一文全解:利用谷歌深度学习框架Tensorflow识别手写数字图片(初学者篇)
笔记整理者:王小草
笔记整理时间2017年2月24日 原文地址 http://blog.csdn.net/sinat_33761963/article/details/56837466?fps=1&locationNum=5
Tensorflow官方英文文档地址:https://www.tensorflow.org/get_started/mnist/beginners
本文整理时官方文档最近更新时间:2017年2月15日
1.案例背景
本文是跟着Tensorflow官方文档的第二篇教程–识别手写数字。
MNIST是一个简单的计算机视觉数据集,它是由一系列手写数字图片组成的,比如: 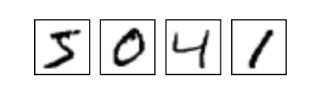
在数据集中,每一张图片会有一个标签label,表示该张图片上的数字是什么。比如以上图片所对应的标签是:5,0,4,1
对于初学者,为什么开篇就要介绍这个案例呢?举个栗子, 当我们学习写程序的时候,第一句打印的就是“Hello world”。那么MNIST相对于机器学习,就如同“Hello world”相对于程序
本文要介绍的是训练一个模型,使得这个模型可以根据输入的图片预测出上面写的是什么数字。但是本文的目的可不是去教大家训练一个具有超级优秀表现的完美模型哦(这个在之后的文档中会给出),而只是去建立一个简单的模型(softmax regression)让大家初尝tensorflow情滋味.
虽然要完成这个模型,对tensorflow只是几行代码的事,但理解这背后tensorflow运作的原理以及核心的机器学习概念也是相当重要呢。所以,接下去会对整个过程与原理都进行详细解释。
2.数据的获取:The MNIST Data
MNIST数据集可以在网站http://yann.lecun.com/exdb/mnist/下载到。
但是在TensorFlow中为了方便学习者获取这个数据,封装了一个方法,我们只需要调用这个方法,程序就会自动去下载和获取数据集。代码如下:
// 导入input_data这个类
from tensorflow.examples.tutorials.mnist import input_data
//从这个类里调用read_data_sets这个方法
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)获取到的数据集有3部分组成:
(1)55,000个训练样本(用来训练模型)
(2)10,000个测试样本(用来测试模型,避免过拟合)
(3)5,000个验证样本(用来验证超参数)
(一般在机器学习的建模中,都需要准备这3类数据集。)
对于每一个样本点,有两部分数据组成:
(1)手写数字图片,记做x
(2)标签,记做y
手写数字图片由28*28像素组成,可以将其转换成28*28的由数字组成的数组。如下例子: 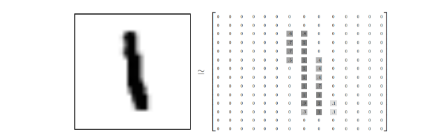
而这个28*28的数组又可以铺平成1*784的一个向量。至于铺平的方式无所谓,只要保证所有图片被铺平的方式都一样就行啦。所以,一个图片可以被一个1*784的向量所表示。
可能你会问,把图片这样从二维空间铺平会不会丧失了一些信息,会带来坏的影响吗?这个你放心,现在那些最好的计算机图像处理方法都是用了这个结构的,这在之后的教程中会有讲到。
好了,如果运行以上两行代码成功,那么数据就已经下载下来了,可以直接调用mnist.train.images,获取训练数据集的图片, 这是一个大小为[55000, 784]的tensor,第一维是55000张图片,第二维是784个像素。像素的强度是用0-1之间的数字表示的。 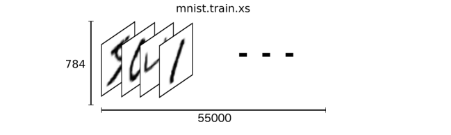
另外上面也说了,每个图片会对应一个标签,表示这个图片上对应的手写数字。
根据需要,我们需要将这0-9的数字标签转换成one-hot编码,什么是One-hot编码,举个例子一看便知,比如原来的标签是3,编码之后就变成了[0,0,0,1,0,0,0,0,0,0],也就是生成一个1*10的向量,分别对应0-9的数字在3对应的位置上为1,其余位置上都是0.
