【Hbase学习之一】Hbase 简介
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
apache-hive-2.1.3
一、简介
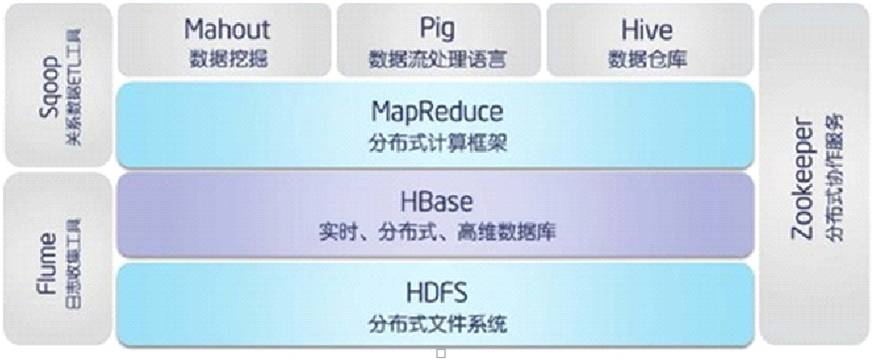
Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库,属于非关系型数据库。
利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务
主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)。
二、数据模型
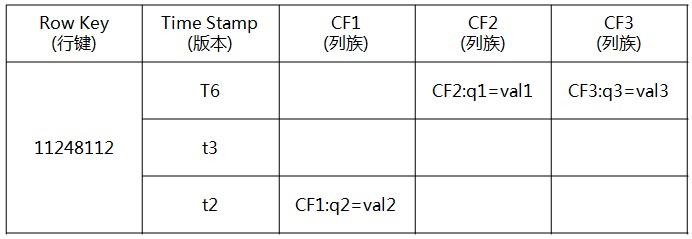
示例:
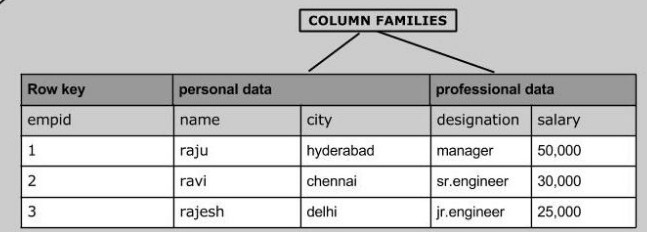
1、ROW KEY
-决定一行数据
-按照字典顺序排序的(a、b、c… 1、2、3…)。
-Row key只能存储64k的字节数据
2、Column Family列族 & qualifier列
HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math, course:english, 新的列族成员(列)可以随后按需、动态加入;
权限控制、存储以及调优都是在列族层面进行的;
HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
3、Timestamp时间戳
-在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
-时间戳的类型是 64位整型。
-时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
-时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
4、Cell单元格
由行和列的坐标交叉决定;
单元格是有版本的;
单元格的内容是未解析的字节数组;
由{row key, column( =<family> +<qualifier>), version} 唯一确定的单元。
cell中的数据是没有类型的,全部是字节码形式存贮。
5、HLog(WAL log)
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
三、HBase 架构
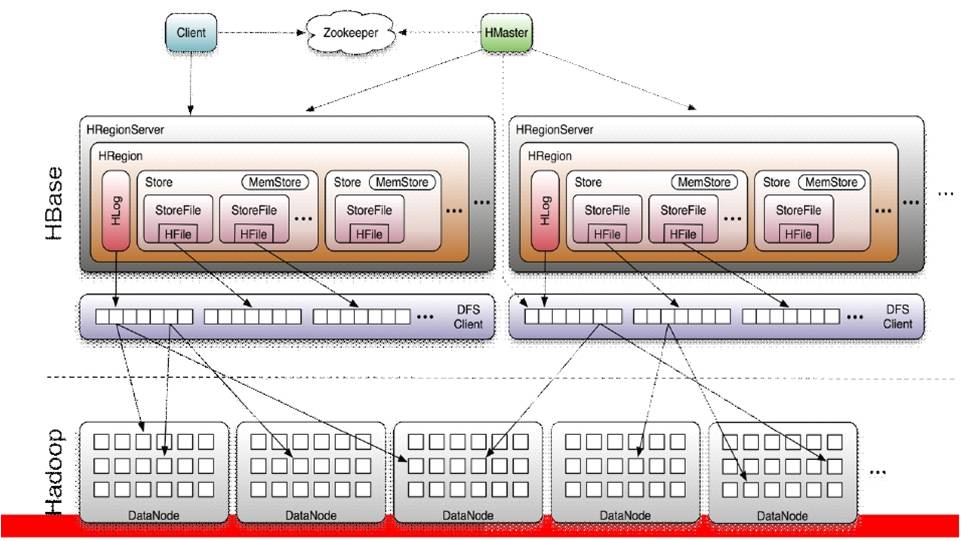
1、Client
包含访问HBase的接口并维护cache来加快对HBase的访问
2、Zookeeper
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口。
实时监控Region server的上线和下线信息。并实时通知Master
存储HBase的schema和table元数据
3、Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改操作
4、RegionServer
Region server维护region,处理对这些region的IO请求
Region server负责切分在运行过程中变得过大的region
5、Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据
每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变)
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
6、Memstore 与 storefile
一个region由多个store组成,一个store对应一个CF(列族)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
客户端检索数据,先在memstore找,找不到再找storefile
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。


【Hbase学习之一】Hbase 简介的更多相关文章
- Hbase 学习(一) hbase配置文件同步
最近在狂啃hadoop的书籍,这部<hbase:权威指南>就进入我的视野里面了,啃吧,因为是英文的书籍,有些个人理解不对的地方,欢迎各位拍砖. HDFS和Hbase配置同步 hbase的配 ...
