Oracle更改redo log的大小
因为数据仓库ETL过程中,某个mapping的执行时间超过了一个小时,
select event,count(*) fromv$session_wait group by event order bycount(*) desc
发现日志切换占用了大量的时间,估尝试增大redo log的大小。
(1) redo log的大小可以影响 DBWR 和 checkpoint ;
(2)larger redo log files provide better performance. Undersized logfiles increase checkpoint activity and reduce performance.
大的log file可以提供更好的性能,小的logfile 会增加checkpoint 和降低性能;
(3)A rough guide is to switch log files at most once every 20 minutes.(推荐日志切换的时间不要超多20分钟).
通过查看 我有三组redolog 1/2/3每组两个成员状态都正常大小50m
select * from v$log ;

status 有几个值分别是:
- UNUSED(还没有使用过);
- CURRENT(正在使用);
- ACTIVE(Log isactive but is not the current log. It is needed for crash recovery);
- INACTIVE(Log is nolonger needed for instance recovery),
查看日志文件
select * from v$logfile ;

由于ORACLE并没有提供类似RESIZE的参数来重新调整REDO LOG FILE的大小,因此只能先把这个文件删除了,然后再重建。又由于ORACLE要求最少有两组日志文件在用,所以不能直接删除,必须要创建中间过渡的REDO LOG日志组。
1、创建3个新的日志组
ALTER DATABASE ADD LOGFILE GROUP 4('/usr/oracle/app/oradata/orcl/redo04a.log','/usr/oracle/app/oradata/orcl/redo04b.log') SIZE 2048M;
ALTER DATABASE ADD LOGFILE GROUP 5('/usr/oracle/app/oradata/orcl/redo05a.log','/usr/oracle/app/oradata/orcl/redo05b.log') SIZE 2048M;
ALTER DATABASE ADD LOGFILE GROUP 6('/usr/oracle/app/oradata/orcl/redo06a.log','/usr/oracle/app/oradata/orcl/redo06b.log') SIZE 2048M;
2、切换当前日志到新的日志组
alter system switch logfile; alter system switch logfile; alter system switch logfile;
3、删除旧的日志组
查看日志组的状态看一下哪个是当前组,哪个是inactive状态的。
SQL> select * from v$log;