经过这样编码之后,训练集的标签数据就变成了[55000,10]的浮点类型的数组了。
恩恩,数据都下载下来,并且我们也知道数据的具体格式和内容啦,接下去,让我们开始建立模型吧~~
3.建立多分类模型:Softmax Regressions
3.1 Softmax Regressions原理
因为我们的目的是区分出0-9的数字,也就是要将图片在这10个类中进行分类,属于多元分类模型。对于一张图片,我们想要模型得到的是属于这10个类别的概率,举个例子,如果模型判断一张图片属于9的概率由80%,属于8的概率是5%,属于其他数字的概率都很小,那么最后这张图片应被归于9的类别。
Softmax Regressions是一个非常经典的用于多分类模型的方法。就算是之后的笔记中讲到的更复杂的模型,他们的最后一层也是会调用Softmax 这个方法的。
一个Softmax Regressions主要有2步:
(1)分别将输入数据属于某个类别的证据相加
(2)将这个证据转换成概率
好了,那么首先这个证据是个神马东东呢,其实就是一个线性模型,由权重w,与偏执项b组成: 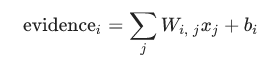
i表示第i类,j表示输入的这张图片的第j个像素,也就是求将每个像素乘以它的权重w,在加上偏执项的和。
求出了evidence之后,就要使用softmax函数将它转换成概率了。 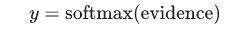
这里的softmax其实相当于是一个激活函数或者连接函数,将输出的结果转换成我们想要的那种形式(在这里,是转换成10各类别上的概率分布)。那么这个softmax的过程是经过了什么样的函数转换呢?如下公式: 
展开以上公式: 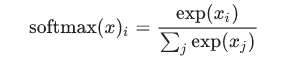
也就是说,将刚刚的线性输出evidence作为softmax函数里的输入x,先进过一个幂函数,然后做正态化,使得所有的概率相加等于1.
将softmax regression的过程画出来如下: 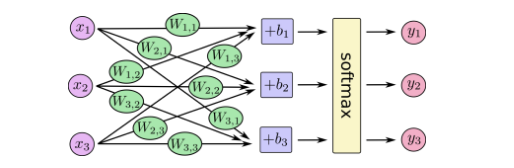
如果写成公式,那就是如下: 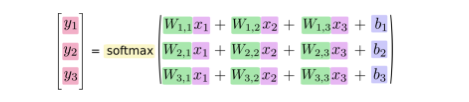
将以上公式做改进,变成矩阵和向量的形式: 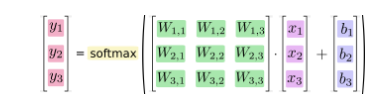
要是想简单直观一点,那么就这样: 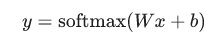
至此,我们知道了多元分类Softmax Regressions的计算原理,那么接下去就可以去尝试用tensorflow来实现Softmax Regressions啦~
2.2 Tensorflow实现softmax regression
1.要使用tensorflow,实现导入tensorflow的库:
import tensorflow as tf2.为输入数据x创建占位符
x = tf.placeholder(tf.float32, [None, 784])这里的x并不是具体的数值,而是一个占位符,就是先给要输入的数据霸占一个位置,等当真的让TensorFlow运行计算的时候,再传入x的真实数据。因为我们的输入数据n个是1*784的向量,可以表示成2层的tensor,大小是[None,784],None表示到时候后传输的数据可以任何长度,也就是说可以是任何数量的样本点。
3.创建两个权重变量
w和b是在训练过程中不断改变不断优化的,使用Variable来创建:
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))以上,我们初始化两个权重都为0,在之后的训练与学习中会不断被优化成其他值。注意,w的大小是[784,10]表示784个像素输入点乘以10维的向量(10个类别)。b的大小是[ 10 ]
4.建立softmax模型
y = tf.nn.softmax(tf.matmul(x, W) + b)以上代码可见,我们先将x与W相乘了,然后加上了b,然后将线性输出经过softmax的转换。
嗯,至此softmax的模型就写好了。
4.模型训练
1.建立损失函数
上面我们搭建了一个初始的softmax的模型,注意模型中的参数w,b是自己随便定义的。那么训练模型的目的是让模型在学习样本的过程中不断地优化参数,使得模型的表现最好。
那么如何评价模型表现的好坏呢?在机器学习中,我们一般使用损失函数来评价模型的好坏。如果模型预测的结果与真实的结果相差越远,那么损失大,模型的表现就越不好。因此,我们渴望去最小化损失从而得到最优的模型。
这里介绍一个最常用的损失函数:交叉熵损失。公式如下: 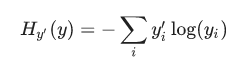
