xadmin 组件拓展自定义使用
xadmin 组件相关可选自定义字段
list_display
功能
设置默认的显示字段(列)
配置
list_display = ['name', 'desc', 'detail', 'degree', 'learn_time', 'students',
'fav_nums', 'click_nums', 'add_time', 'get_zj_nums', 'go_to']
# 自己定义的函数也可以被当做字段来展示, 展示结果为函数的运算结果 ( 返回值 )
效果
显示列中也可以手动更改显示字段 ( 列 ), 但是下次刷新的时候会恢复为只显示 list_display 中的字段 ( 列 )
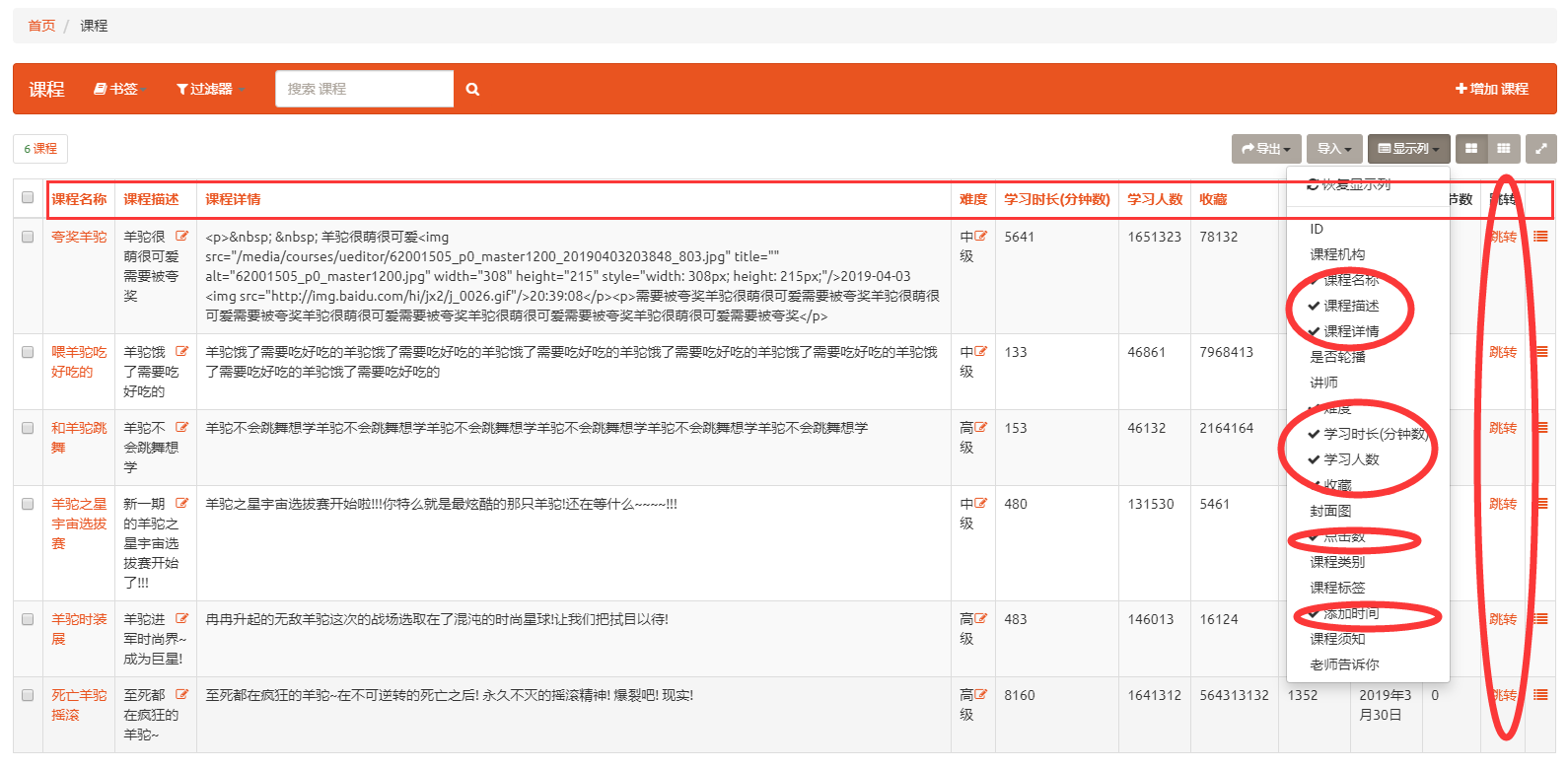
ps 自定义函数的字段显示
在相关的 model 中设置一段逻辑实现某些功能, 默认如果未配置 short_description 会以函数名为显示字段
设置后则用设置值为xadmin后台显示字段名, 显示内容为函数返回值
# 定义自定义的一个跳转字段, 内部为html代码的形式
def go_to(self):
from django.utils.safestring import mark_safe
return mark_safe("<a href='http://wwww.baidu.com'>跳转</a>")
go_to.short_description = "跳转"
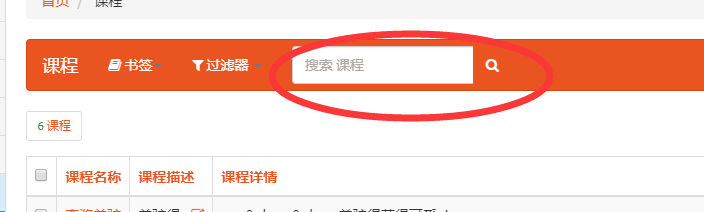
search_fields
功能
设置搜索字段索引
配置
放入列表的字段可以被视为可被搜索域
search_fields = ['name', 'desc', 'detail', 'degree', 'students', 'fav_nums', 'click_nums']
效果
