop上的数据进行操作,需要跨网络把hadoop上的数据移过来,这个消耗是非常大的。那么能不能有一种模式,在一个集群上面运行hadoop,spark等等,共享一个集群的资源,这样肯定能大大减少数据移动所带来的成本,提高资源的利用率
以上原因便促使了yarn的诞生
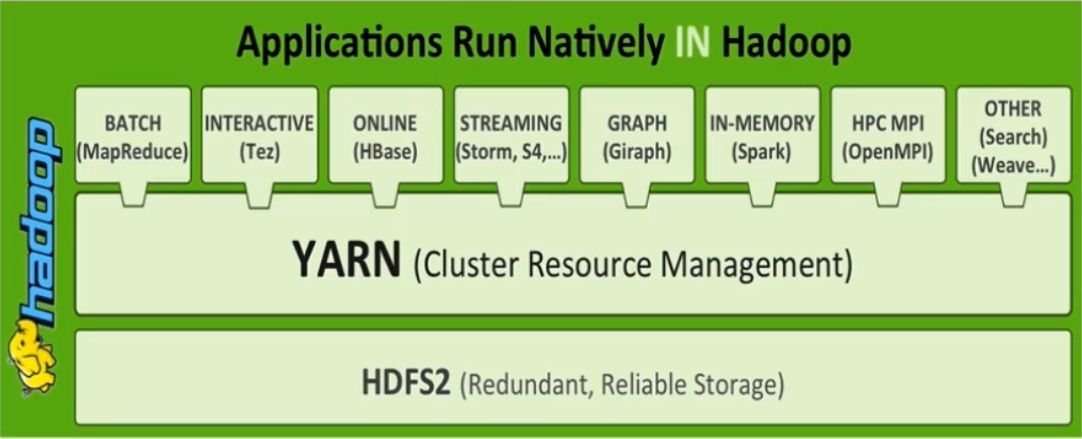
可以看到在有了yarn之后,可以支持很多计算框架。在hadoop1.x的时候,只支持MapReduce,但是2.x有了yarn之后,可以支持各种不同的计算框架,并且这些框架共享一个hdfs里的所有资源。我们可以把yarn想象成一个操作系统级别的资源调度框架,可以让更多不同的计算框架运行在同一个集群里面,享受整体的资源调度。
我们也常常听到xxx on yarn,这里的xxx可以使spark,MapReduce,storm,flink。这样的好处就在于与其他框架共享集群资源,按资源需要分配,进而提高集群资源的利用率
(二).yarn的概述
yarn是一个通用的资源管理系统,为上层应用提供统一的资源管理和调度
(三).yarn的架构
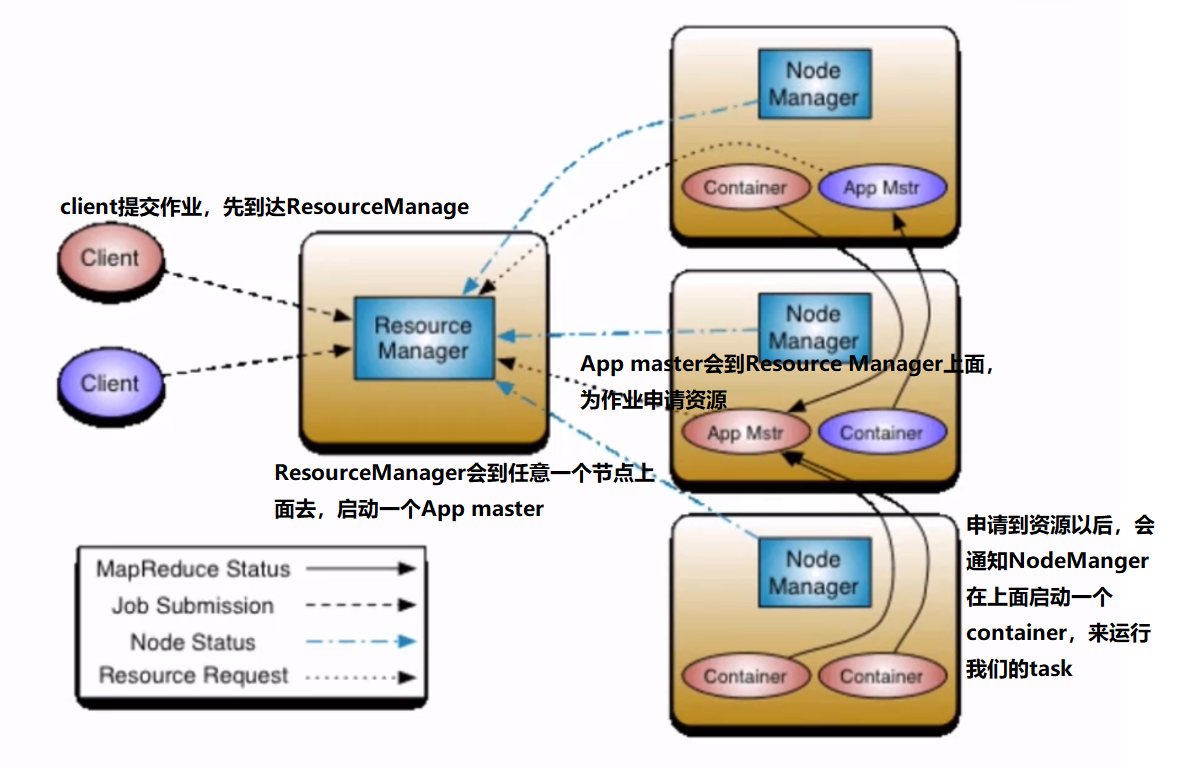
1)ResourceManager:RM
整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求:提交一个作业,杀死一个作业
监控NodeManager,一旦某个NM挂掉了,那么在该NM上运行的任务需要告诉我们的ApplicationMaster,来如何进行处理
2)NodeManager:NM
整个集群中有多个,负责自己本身节点的资源管理和使用
定时向RM汇报节点的资源使用情况
接收并处理来自RM的各种命令:启动container
处理来自AM的命令
单个节点的资源管理
3)ApplicationMaster:AM
每个应用程序对应一个AM,比如,MapReduce,spark,AM负责应用程序的管理
为应用程序申请资源(core,memory),分配给内部的task
需要与NM通信:启动/停止task。
task是运行在container里面的,AM也是
4)Container
封装了CPU,memory等资源的容器
是任务运行环境的一个抽象
5)Client
提交作业
查询作业的运行进度
杀死作业
(四).yarn的执行流程
