java kafka 生产者消费者demo
Java中提供高级的API,相对于低级API(更小的粒度控制消费)使用起来非常方便。
一、修改kafka server.porperties的ip是你kafka服务的ip
listeners=PLAINTEXT://192.168.111.130:9092
二、生产者的例子
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerDemo {
private final Producer<String, String> kafkaProdcer;
public final static String TOPIC = "JAVA_TOPIC";
private KafkaProducerDemo() {
kafkaProdcer = createKafkaProducer();
}
private Producer<String, String> createKafkaProducer() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.111.130:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
return kafkaProducer;
}
void produce() {
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
final String key = "key" + i;
String data = "hello kafka message:" + key;
kafkaProdcer.send(new ProducerRecord<String, String>(TOPIC, key, data), new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("发送key" + key + "成功");
}
});
}
}
public static void main(String[] args) {
KafkaProducerDemo kafkaProducerDemo = new KafkaProducerDemo();
kafkaProducerDemo.produce();
}
}
用properties构造一个Producer的实例,然后调用send方法,传入数据,还有一个回调函数。
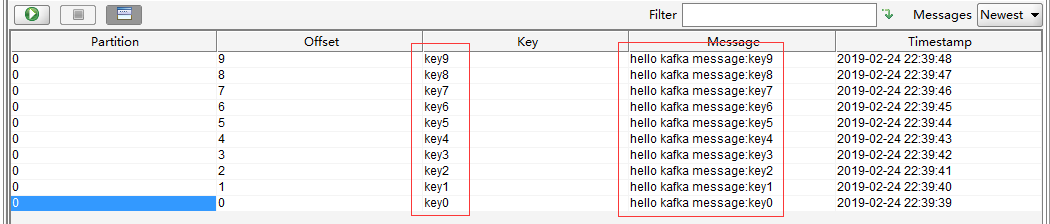
可以看到数据已经进来了。
注意:kafka producer支持同步发送、异步发送、异步发送+回调函数方式。
1、同步方式会按顺序发送,打印出来的结果是按发送的顺序:
for (int i = 0; i < 1000; i++) {
RecordMetadata test = producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "hello world-" + i)).get();
System.out.println(test);
}
2、回调函数里面可以对成功或者失败,分支判断,进行业务上的进一步处理。甚至可以把失败的消息存储下来。
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("test", i + "", "xxx-" + i), new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
} else {
System.out.println("发送成功");
}
}
});
}
注:回调函数里面onCompletion方法其实是阻塞的! 如果进行延时,会逐个执行,不会同时并发跑,但是发送数据任然是异步的。
三、消费者例子
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; public class KafkaConsumerDemo {
private final KafkaConsumer<String, String> consumer;
private KafkaConsumerDemo(){
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.111.130:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<String, String>(props);
}
void consume(){
consumer.subscribe(Arrays.asList(KafkaProducerDemo.TOPIC));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
System.out.println("I'm coming");
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
public static void main(String[] args) {
KafkaConsumerDemo kafkaConsumerDemo = new KafkaConsumerDemo();
kafkaConsumerDemo.consume();
}
}
正常启动是看不到东西的, 两个同时启动才有。消费者只看接下来有哪些生产者发来新的消息。
props.put("enable.auto.commit", "true");
这个的意思是,消费后自动改变偏移量。如果不添加这个,就会在服务器存的offset开始消费,并且不会改变offset的值。
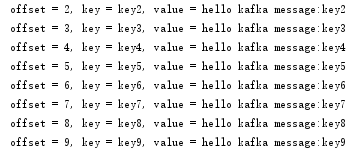
如果为false, 可以看到不管消费几次,服务端存储的始终是offset的值都不会改变,需要手动提交offset。
如果想让consumer从头开始消费,可以设置:
props.put("auto.offset.reset", "earliest");
这个只对新建的组有效,如果一个组已经消费过,offset的值已经存在服务端了,这样设置不起作用的,只会从服务端存储的offset开始消费。不设置默认是latest,就是从最新的开始消费。
java kafka 生产者消费者demo的更多相关文章
- Java实现生产者消费者问题与读者写者问题
摘要: Java实现生产者消费者问题与读者写者问题 1.生产者消费者问题 生产者消费者问题是研究多线程程序时绕不开的经典问题之一,它描述是有一块缓冲区作为仓库,生产者可以将产品放入仓库,消费者则可以从 ...