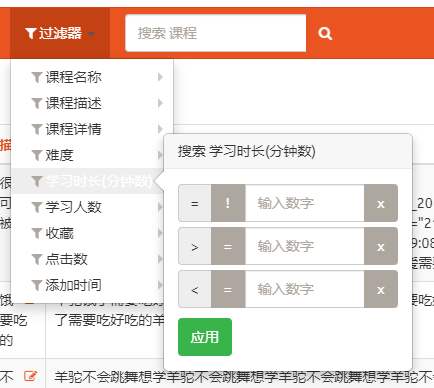
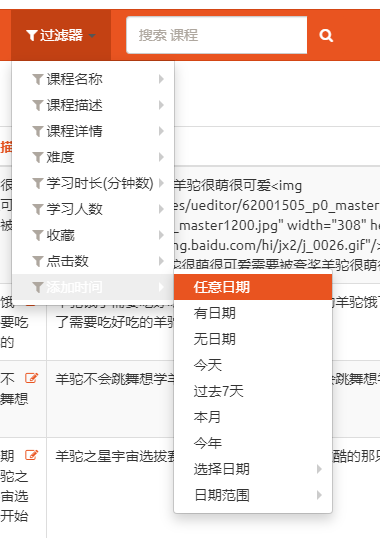
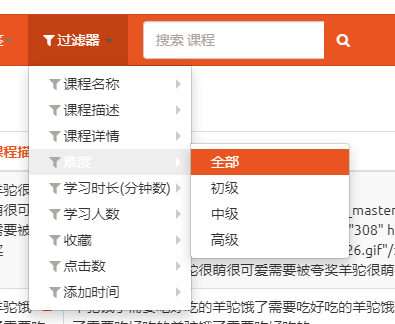
list_filter
功能
设置过滤器
配置
list_filter = ['name', 'desc', 'detail', 'degree', 'learn_time', 'students', 'fav_nums', 'click_nums','add_time']
效果
不同类型的字段会展示出不同的过滤选项

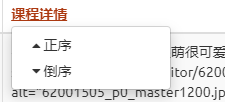
ordering
功能
初始展示时的默认排序方式
配置
ordering = ['-click_nums']
效果
其他的字段也可以进行手动的选择排序,刷新后恢复为默认排序

readonly_fields
功能
设置只读字段, 不可编辑
配置
readonly_fields = ['fav_nums']
效果
进入编辑页面后此字段是无法修改的状态
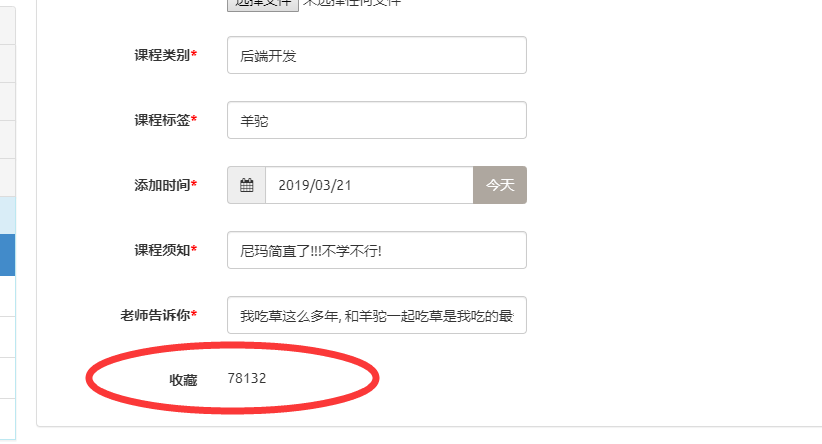
exclude
功能
设置不可见, 隐藏字段
配置
readonly_fields 和 exclude 是冲突的, 两个都设置会让 exclude 失效以只读显示
exclude = ['click_nums']
效果
设置前
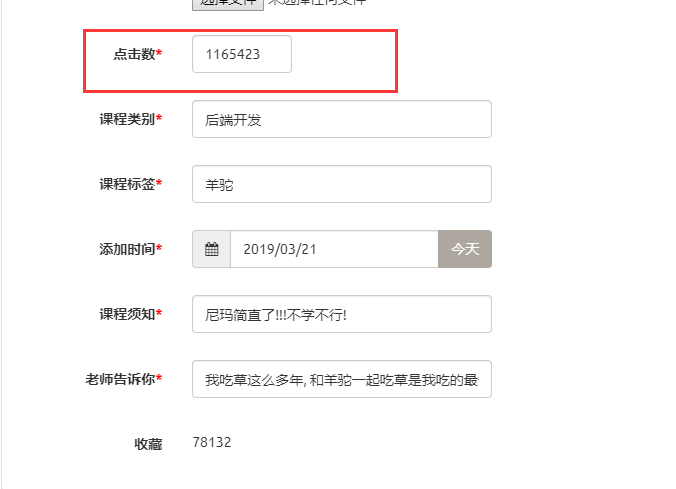
设置后

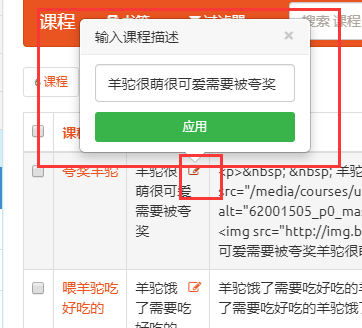
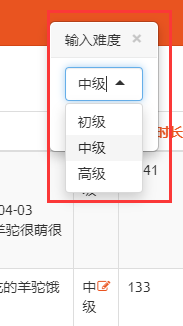
list_editable
功能
配置可编辑字段, 无需进入编辑页面即可编辑相关字段内容
配置