y表示模型预测出来的概率分布,y’表示真实的类别概率分布(就是之间one-hot编码之后的标签)。yi表示预测为第i个类的概率, yi’表示真实属于i类的概率(只有i类为1,其余为0)
交叉熵从一定意义上可以度量模型对于真实情况的拟合程度,交叉熵越大,则模型越不拟合,表现力越差。
要实现交叉熵函数,代码如下:
// 为真实的标签添加占位符
y_ = tf.placeholder(tf.float32, [None, 10])
// 创建交叉熵函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))解释一下上面的代码,tf.log表示将y的每一个元素都做log运算;然后将其乘以对应的真实标签的类别y_中的元素。tf.reduce_sum表示的是将索引为1的值进行求和。tf.reduce_mean表示对所有样本的交叉熵求均值。
注意注意,在源码中,我们没有使用这个公式,因为这样计算下去数值不稳定。取而代之的是直接在线性函数之后应用了tf.nn.softmax_cross_entropy_with_gogits(即,没有单独经过softmax函数),这样会更加稳定。
2.使用BP算法优化参数
损失函数就是我们的目标函数,要找到目标函数的最小值,就是对参数求偏导等于0.我们可以使用优化器去不断地降低损失寻找最优参数。比如说最常用的是梯度下降法。代码如下:
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)上面使用了梯度下降法最小化交叉熵损失,学习率设置为0.5,每一次迭代,w,b两类参数都会改变,直到损失达到最小的时候,就获得了最优的w,b。
不过tensorflow也提供了很多其他的优化器(后续介绍)
3.运行迭代
模型训练的graph基本已经完成,现在我们可以初始化变量,创建会话,来进行循环训练了。
// 创建会话
sess = tf.InteractiveSession()
// 初始化所有变量
tf.global_variables_initializer().run()
//循环1000次训练模型
for _ in range(1000):
# 获取训练集与标签集,每次获取100个样本
batch_xs, batch_ys = mnist.train.next_batch(100)
# 喂数据,训练
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})在每次循环中,都会从训练集中获取一批样本,每批有100个样本。然后运行train_step这个操作,并且给之前的占位符喂入数据。
你可能会觉得奇怪,为什么不直接拿所有的训练集来做循环训练,为啥每次要随机地拿100个样本呢?这里应用了随机梯度下降法。直接使用所有样本来做循环迭代的“梯度下降法”固然更理想,但是会大大增加计算的成本,而“随机梯度下降法”减少了计算量并且也保持了相对一致的准确率。
5.模型评估
通过模型的训练,我们得到了最优的参数,但是在这个最优的参数下,模型的表现力到底如何呢?
我们可以看看在测试集上模型预测的label与样本真实的Label相同的有多少比例。
tf.argmax返回的是一个tensor里在某个维度上最大值的索引,比如tf.argmax(y,1)取出的是预测输出的10个类别的概率向量中最大概率的那个索引(对应某个类别),tf.argmax(y_,1)取出的是该样本的真实类别的索引,如果对于一个样本,两者相同,则说明对该样本的预测正确。下面代码,用tf.equal返回的是一个布尔类型的列表。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))要求出正确率,只要将布尔类型的列表全部求和再求均值即可:
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))现在我们喂入测试数据集,来运行计算测试集上的准确率:
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))打印出来大概是92%。
这个结果好吗?额。。其实并没有呢,而且可以说挺差的。。
模型表现不好的原因在于我们使用的是一个很简单的模型,做一些小的改良,正确率可以达到97%。最好的模型可以达到99.7的准确率!
至此,我们介绍了完整的用tensorflow来训练softmax regression多元分类模型的案例。
一文全解:利用谷歌深度学习框架Tensorflow识别手写数字图片(初学者篇)的更多相关文章
- NN:利用深度学习之神经网络实现手写数字识别(数据集50000张图片)—Jason niu
import mnist_loader import network training_data, validation_data, test_data = mnist_loader.load_dat ...
