用python代码模拟登录网站
方法一:直接使用已知的cookie访问
特点:
简单,但需要先在浏览器登录
具体步骤:
1.用浏览器登录,获取浏览器里的cookie字符串
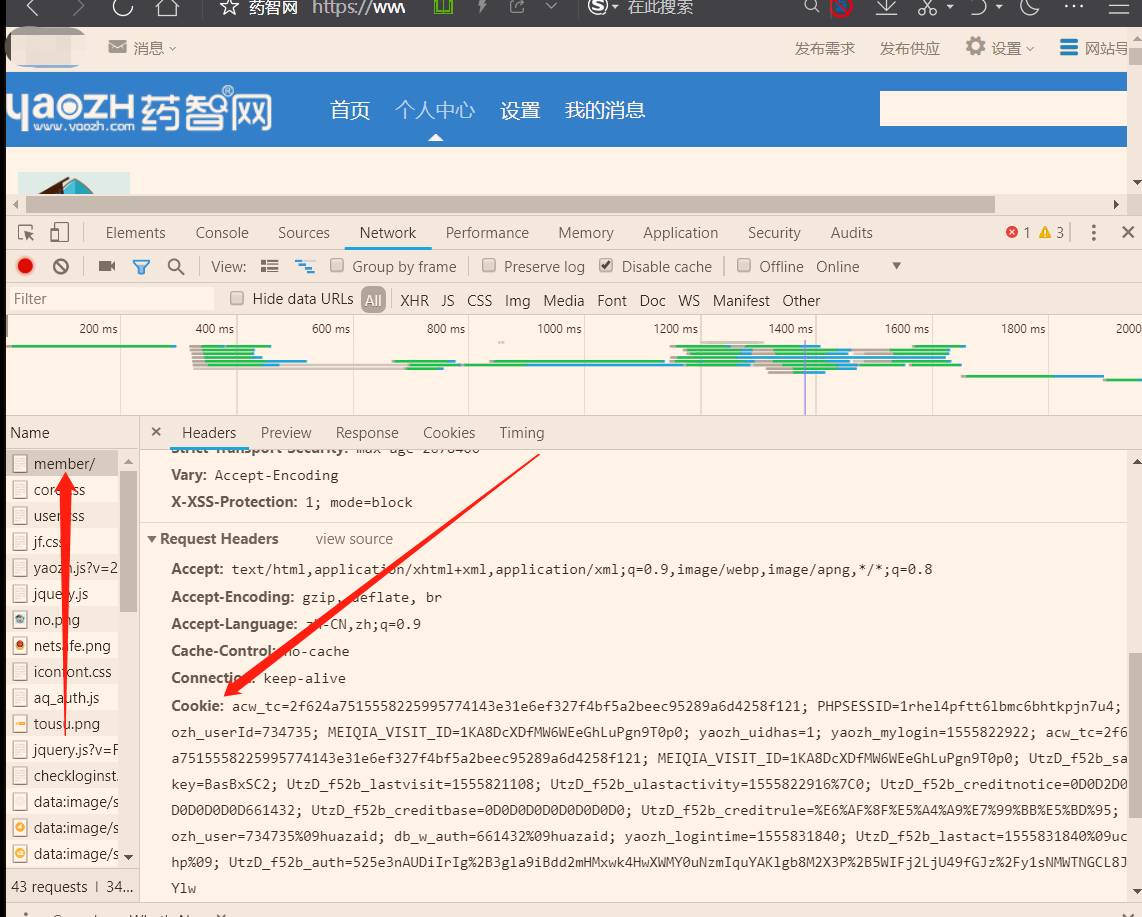
先使用浏览器登录。再打开开发者工具,转到network选项卡。在左边的Name一栏找到当前的网址,选择右边的Headers选项卡,查看Request Headers,这里包含了该网站颁发给浏览器的cookie。对,就是后面的字符串。把它复制下来,一会儿代码里要用到。
注意,最好是在运行你的程序前再登录。如果太早登录,或是把浏览器关了,很可能复制的那个cookie就过期无效了。
urllib库的版本代码
"""
直接获取 个人中心的页面
手动粘贴 辅助 pc 抓包的 cookies
放在 request对象的请求头里面
""" import urllib.request #1 数据url
url = "https://www.yaozh.com/member/"
#2 添加请求头
headers = {
"User-Agent":" Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3650.400 QQBrowser/10.4.3341.400"
,"Cookie":"acw_tc=2f624a7515558225995774143e31e6ef327f4bf5a2beec95289a6d4258f121; PHPSESSID=1rhel4pftt6lbmc6bhtkpjn7u4; yaozh_logintime=1555822916; yaozh_user=734735%09huazaid; yaozh_userId=734735; MEIQIA_VISIT_ID=1KA8DcXDfMW6WEeGhLuPgn9T0p0; yaozh_uidhas=1; yaozh_mylogin=1555822922; acw_tc=2f624a7515558225995774143e31e6ef327f4bf5a2beec95289a6d4258f121; MEIQIA_VISIT_ID=1KA8DcXDfMW6WEeGhLuPgn9T0p0"
}
#3 构建请求对象
request = urllib.request.Request(url,headers=headers)
#4 发送请求对象
response = urllib.request.urlopen(request) #5 读取数据
data = response.read()
#保存到文件中,验证数据
with open("01cook.html","wb")as f:
f.write(data)
方法二:直接使用账号密码登录访问
退出登录,按F12 ,再登录,抓取数据
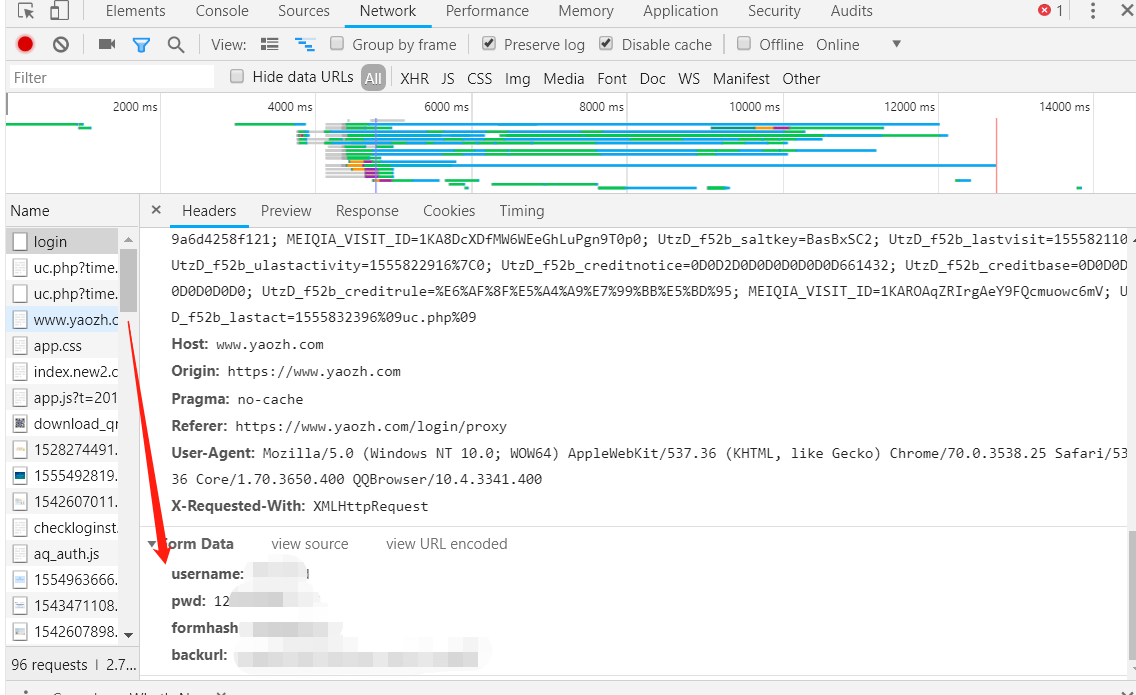
formhash和backurl要在登陆之前找代码
"""
获取 个人中心的页面
1.代码登录 登录成功 cookie(有效)
2. 自动带着cookie 去请求个人中心 cookiejar 自动保存这个cookie
