JAVA爬取亚马逊的商品信息
在程序里面输入你想爬取的商品名字,就可以返回这件商品在亚马逊搜索中都所有相关商品的信息,包括名字和价格。
解决了在爬取亚马逊时候,亚马逊可以识别出你的爬虫,并返回503,造成只能爬取几个页面的问题。
除此之外亚马逊网页代码写得非常的乱啊(可能是我个人问题?),要想提取里面的信息非常麻烦。
纯JAVA编写,用的都是java自带的库。
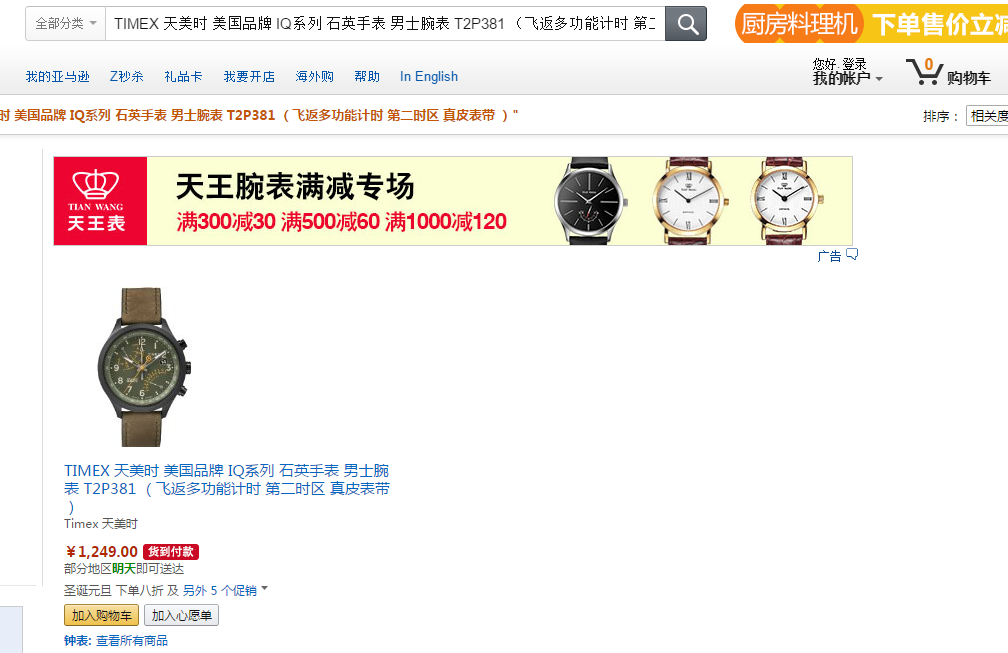
先展示一下效果图:
商品页面:

爬取的信息页面(消除重复了):

名字和价格是绝对正确的,例如上图31行的商品:
主要思路是这样的:
1、打开搜索的列表页,然后抽取所有商品页的url和下一页的url,加入爬取的队列。
2、判断若是列表页则重复步骤1,若是商品详细信息的页面,提取商品名称和价格到一个文件中。
遇到的主要问题:
1、亚马逊的页面限制流量,如果在限定的时间内访问次数太多,就会返回503。一般是爬取几张页面后就不能继续下去了。如图:

解决办法是:
a、尽量模仿浏览器,办法就是设置User-Agent啦!用一个数组存了 多个User-Agent,然后随机调用。
b、降速,适当延长两次请求的时间。
c、去重,重复的url
d、挂代理,这个就算了,太复杂
2、亚马逊的代码很乱!提取有用的信息十分困难。不过细心找还是能发现规律的,我用正则表达式来提取的。
亚马逊搜索页面的url(就是搜索商品后回车的页面):
"http://www.amazon.cn/s/ref=nb_sb_noss?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&field-keywords="+商品名;
对于商品页面的抽取,商品名字和价格的抽取等等在代码里面。
3、在列表里面会有同一件商品的3~4个url名字,可以跳转到名字部分,图文信息部分还有评论部分的。
要判断如果这些页面的商品编号相同,就只取一个就好了。例如:
http://www.amazon.cn/%E6%89%8B%E6%9C%BA-%E9%80%9A%E8%AE%AF/dp/B00OB5T26S......