- 金玉良缘易配而木石前盟难得|M1 Mac os(Apple Silicon)天生一对Python3开发环境搭建(集成深度学习框架Tensorflow/Pytorch)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_189 笔者投入M1的怀抱已经有一段时间了,俗话说得好,但闻新人笑,不见旧人哭,Intel mac早已被束之高阁,而M1 mac已经 ...
- 截图:【炼数成金】深度学习框架Tensorflow学习与应用
创建图.启动图 Shift+Tab Tab 变量介绍: F etch Feed 简单的模型构造 :线性回归 MNIST数据集 Softmax函数 非线性回归神经网络 MINIST数据集分类器简单版 ...
- Ubuntu16.04搭建深度学习框架——TensorFlow
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库,说白了,就是一个库. 小编自己在Ubuntu搭建了深度学习框架TensorFlow,感觉挺简单,现 ...
- 学习笔记TF024:TensorFlow实现Softmax Regression(回归)识别手写数字
TensorFlow实现Softmax Regression(回归)识别手写数字.MNIST(Mixed National Institute of Standards and Technology ...
- Tensorflow学习教程------模型参数和网络结构保存且载入,输入一张手写数字图片判断是几
首先是模型参数和网络结构的保存 #coding:utf-8 import tensorflow as tf from tensorflow.examples.tutorials.mnist impor ...
- 深度学习框架TensorFlow在Kubernetes上的实践
什么是TensorFlow TensorFlow是谷歌在去年11月份开源出来的深度学习框架.开篇我们提到过AlphaGo,它的开发团队DeepMind已经宣布之后的所有系统都将基于TensorFlow ...
- 【转】机器学习教程 十四-利用tensorflow做手写数字识别
模式识别领域应用机器学习的场景非常多,手写识别就是其中一种,最简单的数字识别是一个多类分类问题,我们借这个多类分类问题来介绍一下google最新开源的tensorflow框架,后面深度学习的内容都会基 ...
- 关于深度学习框架 TensorFlow、Theano 和 Keras
[TensorFlow] ——( https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/) 1.TensorFlow是啥 ...
随机推荐
- 大一下第2次作业(markdown改)
一.作业 6-7 删除字符串中数字字符 1.设计思路 (1)主要描述题目算法 第一步:用for循环和if语句,一个一个字符判断,找到数字字符就跳过去判断下一个,否则使指针指向不是(已判断过的)数字字符 ...
- 后门技术(HOOK篇)之DT_RPATH
0x01 GNU ld.so动态库搜索路径 参考材料:https://en.wikipedia.org/wiki/Rpath 下面介绍GNU ld.so加载动态库的先后顺序: LD_PRELOAD环境 ...
- jquery使用ajax提交form表单
$.ajax({ type: jqform.attr('method'), // 提交方式 get/post url: jqform.attr('action'), // 需要提交的 url data ...
- java list 的遍历
import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; import java.util.I ...
- Windows 10下使用WMware 12 安装Ubuntu16.04,安装过程(附全过程图)
序言:菜鸡的我又开始瞎搞Ubuntu了 首先在网下下载VMware 12 正常安装即可 关于产品密匙问题:5A02H-AU243-TZJ49-GTC7K-3C61N (这是我在网上找的密匙,反正自己是 ...
- Bellman-Ford的队列优化
Bellman-Ford算法在每实施依次松弛后,就会有一些顶点已经求得最短路,此后这些顶点的最短路的估计值就会一直不变,不再收后续松弛操作的影响,但是每次还要判断是否需要松弛,这就浪费时间了. 从上面 ...
- node学习笔记之io.sockets
socket.get和socket.set函数已经失效,代码修改如下所示: 服务器端: var httpd = require('http').createServer(handler); var i ...
- python Console menu
I just finished a demo which is to provide an easy way to control hardware resources of A sample. Th ...
- codeblock设置快捷键
第一步: 第二步: 第三步: 格式化代码设置: 在代码框里点右键,按Format use Astyle就会自动代码格式化了 但是它默认的风格是大括号另起一行,很不习惯,实际上是可以改的 1.Sett ...
- Linux或树莓派3——挂载U盘、移动硬盘并设置rwx权限
话说最近在树莓派上搭建了一个owncloud,因为树莓派的存储空间有限,就插了个16G的U盘,然后设置成开机自动挂载.这里稍微注意一下的是U盘的格式最好不要NTFS,因为一般情况下NTFS格式的文件系 ...