"""
import urllib.request #请求库
from http import cookiejar #保存cookie用的
from urllib import parse #转译
#登录之前的, 登录页的网址https://www.yaozh.com/login
#找登录参数 #后台 根据你发送的请求方式来判断的 如果你是get(登录页面),如果POST(登录结果)
#1.代码登录
# 1.1 登录的网址
login_url = "https://www.yaozh.com/login" #1.2 登录的参数
login_form_data = {
"username": "用户",
"pwd": "密码",
"formhash": "E2F4BF731C",
"backurl": "https%3A%2F%2Fwww.yaozh.com%2F", }
#1.3 发送登录请求POST
cook_jar = cookiejar.CookieJar()
#定义有添加 cook 功能的 处理器
cook_hanlder = urllib.request.HTTPCookieProcessor(cook_jar)
#根据处理器 生成 opener
opener = urllib.request.build_opener(cook_hanlder) #带着参数 发送post请求
#添加请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3650.400 QQBrowser/10.4.3341.400"}
#1 参数 将来 需要转译 转码; 2 post 请求的 data 要求是bytes
login_str = parse.urlencode(login_form_data).encode('utf-8')
login_request = urllib.request.Request(login_url,headers=headers,data=login_str)
#如果登录成功,cookjar自动保存cookie
opener.open(login_request) # 2 代码带着cookie去访问 个人中心
center_url = "https://www.yaozh.com/member/"
center_request = urllib.request.Request(center_url,headers=headers)
response = opener.open(center_url)
#bytes -->str
data = response.read().decode() with open("02cook.html","w",encoding="utf-8")as f:
f.write(data)
用python代码模拟登录网站的更多相关文章
- 用python实现模拟登录人人网
用python实现模拟登录人人网 字数4068 阅读1762 评论19 喜欢46 我决定从头说起.懂的人可以快速略过前面理论看最后几张图. web基础知识 从OSI参考模型(从低到高:物理层,数据链路 ...