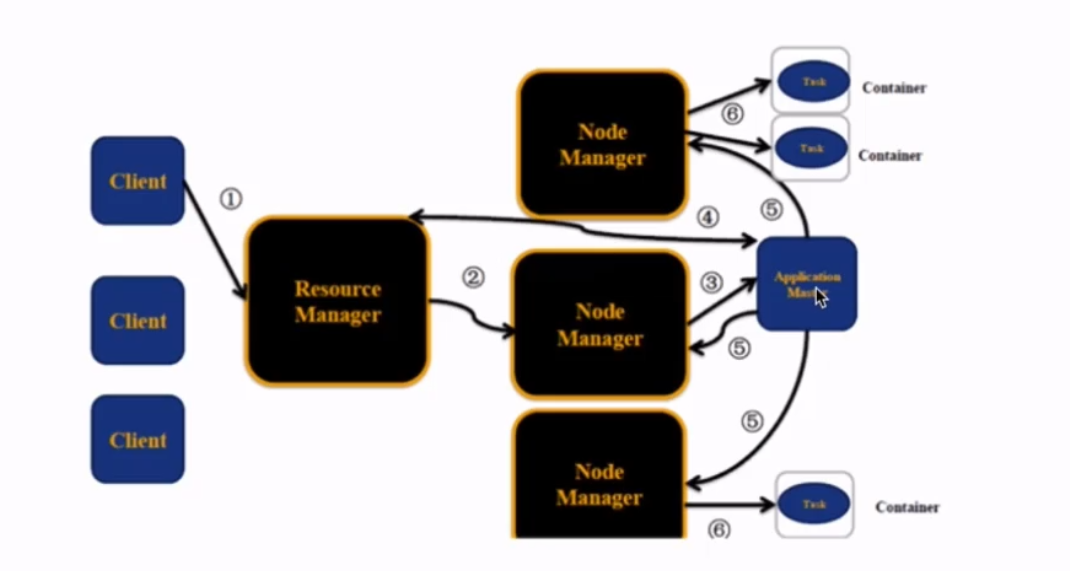
用户向yarn提交一个作业,比如一个MapReduce作业,spark作业。
那么RM会为作业分配第一个container,假设运行在第二个节点上面。RM就会与对应的NM进行通信,要求在该NM上面启动一个container,这个container是用来启动AM的。然后AM会到RM上进行一个注册。然后client就可以直接通过RM来查询作业的运行情况了
然后AM会将你作业所需要的core,memory来向RM申请,所以第四个箭头是来回的,双向的
然后AM在对应的NM上启动container,运行task
(五).yarn环境搭建
yarn并不需要单独下载,只需要修改两个配置文件即可。
yarn-site.xml
mapred-site.xml
配置文件仍然在etc/hadoop下面
1.修改mapred-site.xml
但是你会发现没有这个文件,倒是有mapred-site.xml.template这个文件,我们需要拷贝一份,然后把名称改成mapred-site.xml

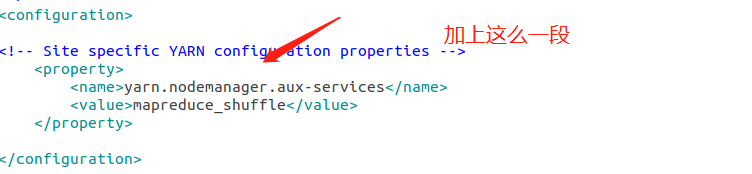
2.修改yarn-site.xml
3.启动yarn相关的进程
sbin/start-yarn.sh
4.验证
可以通过jps,也可以通过浏览器访问http://localhost:8088

启动成功

jps显示多了两个进程
我们也可以使用浏览器来访问,访问http://local:8088,或者http://ubuntu:8088,因为我这里的主机名就叫ubuntu
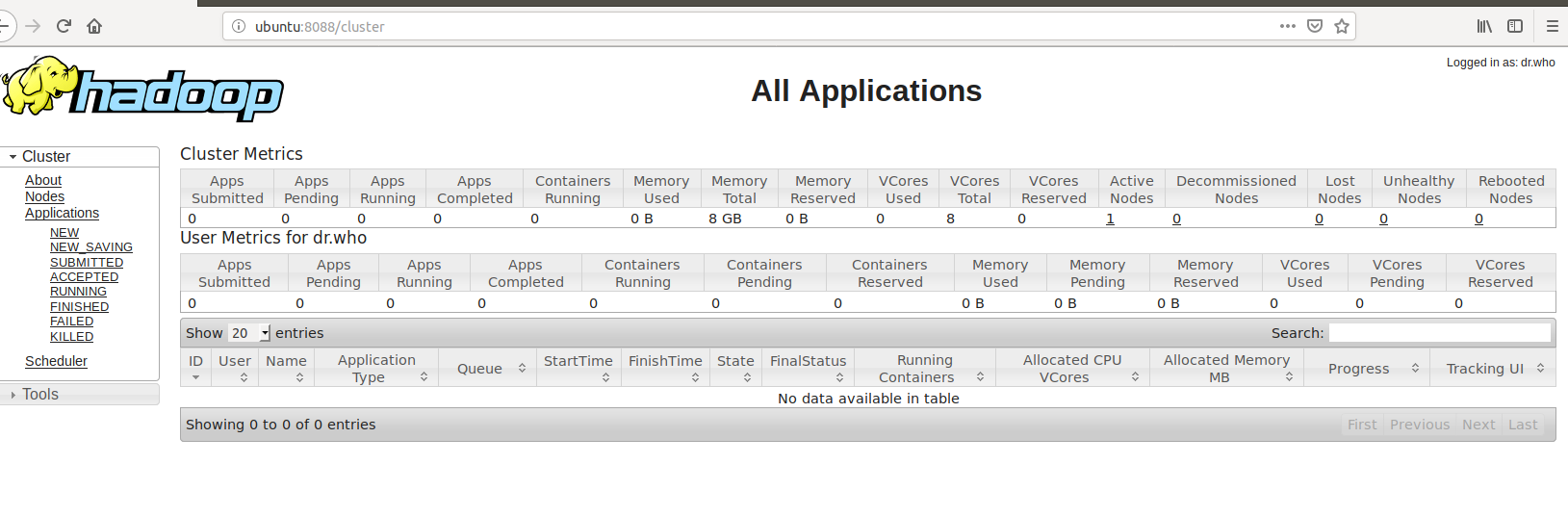
我们集群的详细信息都显示了出来
5.停止yarn
sbin/stop-yarn.sh
(六).提交作业到yarn上运行
我们还没有介绍MapReduce,后面会介绍,但是我们之前说了,hadoop为我们提供了一个测试用例,名字带example的那个
/usr/local/hadoop-cdh/hadoop-2.6.0-cdh5.8.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.8.5.jar