删除掉inactive的那个组。如果状态为current和active 在删除的时候会报错
alter database drop logfile group 1; alter database drop logfile group 2; alter database drop logfile group 3;
4、操作系统下删除原日志组1、2、3中的文件
注意:每一步删除drop操作,都需要手工删除操作系统中的实体文件。
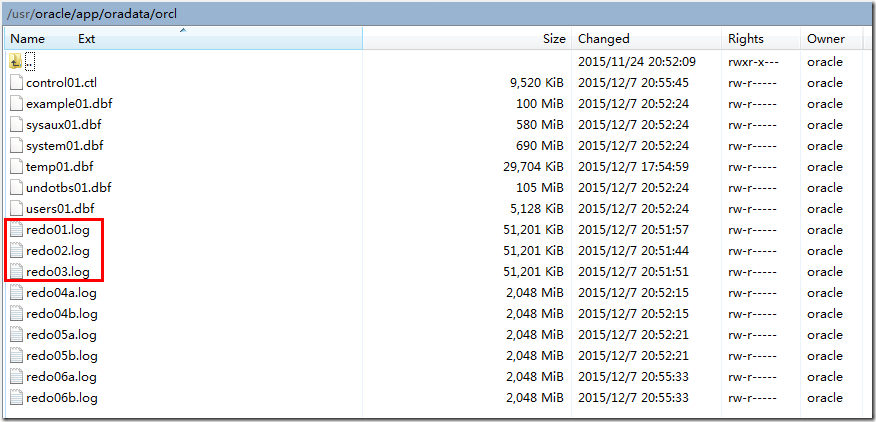
5、重建日志组1、2、3
ALTER DATABASE ADD LOGFILE GROUP 1('/usr/oracle/app/oradata/orcl/redo01a.log','/usr/oracle/app/oradata/orcl/redo01b.log')SIZE 2048M;
ALTER DATABASE ADD LOGFILE GROUP 2('/usr/oracle/app/oradata/orcl/redo02a.log','/usr/oracle/app/oradata/orcl/redo02b.log')SIZE 2048M;
ALTER DATABASE ADD LOGFILE GROUP 3('/usr/oracle/app/oradata/orcl/redo03a.log','/usr/oracle/app/oradata/orcl/redo03b.log')SIZE 2048M;
6、切换日志组
alter system switch logfile; alter system switch logfile; alter system switch logfile;
7、删除中间过渡用的日志组4、5、6
alter database drop logfile group 4; alter database drop logfile group 5; alter database drop logfile group 6;
8、到操作系统下删除原日志组4、5、6中的文件
9、备份当前的最新的控制文件
SQL> alter database backupcontrolfile to trace resetlogs
Oracle更改redo log的大小的更多相关文章
- Oracle更改redo log大小 or 增加redo log组
(1)redo log的大小可以影响 DBWR 和 checkpoint : (2)arger redo log files provide better performance. Undersize ...
- 修改redo log 的大小
alert日志中含有大量警告信息:"Thread 1 cannot allocate new log, sequence 320xx Checkpoint not complete" ...
- Oracle current redo.log出现坏块后的不完全恢复案例一则
1异常出现 8月30日下午2时左右,接同事电话,说数据库异常宕机了,现在启动不了. 2初步分析 我让现场把alert.log发过来,先看看是什么问题. 关于ORA-00353和ORA-0 ...
- Oracle Redo Log 机制 小结(转载)
Oracle 的Redo 机制DB的一个重要机制,理解这个机制对DBA来说也是非常重要,之前的Blog里也林林散散的写了一些,前些日子看老白日记里也有说明,所以结合老白日记里的内容,对oracle 的 ...
- Oracle Dataguard Standby Redo Log的两个实验
在Data Guard环境中,Standby Redo Log是一个比较特殊的日志类型.从最新的DG安装指导中,都推荐在Primary和Standby端,都配置Standby Redo Log. 简单 ...
- 调整innodb redo log files数目和大小的具体方法和步骤
相较于Oracle的在线调整redo日志的数目和大小,mysql这点则有所欠缺,即使目前的mysql80版本,也不能对innodb redo日志的数目和大小进行在线调整,下面仅就mysql调整inno ...
- InnoDB事务日志(redo log 和 undo log)详解
数据库通常借助日志来实现事务,常见的有undo log.redo log,undo/redo log都能保证事务特性,undolog实现事务原子性,redolog实现事务的持久性. 为了最大程度避免数 ...
- MySQL · 引擎特性 · InnoDB redo log漫游(转)
前言 InnoDB 有两块非常重要的日志,一个是undo log,另外一个是redo log,前者用来保证事务的原子性以及InnoDB的MVCC,后者用来保证事务的持久性. 和大多数关系型数据库一样, ...
- Mysql InnoDB Redo log
一丶什么是redo innodb是以也为单位来管理存储空间的,增删改查的本质都是在访问页面,在innodb真正访问页面之前,需要将其加载到内存中的buffer pool中之后才可以访问,但是在聊事务的 ...
随机推荐
- JS高级 - 面向对象3(面向过程改写面向对象)
改写: 1.前提:所有东西都在 onload 里 2.改写:不能有函数嵌套,可以有全局变量 onload --> 构造函数 全局变量 --> 属性 函数 --> 方法 4.改错: t ...
- [转] 理解 JavaScript 中的 Array.prototype.slice.apply(arguments)
假如你是一个 JavaScript 开发者,你可能见到过 Array.prototype.slice.apply(arguments) 这样的用法,然后你会问,这么写是什么意思呢? 这个语法其实不难理 ...
- [转] python安装numpy和pandas
最近要对一系列数据做同比比较,需要用到numpy和pandas来计算,不过使用python安装numpy和pandas因为linux环境没有外网遇到了很多问题就记下来了.首要条件,python版本必须 ...
- [NOI2012]骑行川藏(未完成)
题解: 满分又是拉格朗日啥的 以后再学 自己对于n=2猜了个三分 然后对拍了一下发现是对的
- SQL存储过程使用参考代码
存储过程 use EBuy go --常用的系统存储过程 sp_addmessage --将新的用户定义错误消息存储在SQL Server数据库实例中 sp_helptext --显示用 ...
- 51Nod 算法马拉松28 B题 相似子串 哈希
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - 51Nod1753 题意概括 两个字符串相似定义为: 1.两个字符串长度相等 2.两个字符串对应位置上有且仅有 ...
- python str,list,tuple转换
1. str转listlist = list(str) 2. list转strstr= ''.join(list) 3. tuple list相互转换tuple=tuple(list)list=l ...
- UVA 10976 分数拆分【暴力】
题目链接:https://vjudge.net/contest/210334#problem/C 题目大意: It is easy to see that for every fraction in ...
- Lemon 评测软件用法
Lemon 评测软件用法(陈国凯手把手教的) MYL学妹提供的软件,感谢. 编译器添加向导->预制编译器配置->g++: C:\Program Files\Dev-Cpp\MinGW64\ ...
- iOS开发安全
这篇文章之前自己在公司的技术分享学院发表了.现在发到自己的博客上. 现在很多iOS的app没有做任何的安全防范措施.今天我们就聊聊iOS开发人员平时怎么做才更安全. 一.网络方面 用抓包工具可以抓取手 ...