dp后面是商品编号。
代码只爬取了搜索页的第一页,因为第一页的商品最贴近我们想要的东西,而且后面的页面很多都是重复的或者是不相关的了。
除了我们搜索一个品牌才会有很多页,一般搜索具体的东西还是第一页比较靠谱。当然,也可以爬取后面的页面啦,url在html中,自己提取就行。
public class amazon {
public static int i=0;
//用来储存上一个商品编号,看有没有重复
public static String last = "|";
//匹配商品url
public static Pattern p_goods = Pattern.compile("href=\"(http://www(.+?)/dp/(.+?))\"");
//存放待爬取的url
public static Queue<String> data = new LinkedList<String>();
//要输入到file中
public static File file;
//15个ua随机用,减少503的机率
public static String [] ua = {
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Intel Mac OS X 10.6; rv:7.0.1) Gecko/20100101 Firefox/7.0.1",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36 OPR/18.0.1284.68",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:7.0.1) Gecko/20100101 Firefox/7.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.9.1) Presto/2.12.388 Version/12.16",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36 OPR/18.0.1284.68",
"Mozilla/5.0 (iPad; CPU OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/30.0.1599.12 Mobile/11A465 Safari/8536.25",
"Mozilla/5.0 (iPad; CPU OS 8_0 like Mac OS X) AppleWebKit/600.1.3 (KHTML, like Gecko) Version/8.0 Mobile/12A4345d Safari/600.1.4",
"Mozilla/5.0 (iPad; CPU OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53"
};
public static void action(String target) throws IOException, InterruptedException{
//补全targer的搜索页面
if(i==0){
target = "http://www.amazon.cn/s/ref=nb_sb_noss?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&field-keywords="+target;
i++;
}
//先打开输入流
URL url = new URL(target);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setRequestMethod("GET");
Random index = new Random();
String u = ua[Math.abs(index.nextInt()%15)];
//System.out.println("us--->"+u);
//随机调用ua
conn.setRequestProperty("User-Agent",u);
conn.setRequestProperty("Host","www.amazon.cn");
conn.setRequestProperty("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
conn.setRequestProperty("Connection","keep-alive");
conn.connect();
InputStream in = conn.getInputStream();
byte [] buf = new byte[1024];
//把数据装进ByteArrayOutputStream中
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
int len = 0;
while((len=in.read(buf))!=-1){
outStream.write(buf,0,len);
}
in.close();
outStream.close();
String content = new String(outStream.toByteArray());
//判断页面类型
Pattern pp_goods = Pattern.compile("http://www(.+?)/dp/(.+)");
Matcher m_goods = pp_goods.matcher(target);
//如果是商品页面
if(m_goods.find()){
System.out.println("This is goods page");
//提取名字和价格
Pattern p_name = Pattern.compile("<meta name=\"description\" content=\"(.+?),");
Matcher m_name = p_name.matcher(content);
Pattern p_price = Pattern.compile("class=\"a-size-medium a-color-price\">¥(.+?)</span>");
Matcher m_price = p_price.matcher(content);
//文件写操作
PrintWriter pw = new PrintWriter(new FileWriter("goods.txt", true));
while(m_name.find()){
pw.print(m_name.group(1)+"------->");
}
while(m_price.find()){
pw.println(m_price.group(1));
}
pw.close();
}
//其他就是列表页面了
else{
//提取里面的商品url
m_goods = p_goods.matcher(content);
int count = 0;
//提取这个url的编号
Pattern p_num = Pattern.compile("/dp/(.+?)/");
while(m_goods.find()){
String current = m_goods.group(1);
Matcher m_num = p_num.matcher(current);
String current_num = "";
if(m_num.find()){
current_num = m_num.group(1);
//System.out.println(current_num);
}
//去重!!!!!!!!!
//如果不等于上一个商品编号,才将该url加入队列
if(!current_num.equals(last)){
//System.out.println(current);
//System.out.println(current_num);
//System.out.println("goods url");
data.add(current);
last = current_num;
}
}
}
}
public static void main(String args[]) throws IOException, InterruptedException{
//直接输入商品名字就好了
String target = "macbook pro";
amazon.action(target);
//如果队列非空,则一直进行
while(!data.isEmpty()){
amazon.action(data.poll());
}
}
}
效果:

才第一页就已经比较多无用的东西了,比如保护膜什么什么的。我一开始是爬取了很多页面的,但发现后面都是一些没用的东西,所以后面的页面意义不大。
其实真正高效的话,还是要用到多线程和一些去重技术,这里只是一个简单的实例。
JAVA爬取亚马逊的商品信息的更多相关文章
- 用scrapy爬取亚马逊网站项目
这次爬取亚马逊网站,用到了scrapy,代理池,和中间件: spiders里面: # -*- coding: utf-8 -*- import scrapy from scrapy.http.requ ...