list_editable = ['degree', 'desc']
效果
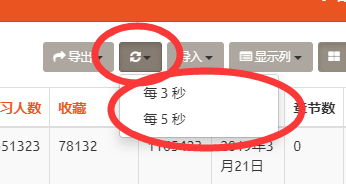
refresh_times
功能
设置 xadmin 后台刷新频率
配置
列表内的内容为单位秒, 设置多个为可选项
refresh_times = [3,5]
效果
inlines
功能
设置外键字典内容可被修改
配置
在此处应用场景中, Course 表有两个反向的外键字段连接到 Lesson表 和 CourseResource 表
为了实现在编辑 Course表的时候就可以更方便的一起把 此表相关联的 这两个字段内容改了会很舒服
进行此项设置, 需要提前写一个类, 内置两个字典 为 model 表名和 extar = 0 然后加入到 inlines 中
class LessonInline(object):
model = Lesson
extar = 0 class CourseResourceInline(object):
model = CourseResource
extar = 0
inlines = [LessonInline, CourseResourceInline]
效果
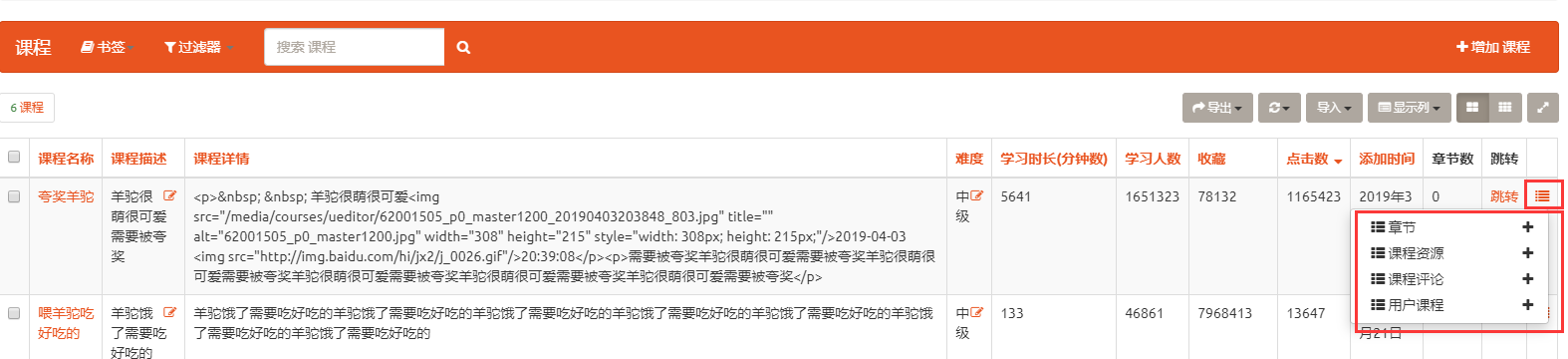
课程表中是没有章节字段和课程资源字段的( 因为是反向外键设置 ), 设置此字段后
这样我们在更改课程的时候就也可以顺带着添加章节和课程资源了. 就用户体验而言是很舒服的
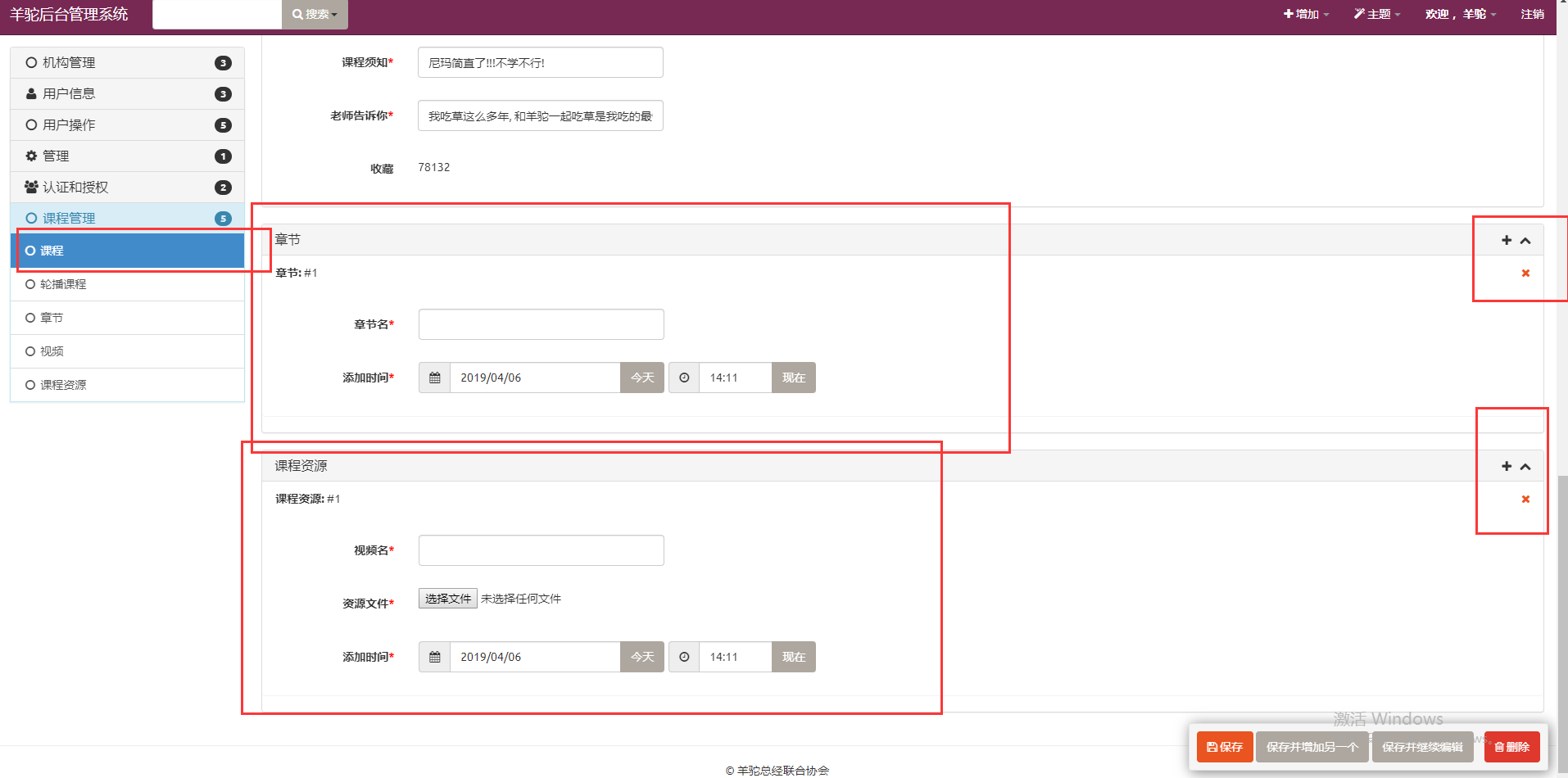
当然你如果不设置此字段,想添加外键实际上也可以通过外层的时候的最后面的符号进行所有的外键操作, 不如在里面添加来的直观和舒适
queryset
功能
将一张表根据某个字段作为区分为多表
配置
若想实现上下分表则需要重写 queryset 方法
