大数据架构之:Kafka
Kafka 是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可在廉价PC Server上搭建起大规模消息系统。Kafka具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费
Kakfa特点:
- 解耦:消息系统在处理过程中插入一个隐含、基于数据的接口层。
- 冗余:消息队列持久化,防止数据丢失。
- 扩展性:消息队列解耦处理过程,容易扩展处理过程。
- 可恢复性:处理过程失效,恢复后可继续处理。
- 顺序保证:消息队列保证顺序。Kafka保证一个Partition内消息有序。
- 异步通信:消息队列允许消息加入队列,等需要时再处理。
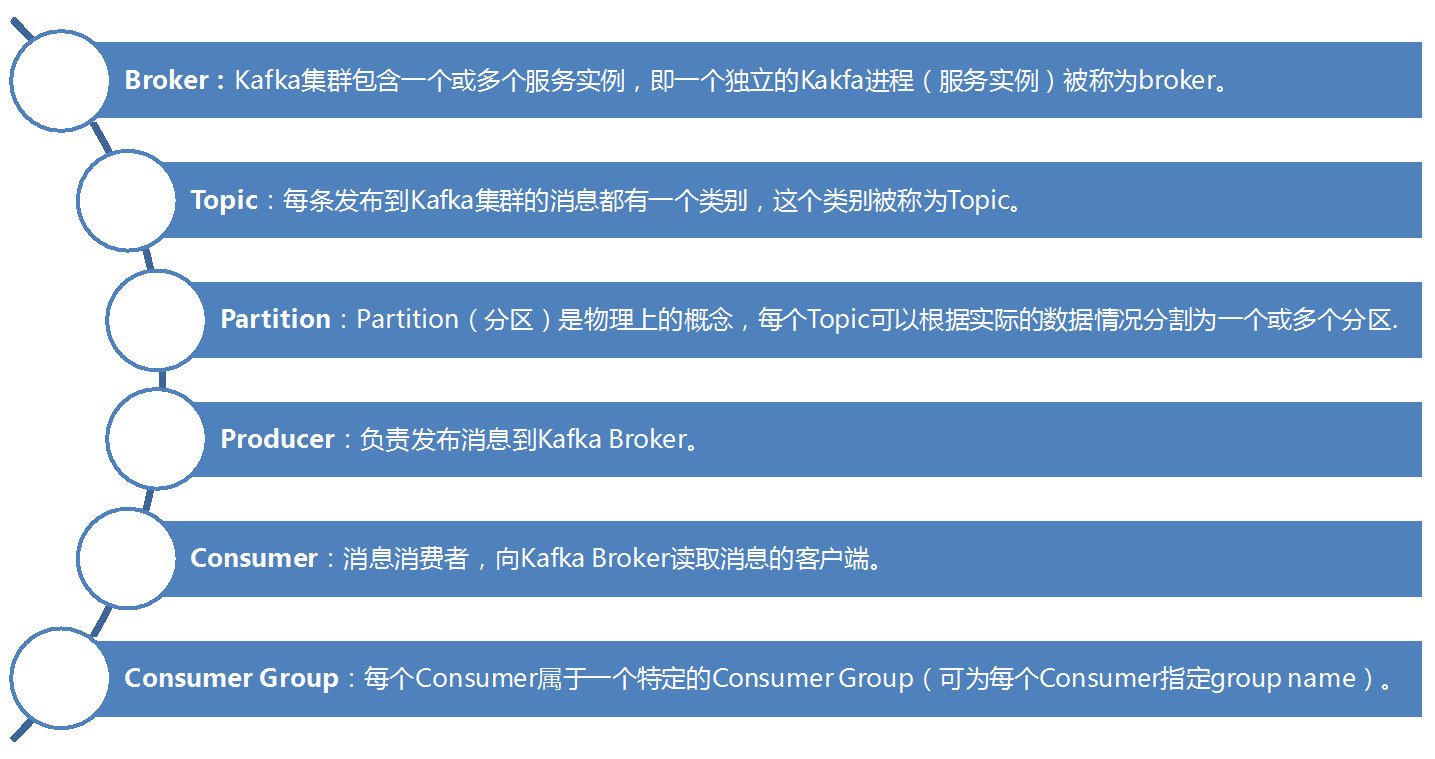
Kafka 的术语
Kafka 架构
典型Kafka架构
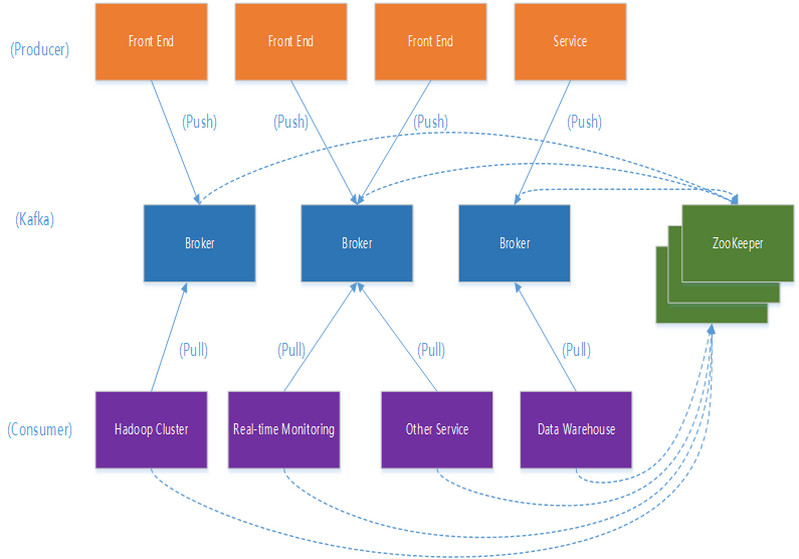
一个典型的Kafka集群中包含若干Producer(可以是web前端应用产生的消息,也可以是类似通过上网Flume收集上网日志产生的Events等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置及服务协同。Producer使用push模式将消息发布到broker,Consumer通过监听使用pull模式从broker订阅并消费消息。
多个broker协同合作,producer和consumer部署在各个业务逻辑中被频繁的调用,三者通过zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布和订阅系统就完成了。图上有个细节需要注意,producer刡broker的过程是push,也就是有数据就推送给broker,而consumer给broker的过程是pull,是通过consumer主动去拉数据的,而不是broker把数据主动发送给consumer端的。
producer、consumer、broker以及zookeeper返四者的关系
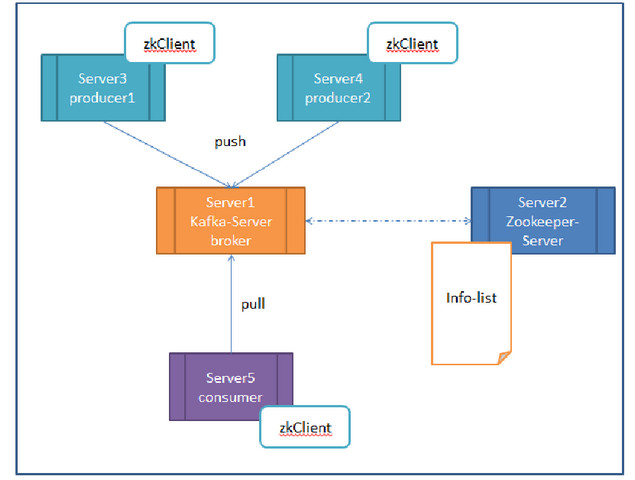
我们看上面的图,我们把broker的数量减少,叧有一台。现在假设我们按照上图进行部署:
Server-1 broker其实就是kafka的server,因为producer和consumer都要去连它。Broker主要还是做存储用。
Server-2是zookeeper的server端,zookeeper的具体作用你可以去上网查,在这里你可以先想象,它维持了一张表,记录了各个节点的IP、端口等信息(以后还会讲到,它里面还存了kafka的相关信息)。
Server-3、4、5他们的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置zookeeper的地址,道理也很简单,这之间的连接都是需要zookeeper来进行分发的。
Server-1和Server-2的关系,他们可以放在一台机器上,也可以分开放,zookeeper也可以配集群。目的是防止某一台挂了。
简单说下整个系统运行的顺序:
1. 启动zookeeper的server
2. 启动kafka的server
