大数据架构之:Kafka
Kafka 是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可在廉价PC Server上搭建起大规模消息系统。Kafka具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费
Kakfa特点:
- 解耦:消息系统在处理过程中插入一个隐含、基于数据的接口层。
- 冗余:消息队列持久化,防止数据丢失。
- 扩展性:消息队列解耦处理过程,容易扩展处理过程。
- 可恢复性:处理过程失效,恢复后可继续处理。
- 顺序保证:消息队列保证顺序。Kafka保证一个Partition内消息有序。
- 异步通信:消息队列允许消息加入队列,等需要时再处理。
Kafka 的术语
Kafka 架构
典型Kafka架构
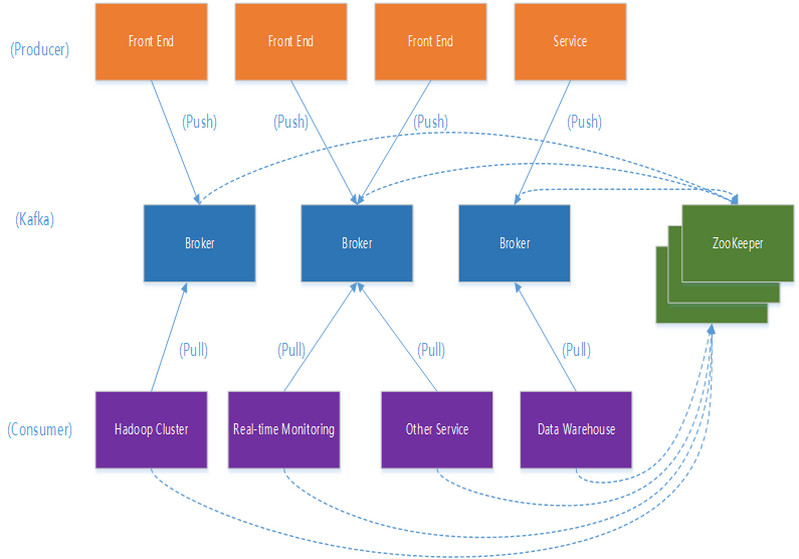
一个典型的Kafka集群中包含若干Producer(可以是web前端应用产生的消息,也可以是类似通过上网Flume收集上网日志产生的Events等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置及服务协同。Producer使用push模式将消息发布到broker,Consumer通过监听使用pull模式从broker订阅并消费消息。
多个broker协同合作,producer和consumer部署在各个业务逻辑中被频繁的调用,三者通过zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布和订阅系统就完成了。图上有个细节需要注意,producer刡broker的过程是push,也就是有数据就推送给broker,而consumer给broker的过程是pull,是通过consumer主动去拉数据的,而不是broker把数据主动发送给consumer端的。
producer、consumer、broker以及zookeeper返四者的关系
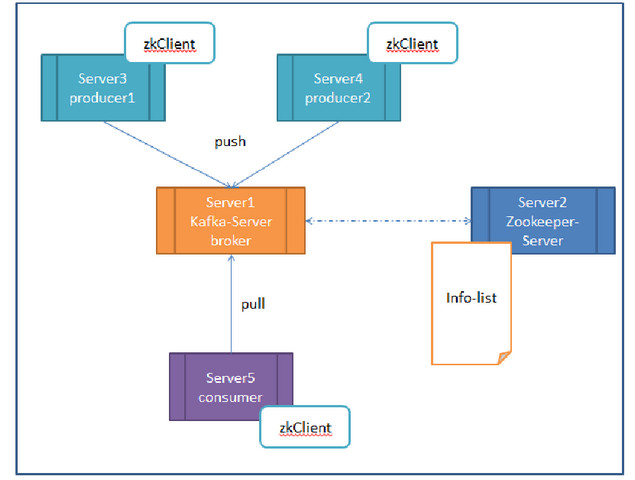
我们看上面的图,我们把broker的数量减少,叧有一台。现在假设我们按照上图进行部署:
Server-1 broker其实就是kafka的server,因为producer和consumer都要去连它。Broker主要还是做存储用。
Server-2是zookeeper的server端,zookeeper的具体作用你可以去上网查,在这里你可以先想象,它维持了一张表,记录了各个节点的IP、端口等信息(以后还会讲到,它里面还存了kafka的相关信息)。
Server-3、4、5他们的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置zookeeper的地址,道理也很简单,这之间的连接都是需要zookeeper来进行分发的。
Server-1和Server-2的关系,他们可以放在一台机器上,也可以分开放,zookeeper也可以配集群。目的是防止某一台挂了。
简单说下整个系统运行的顺序:
1. 启动zookeeper的server
2. 启动kafka的server
3. Producer如果生产了数据,会先通过zookeeper找到broker,然后将数据存放进broker
4. Consumer如果要消费数据,会先通过zookeeper找对应的broker,然后消费。
大数据架构之:Kafka的更多相关文章
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
随机推荐
- Linux 总结2
cd pwd mkdir ...
- printf,sprintf,vsprintf
printf,sprintf比较常用,vsprintf不常用. 1. 三个函数的声明: int printf (const char * szFormat, ...); int sprintf (ch ...
- Scrapy爬虫笔记
Scrapy是一个优秀的Python爬虫框架,可以很方便的爬取web站点的信息供我们分析和挖掘,在这记录下最近使用的一些心得. 1.安装 通过pip或者easy_install安装: 1 sudo p ...
- gitlab报错收集
登录502报错 一般是权限问题,解决方法: /var/log/gitlab 如果还不行,请检查你的内存,安装使用GitLab需要至少4GB可用内存(RAM + Swap)! 由于操作系统和其他正在运行 ...
- Codeforces 460 D. Little Victor and Set
暴力+构造 If r - l ≤ 4 we can all subsets of size not greater than k. Else, if k = 1, obviously that ans ...
- 怎样利用JDBC启动Oracle 自己主动追踪(auto trace)
有时我们须要对运行SQL的详细运行过程做一个追踪分析,特别是在应用程序性能优化的时候.Oracle两个工具能够帮助我们做好性能分析,一个是SQL_TRACE,一个是SESSION_EVENT.SQL_ ...
- Linux下IP等网络配置
Linux下IP等网络配置: 我所知道一共三种方式,下面简单介绍(注意:网络配置必须”root管理员“登录才能进行配置). 一 1.首先在命令行输入[ifconfig]命令,可看到相关网络信息,其中” ...
- activity通过流程实例id动态获取流程图并展示在jsp页面上
提供的Service方法如下: Java /** * 获取当前任务流程图 * * @param processInstanceId * @return */ @Override public Inpu ...
- 求割点模板(可求出割点数目及每个割点分割几个区域)POJ1966(Cable TV Network)
题目链接:传送门 题目大意:给你一副无向图,求解图的顶点连通度 题目思路:模板(图论算法理论,实现及应用 P396) Menger定理:无向图G的顶点连通度k(G)和顶点间最大独立轨数目之间存在如下关 ...
- Yue Fei's Battle(组合计数递推)
//求一个直径为 k 的树有多少种形态,每个点的度不超过 3 // 非常完美的分析,学到了,就是要细细推,并且写的时候要细心 还有除法取模需要用逆元 #include <iostream> ...