此处配置为 以 is_banner 作为标识区分,原表中 所有 is_banner = False 的数据被筛选出来
def queryset(self): # 实现上下分表, 将轮播课程另外显示
qs = super(CourseAdmin, self).queryset()
qs = qs.filter(is_banner=False)
return qs
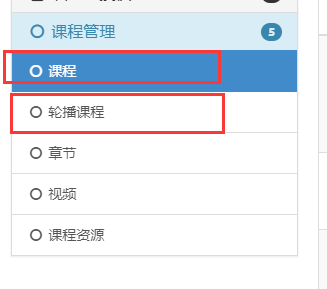
在model 中需要做此设置, 继承原表, proxy 设置为 True
class BannerCourse(Course):
class Meta:
verbose_name = "轮播课程"
verbose_name_plural = verbose_name
proxy = True # 不设置这个就会再生成一张表
然后在 adminx 中在将此模型进行 注册, 同原表 Course 一样的注册方式 ( xadmin 会视其为另一张表 )
此时的 重写 queryset 则为 is_banner = True 和原表进行上下分离
# 轮播课程注册
class BannerCourseAdmin(object):
list_display = ['name', 'desc', 'detail', 'degree', 'learn_time', 'students', 'fav_nums', 'click_nums', 'add_time']
search_fields = ['name', 'desc', 'detail', 'degree', 'students', 'fav_nums', 'click_nums']
list_filter = ['name', 'desc', 'detail', 'degree', 'learn_time', 'students', 'fav_nums', 'click_nums', 'add_time']