3. Producer如果生产了数据,会先通过zookeeper找到broker,然后将数据存放进broker
4. Consumer如果要消费数据,会先通过zookeeper找对应的broker,然后消费。
大数据架构之:Kafka的更多相关文章
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
随机推荐
- 如何设置esxi的网卡与网络
很多朋友安装了vmware esxi后,不懂得服务器上的网卡该如何设置以及如何使用,我们在这里来介绍一下vmware esxi的网卡设置 工具/原料 一台服务器,配有两块千兆网卡 在服务器安装好v ...
- plsql programming 12 集合(忽略, 个人感觉用不到)
关联数组, 嵌套表, varray 个人并不推荐使用集合, 因为操作有别于普通字段. 集合中每一个元素的数据类型都是相同的, 因此这些元素都是同质的(同质元素) 这一章的内容先忽略吧, 因为个人感觉用 ...
- marquee标签跑马灯连续无空白播放效果 纯CSS(chrome opera有效)
marquee似乎没有设置首尾相连播放的属性,内容滚动时总会留出一段marquee本身长度的空隙,某些情况下很不方便: 捣鼓了一会,得出一种解决办法,关键有两点: 1.将需要滚动的内容复制一份于同一行 ...
- 如何利用Emacs进行个人时间管理(GTD)
1. 简介 1.1 什么是GTD Get Things Done(GTD),是一套时间管理方法,面对生活中如下情况: 有很多事情要做 每件事情有主次之分 个人精力有限 我们需要随时很方便的了解我们下一 ...
- 第一百九十一节,jQuery EasyUI 入门
jQuery EasyUI 入门 学习要点: 1.什么是 jQuery EasyUI 2.学习 jQuery EasyUI 的条件 3.jQuery EasyUI 的功能和优势 4.其他的 UI 插件 ...
- [浪风JQuery开发]jquery最有意思的IFrame类似应用--值得深入研究
前几天一时兴起答应朋友的需求--做一个外国的企业网站: 本想做就做呗,可没想我辛辛苦苦用浪风认真php平台开发后,对方来一句我服务器不能安装其他程序,请给我用frame框架开发. 浪风那是一个苦字难言 ...
- Spring MVC生成RSS源
下面的示例演示如何使用Spring Web MVC框架生成RSS源. 首先使用Eclipse IDE,并按照以下步骤使用Spring Web Framework开发基于动态表单的Web应用程序: 创建 ...
- C# 6新特性简单总结
最近在看<C#高级编程 C# 6&.NET Core 1.0>,会做一些读书笔记,也算对知识的总结与沉淀了. 1.静态的using声明 静态的using声明允许调用静态方法时不使用 ...
- 42、使用存放在存assets文件夹下的SQLite数据库
因为这次的项目需要自带数据,所以就就把数据都放到一个SQLite的数据库文件中了,之后把该文件放到了assets文件夹下面.一开始打算每次都从assets文件夹下面把该文件夹拷贝到手机的SD卡或者手机 ...
- hdu2587(递推)
目前做过的最纠结的一道递推题. 情况比较多,比较复杂... 这题最主要的还是要推出当m=2 时和m>2时,用什么方法最优. 给个数据 n=3,m=2 需要48 n=3,m=3 需要81 如果 ...