- Python requests模拟登录
Python requests模拟登录 #!/usr/bin/env python # encoding: UTF-8 import json import requests # 跟urllib,ur ...
- 【爬虫】python requests模拟登录知乎
需求:模拟登录知乎,因为知乎首页需要登录才可以查看,所以想爬知乎上的内容首先需要登录,那么问题来了,怎么用python进行模拟登录以及会遇到哪些问题? 前期准备: 环境:ubuntu,python2. ...
- 使用Python+Selenium模拟登录QQ空间
使用Python+Selenium模拟登录QQ空间爬QQ空间之类的页面时大多需要进行登录,研究QQ登录规则的话,得分析大量Javascript的加密解密,这绝对能掉好几斤头发.而现在有了seleniu ...
- Python爬虫模拟登录带验证码网站
问题分析: 1.爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 2.首先得明白 ...
- Python 3.3.3 使用requests模拟登录网站
在模拟登录上,requests确实比python标准库中的相关模块更加简洁. 假设你需要去爬一组页面(targetUrls),而这些页面要登录才能进行访问.那么requests能够提供一种相当简单的语 ...
- [Python] 模拟登录网站(。。为了之后操作数据。。)
我司的内部管理(Web)系统(日报)着实..(mafan).. 所以,就想自己动手增加一下便利性. 计划是, - 桌面程序 用来方便记录(按自己格式,数据随时保存到sqlite中,备用) 通过一览来确 ...
- python实现模拟登录【转】
原文网址:http://www.blogjava.net/hongqiang/archive/2012/08/01/384552.html 本文主要用python实现了对网站的模拟登录.通过自己构造p ...
- python实现模拟登录
本文主要用python实现了对网站的模拟登录.通过自己构造post数据来用Python实现登录过程. 当你要模拟登录一个网站时,首先要搞清楚网站的登录处理细节(发了什么样的数据,给谁发等...). ...
随机推荐
- day13 python迭代器与生成器
迭代器 字符串.列表.元组.字典.集合都可以被for循环,说明他们都是可迭代的 可迭代协议 : 就是内部实现了__iter__方法 可以被for循环的都是可迭代的,要想可迭代,内部必须有一个__ite ...
- java23种设计模式之: 策略模式,观察者模式
策略模式 --老司机开车,但是他今天想到路虎,明天想开奔驰...针对他不同的需求,来产生不同的应对策略 策略类是一个接口,定义了一个大概的方法,而实现具体的策略则是由实现类完成的,这样的目的是 ...
- linux下列出所有连接到你的Server的IP地址
linux下列出所有连接到你的Server的IP地址 最近要做一个检查所有连接到主机的IP的脚本,google到一篇老外写的文章 <List all IP addresses connected ...
- Linux can双机通信(2440+MCP2515 && 51+SJA1000)
2012-01-12 22:43:24 上图: 自收发成功完成后,那么双机通信就比较容易了.关键就是CAN波特率.ID标识.滤波设置正确即可双机通信了.
- nginx和php-fpm的进程启停重载总结
nginx和php-fpm对于-USR2.-HUP信号的处理方式不一样: TERM, INT(快速退出,当前的请求不执行完成就退出) QUIT (优雅退出,执行完当前的请求后退出) HUP (重新加载 ...
- DHCP的IP地址租约、释放
转自:https://blog.csdn.net/wangdk789/article/details/27052505 当DHCP客户端获取到一个IP地址后,并不代表可以永久使用这个地址,而是有一个使 ...
- Android中的数据储存
数据的储存是一个十分重要的功能,它涉及到各种类型的数据,各种的储存方式,今天就接触了Android中数据储存的简单应用,有一种方式是可以将存入的数据原封不动的存储起来,这里要用到openfileout ...
- combineReducers
const reactInit = '@@react/Init' const combineReducers = (reducers) => { const finalReducers = {} ...
- 西安理工大学 李爱民 Xi'an University of Technology, Aimin Li
李爱民-西安理工大学计算机科学与工程学院 ● 简介(Introduction)-> 李爱民(Aimin Li),男,湖北随州人,西安电子科学大学博士(PhD),中共党员.中国计算机学会会员,CS ...
- Docker 学习笔记(持久化数据的备份,还原)
假如我们应用程序需要一台 mssql 数据库来持久化数据,我们将 mssql 数据库运行于 Docker 容器中: docker run -d -p 1433:1433 -e "ACCEPT ...