ordering = ['-click_nums']
readonly_fields = ['fav_nums']
exclude = ['click_nums']
inlines = [LessonInline, CourseResourceInline] def queryset(self):
qs = super(BannerCourseAdmin, self).queryset()
qs = qs.filter(is_banner=True)
return qs
效果
课程和轮播课程以是否轮播字段作为区分为两份表, 在 sql 中根源都是课程表
但是展示结果为
课程 = 不轮播的课程
轮播课程 = 轮播的课程
在 xadmin 中被视为两份独立的表分别进行各自定义的操作
save_models
功能
实现字段彼此的联动操作
配置
此处的应用场景是 课程添加后, 课程结构的可选课程数量跟随加1 ( 本质是即时更新 )
def save_models(self): # 在保存课程的时候统计课程机构的课程数
obj = self.new_obj
obj.save()
if obj.course_org is not None:
course_org = obj.course_org
course_org.course_nums = Course.objects.filter(course_org=course_org).count()
course_org.save()
效果
不截图了.这个就是普通的数据更新, 没啥界面变化
xadmin 组件拓展自定义使用的更多相关文章
- Django - Xadmin 组件(一)
Django - Xadmin 组件(一) Web 应用中离不开的就是后台管理, Django 自带的 admin 组件提供了一部分内容,但往往现实项目中会有更多的需求,所以自定义自己的后台管理就十分 ...