- 如何使用代理IP进行数据抓取,PHP爬虫抓取亚马逊商品数据
什么是代理?什么情况下会用到代理IP? 代理服务器(Proxy Server),其功能就是代用户去取得网络信息,然后返回给用户.形象的说:它是网络信息的中转站.通过代理IP访问目标站,可以隐藏用户的真 ...
- 基于Java实现简单亚马逊爬虫
前言:最近博主买了台Kindle,感觉亚马逊上的图书资源质量挺好,还时不时地会有价格低但质量高的书出售,但限于亚马逊并没有很好的优惠提醒功能,自己天天盯着又很累.于是,我自己写了一个基于Java的亚马 ...
- 亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.亚马逊商品页面链接地址(本次要爬取的页面url) https://www.amazon.cn/dp/B07BSLQ65P/ 2.代码部分 import requestsurl = "ht ...
- 最新亚马逊 Coupons 功能设置教程完整攻略!
最新亚马逊 Coupons 功能设置教程完整攻略! http://m.cifnews.com/app/postsinfo/18479 亚马逊总是有新的创意,新的功能.最近讨论很火的,就是这个 Coup ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- 亚马逊首次推出卖家APP 可掌握商品盈利状况
美国零售巨头亚马逊近日首次对外发布了第一款针对卖家和商户的客户端,帮助他们更加高效的管理商品和销售数据. 据美国科技新闻网站 Mashable 报道,之前亚马逊在商户移动客户端方面一直空缺,许多商户不 ...
- 完全基于 Java 的开源深度学习平台,亚马逊的大佬带你上手
本文适合有 Java 基础的人群 作者:DJL-Lanking HelloGitHub 推出的<讲解开源项目>系列.有幸邀请到了亚马逊 + Apache 的工程师:Lanking( htt ...
- Android支付接入(八):Amazon亚马逊支付
下面跟大家一起走一遍Amazon亚马逊的支付,亚马逊目前刚把业务拓展到大陆市场,但这并不代表Amazon支付不成熟,恰恰相反,Amazon的支付流程,支付结果获取及测试另人称赞,支付流程.测试流程简洁 ...
随机推荐
- 《The Cg Tutorial》阅读笔记——光照 Lighting
本文为大便一箩筐的原创内容,转载请注明出处,谢谢:http://www.cnblogs.com/dbylk/p/4796306.html 光照 Lighting 一.常见的几种光照模型 二.基本的光照 ...
- 用Spring和c3p0工具简单的实现增删改查
1.导入Spring和c3p0的jar包 2.配置beans.xml文件 <?xml version="1.0" encoding="UTF-8"?> ...
- vs2013出现错误提示error C4996: 'strcpy': This function or variable may be unsafe. Consider using strcpy_s
这个问题是vs准备弃用strcpy带来的,因为觉得他不太安全 可以尝试在main函数前面加上#pragma warning(disable:4996)即可解决这个问题
- 如何在eclipse中安装ADT
打开Eclipse,点击 Help -> Install New Software: 点击Add: 然后点击Archive,添加对应的上面的ADT-21.0.1.zip: OK后,再写上一个名字 ...
- TeamTalk源码分析(十) —— 开放一个TeamTalk测试服务器地址和几个测试账号
由于TeamTalk是用于企业内部的即时通讯软件,一般客户端并不提供账号注册功能.如果你仅对TeamTalk的客户端感兴趣,你可以仅仅研究pc端和移动端代码.官方的测试服务器地址已经失效,所以我已经部 ...
- Android OpenCSV
OpenCSV https://sourceforge.net/projects/opencsv/ 使用参考 http://stackoverflow.com/questions/16672074/i ...
- Golang调用windows下的dll动态库中的函数
Golang调用windows下的dll动态库中的函数 使用syscall调用. package main import ( "fmt" "syscall" & ...
- python学习之面向对象(下)
该篇主要是针对面向对象的细讲,包括类的多重继承,方法的重写,析构函数,回收机制进行讲解 #该类主要是讲述python面象对象的一些特征,包括继承,方法的重写,多态,垃圾回收 class person( ...
- java编写创建数据库和表的程序
本文示例可见一斑了,主要是通过Java对SQL语句进行操作,和普通的增删改查的原理是一样的: import java.sql.*; public class Test { public static ...
- 如果有人问你ZooKeeper是什么,就把这篇文章发给他。
前言 提到ZooKeeper,相信大家都不会陌生.Dubbo,Kafka,Hadoop等等项目里都能看到它的影子.但是你真的了解 ZooKeeper 吗?如果面试官让你给他讲讲 ZooKeeper 是 ...