这个包的使用方法,输入hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.8.5.jar会有提示
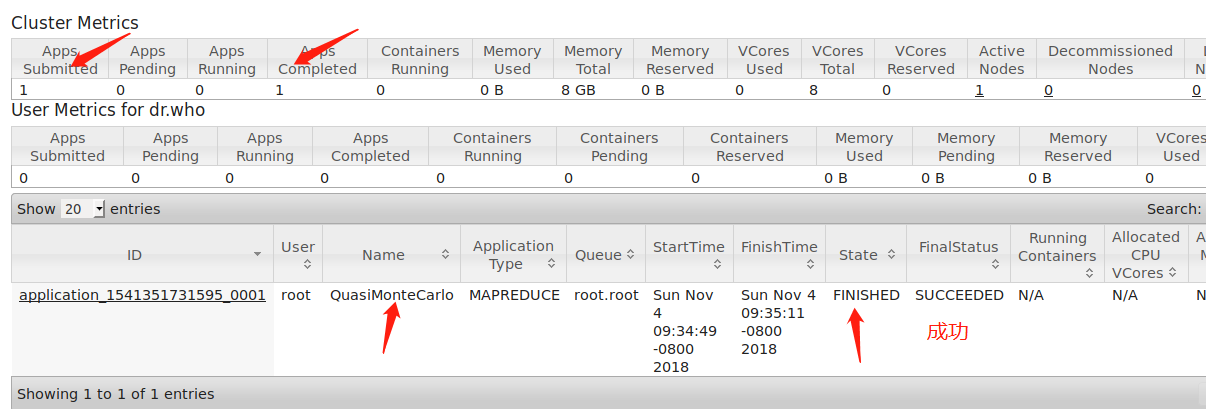
我这里输入的是hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.8.5.jar pi 2 3,我们来通过浏览器看看结果
3.资源调度框架yarn的更多相关文章
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- Yarn 资源调度框架
Yarn 资源调度框架 实现对资源的细粒度封装(cpu,内存,带宽) 此外,还可以通过yarn协调多种不同计算框架(MR,Spark) 概述 Apache Hadoop ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- Android系统“资源调度框架”
Android系统"资源调度框架" 目录 Android系统"资源调度框架" 一.一些问题的思考 "资源"是什么 "资源" ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装
实验目的 复习配置hadoop初始化环境 复习配置hdfs的配置文件 学会配置hadoop的配置文件 了解yarn的原理 实验原理 1.yarn是什么 前面安装好了hdfs文件系统,我们可以根据需求进 ...
- 大数据框架-YARN
YARN(Yet Another Resource Negotiator): 是一种新的 Hadoop 资源管理器 [ResourceManager:纯粹的调度器,基于应用程序对资源的需求进行调度的, ...
- Hadoop框架:Yarn基本结构和运行原理
本文源码:GitHub·点这里 || GitEE·点这里 一.Yarn基本结构 Hadoop三大核心组件:分布式文件系统HDFS.分布式计算框架MapReduce,分布式集群资源调度框架Yarn.Ya ...
随机推荐
- 合规P2P平台成PE/VC新宠
013年是互联网金融元年,余额宝.百发等掀起了大众理财的新一轮高潮.P2P平台作为互联网金融模式之一,也受到市场的重点关注-在部分平台不断爆出风险事件的同时,业内较为成熟的平台也正成为PE/VC的新宠 ...
- java rmi浅谈