- Django - Xadmin 组件(二)
Django 自带的 admin 组件可以自定义配置,本文实现 Xadmin 对自定义显示数据列 (list_display) 的配置. 构建表单数据 模板层 从视图函数传来的数据变量是双层列表,第一 ...
- microsoft.extensions.logging日志组件拓展(保存文本文件)
Microsoft.Extensions.Logging 日志组件拓展 文件文本日志 文件文本日志UI插件 自定义介质日志 Microsoft.Extensions.Logging.File文件文本日 ...
- vue子组件的自定义事件
父子组件的信息传递无碍就是父组件给子组件传值(props和$attrs)和父组件触发子组件的事件($emit) 之前已经谈过了父组件给子组件传值了,现在来说说父组件触发子组件的自定义事件吧-- 实际上 ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- #003 React 组件 继承 自定义的组件
主题:React组件 继承 自定义的 组件 一.需求说明 情况说明: 有A,B,C,D 四个组件,里面都有一些公用的逻辑,比如 设置数据,获取数据,有某些公用的的属性,不想在 每一个 组件里面写这些属 ...
- taro 在components文件夹中 新建组件时,组件支持自定义命名,但是不能大写开头
在components文件夹中 新建组件时,组件支持自定义命名,但是不能大写开头.否则会报错 错误写法: // 真实路径 import MinaMask from '../../components/ ...
- 『NiFi 学习之路』自定义 —— 组件的自定义及使用
一.概述 许多业务仅仅使用官方提供的组件不能够满足性能上的需求,往往要通过高度可定制的组件来完成特定的业务需求. 而 NiFi 提供了自定义组件的这种方式. 二.自定义 Processor 占坑待续 ...
随机推荐
- ArrayAdapter、SimpleAdapter简单用法
1. 使用流程 2. ArrayAdapter new ArrayAdapter<?>(context, textViewResourceId, objects) context:上下 ...
- canvas 时钟动画
平时在公司不忙的时候,就喜欢写一些小效果什么的,一来复习复习,二来可以发现一些问题. 今天在群里看别人发了一手表的图片,卧槽...妥妥的工作好多年的节奏,后来想想还是做好自己的事情算了,想那多干啥,就 ...
- Docker 创建 Confluence6.12.2 中文版
目录 目录 1.介绍 1.1.什么是Confluence? 2.Confluence的官网在哪里? 3.如何下载安装? 4.对 Confluence 进行配置 4.1.设置 Confluence 4. ...
- windows 服务中托管asp.net core
在windows 服务中托管asp.net core SDK 2.1.300 官方示例 1.添加运行标识符 xml <PropertyGroup> <TargetFramework& ...
- PJSUA2开发文档--第十一章 网络问题
11 网络问题 11.1 IP地址更改 请参阅wiki 处理IP地址更改.请注意,本指南使用PJSUA API作为参考. 11.2 被阻止/过滤的网络 请参阅维基百科 通过阻止或过滤的VoIP网络
- CentOS.7下安装配置FTP和SFTP服务
一: FTP Centos7中默认已经安装了sshd服务(sftp), vsftpd需要手动安装 1.安装并启动FTP服务 1.1 安装vsftpd 使用 yum 安装 vsftpd yum inst ...
- c/c++ 多线程 std::call_once
多线程 std::call_once 转自:https://blog.csdn.net/hengyunabc/article/details/33031465 std::call_once的特点:即使 ...
- ansible学习(二)
什么是YAML? YAML是一种标记语言.适合用来表达层次结构式的数据结构. YAML的基本组件:清单(短杠——空白字符)和散列表(短杠+空白字符分隔key:value对). Playbook的核心元 ...
- Docker的使用初探(二):Docker与.NET Core的结合
目录 Docker的使用初探(二):Docker与.NET Core的结合 添加Dockefile 1. 在创建项目时添加 2. 手动添加 3. 容器业务流程协调控制程序支持 Dockefile语法 ...
- LVS+Keepalived实现mysql的负载均衡
1 初识LVS:Linux Virtual Server 1.1 LVS是什么 LVS是Linux Virtual Server的简称,也就是Linux虚拟服务器, 是一个由章文嵩博士发起 ...