- HBase 学习之一 <<HBase使用客户端API动态创建Hbase数据表并在Hbase下导出执行>>
HBase使用客户端API动态创建Hbase数据表并在Hbase下导出执行 ----首先感谢网络能够给我提供一个开放的学习平台,如果没有网上的技术爱好者提供 ...
- HBase学习笔记-HBase性能研究(1)
使用Java API与HBase集群交互时,需要构建HTable对象,使用该对象提供的方法来进行插入/删除/查询等操作.要创建HTable对象,首先要创建一个带有HBase集群信息的配置对象Confi ...
- HBase学习——4.HBase过滤器
1.过滤器 基础API中的查询操作在面对大量数据的时候是非常苍白的,这里Hbase提供了高级的查询方法:Filter.Filter可以根据簇.列.版本等更多的条件来对数据进行过滤,基于Hbase本身提 ...
- HBase学习——3.HBase表设计
1.建表高级属性 建表过程中常用的shell命令 1.1 BLOOMFILTER 默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用HColumnDescriptor. ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase学习系列
转自:http://www.aboutyun.com/thread-8391-1-1.html 问题导读: 1.hbase是什么? 2.hbase原理是什么? 3.hbase使用中会遇到什么问题? 4 ...
- HBase学习笔记之HBase的安装和配置
HBase学习笔记之HBase的安装和配置 我是为了调研和验证hbase的bulkload功能,才安装hbase,学习hbase的.为了快速的验证bulkload功能,我安装了一个节点的hadoop集 ...
- HBase学习笔记-高级(一)
HBase1. hbase.id记录了集群的唯一标识:hbase.version记录了文件格式的版本号2. split和.corrupt目录在日志分裂过程中使用,以便保存一些中间结果和损坏的日志在表目 ...
- HBase学习-HBase原理
1.系统架构 1.1 图解 从HBase的架构图上可以看出,HBase中的组件包括Client.Zookeeper.HMaster.HRegionServer.HRegion.Store.MemS ...
随机推荐
- ajax 上传文件,显示进度条,进度条100%,进度条隐藏,出现卡顿就隐藏进度条,显示正在加载,再显示上传完成
<form id="uploadForm" method="post" enctype="multipart/form-data"&g ...
- 【PyQt5-Qt Designer】pyqtSignal()-高级自定义信号与槽
PyQt 5信号与槽的几种高级玩法 参考:http://www.broadview.com.cn/article/824 from PyQt5.QtCore import QObject , pyqt ...
- 基于fiddler实现本地代理完成脚本测试
配置好fiddler以后,具体操作流程如下: 1.找到后在右边点击AutoResponder,查看,默认情况如下 勾选 2.ctrl+F 搜索 app. 关键字 ,找到后拖到右侧 3.替换本地文件 4 ...
- what's the 头寸
头寸,是一种市场约定,承诺买卖外汇合约的最初部位,买进外汇合约者是多头,处于盼涨部位:卖出外汇合约为空头,处于盼跌部位.头寸可指投资者拥有或借用的资金数量. “头寸”一词来源于近代中国,银行里用于日常 ...
- SELinux介绍
SELinux概念 安全加强的Linux,早期的Linux系统安全由系统管理员控制.SELinux就是一些安全规则的集合,类似于人类生活中的法律. DAC: 自由访问控制(以前的linux版本) ...
- JetBrains 2017/2018全系列产品激活工具
可谓是工欲善其事,必先利其器,相信作为优秀开发工程师的你都想拥有一套快捷高效的编码工具,而JetBrains这家公司的产品,不管是那种编程语言,其开发工具确实让开发者们着迷,JetBrains的产品博 ...
- w97常用功能代码
1,onclick中添加日期控件 2,onpicked事件即是点击控件后触发的事件 3,dp.cal.getNewDateStr()即是点击到的日期字符串 <script> functio ...
- PHP中MySQL、MySQLi和PDO的用法和区别
PHP的MySQL扩展(优缺点) 设计开发允许PHP应用与MySQL数据库交互的早期扩展.mysql扩展提供了一个面向过程 的接口: 并且是针对MySQL4.1.3或更早版本设计的.因此,这个扩展虽然 ...
- 将c语言的结构体定义变成对应的golang语言的结构体定义,并将golang语言结构体变量的指针传递给c语言,cast C struct to Go struct
https://groups.google.com/forum/#!topic/golang-nuts/JkvR4dQy9t4 https://golang.org/misc/cgo/gmp/gmp. ...
- php合并数组并保留键值的方法
答案:使用 + 连接两个数组,替换array_merge()函数. php合并数组,一般会使用array_merge方法. array_merge — 合并一个或多个数组 array array_me ...