首先比较下RPC和RMI的差别: 首先java提供了RMI的api,jdk1.5之后虚拟机自动生成两个类:存根类stub和骨架类skelton. stub是给客户端的,当客户端调用远程对象的一个方法时 ...
- 【转】Virtual DOM
前言 React 好像已经火了很久很久,以致于我们对于 Virtual DOM 这个词都已经很熟悉了,网上也有非常多的介绍 React.Virtual DOM 的文章.但是直到前不久我专门花时间去学习 ...
- 关于react-redux中Provider、connect的解析
Provider 是什么 react-redux 提供的一个 React 组件 作用 把 store 提供给其子组件 //使用 redux 的 createStore 方法创建的一个 store co ...
- C#故事
C# 在腾讯的发展 <先定个小目标, 使用C# 开发的千万级应用> Xamarin 携程使用.Net技术 分布式高并发redis MQ dubbo kafka zookeeper
- bootsrap 上传插件fileinput 简单使用
1.安装 下载fileinput文件,载入对应的css+js文件,如下: <link href="css/bootstrap.min.css" rel="style ...
- Hadoop上配置Hbase数据库
已有环境: 1. Ubuntu:14.04.2 2.jdk: 1.8.0_45 3.hadoop:2.6.0 4.hBase:1.0.0 详细过程: 1.下载最新的Hbase,这里我下载的是hbase ...
- BZOJ3671 [Noi2014]随机数生成器 【贪心】
题目链接 BZOJ3671 题解 模拟题意生成矩阵贪心从小选择即可 每选择一个,就标记其左下右上矩阵 由于每次都是标记一个到边界的矩阵,所以一旦遇到标记过就直接退出即可,可以保证复杂度 还有就是空间和 ...
- BZOJ day1
十题击破 1051108811921432195119682242245624632761
- GROUP_CONCAT(expr)
This function returns a string result with the concatenated non-NULL values from a group. It returns ...