- Python 使用python-kafka类库开发kafka生产者&消费者&客户端
使用python-kafka类库开发kafka生产者&消费者&客户端 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- Java设计模式—生产者消费者模式(阻塞队列实现)
生产者消费者模式是并发.多线程编程中经典的设计模式,生产者和消费者通过分离的执行工作解耦,简化了开发模式,生产者和消费者可以以不同的速度生产和消费数据.这篇文章我们来看看什么是生产者消费者模式,这个问 ...
- java实现生产者消费者问题
引言 生产者和消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一个存储空间,如下图所示,生产者向空间里存放数据,而消费者取用数据,如果不加以协调可能会出现以下情况: 生产者消费者图 ...
- java实现生产者消费者问题(转)
引言 生产者和消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一个存储空间,如下图所示,生产者向空间里存放数据,而消费者取用数据,如果不加以协调可能会出现以下情况: 生产者消费者图 ...
- [转载] Java实现生产者消费者问题
转载自http://www.cnblogs.com/happyPawpaw/archive/2013/01/18/2865957.html 引言 生产者和消费者问题是线程模型中的经典问题:生产者和消费 ...
- java实现生产者消费者模式
生产者消费者问题是一个著名的线程同步问题,该问题描述如下:有一个生产者在生产产品,这些产品将提供给若干个消费者去消费,为了使生产者和消费者能并发执行,在两者之间设置一个具有多个缓冲区的缓冲池,生产者将 ...
- java 线程 生产者-消费者与队列,任务间使用管道进行输入、输出 解说演示样例 --thinking java4
package org.rui.thread.block2; import java.io.BufferedReader; import java.io.IOException; import jav ...
- Java 实现生产者 – 消费者模型
转自:http://www.importnew.com/27063.html 考查Java的并发编程时,手写“生产者-消费者模型”是一个经典问题.有如下几个考点: 对Java并发模型的理解 对Java ...
随机推荐
- ICMP timestamp 请求响应漏洞
ICMP timestamp请求响应漏洞 解决方案: * 在您的防火墙上过滤外来的ICMP timestamp(类型13)报文以及外出的ICMP timestamp回复报文. google之, ...
- prototype [ˈprəʊtətaɪp] 原型
<script> Array.prototype.mysort = function(){ let s = this; for(i=0;i<s.length;i++){ s[i] = ...
- java-信息安全(十)-数字签名算法DSA
概述 信息安全基本概念: DSA算法(Digital Signature Algorithm,数据签名算法) DSA Digital Signature Algorithm (DSA)是Schnorr ...
- [JS] ECMAScript 6 - Class : compare with c#
Ref: Class 的基本语法 Ref: Class 的基本继承 许多面向对象的语言都有修饰器(Decorator)函数,用来修改类的行为.目前,有一个提案将这项功能,引入了 ECMAScript. ...
- [Node.js] 07 - Html and Http
前言 一.原本的计划 Node.js 路由 Node.js GET/POST请求 到此,有必要复习下http章节 Node.js Web 模块 Node.js Express 框架 Node.js R ...
- [React] 06 - Route: koa makes your life easier
听说koa比express更傻瓜化,真的? Koa 框架教程 本身代码只有1000多行,所有功能都通过插件实现,很符合 Unix 哲学. 搭建简单服务器 Koa, 架设一个简单的服务器 // demo ...
- 【Docker】容器操作(转)
来自:https://www.cnblogs.com/zydev/p/5803461.html 列出主机上的容器 列出正在运行的容器: docker ps 列出所有容器: docker ps - ...
- python网络编程之UDP方式传输数据
UDP --- 用户数据报协议(User Datagram Protocol),是一个无连接的简单的面向数据报的运输层协议. UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能 ...
- Spark2 Random Forests 随机森林
随机森林是决策树的集合. 随机森林结合许多决策树,以减少过度拟合的风险. spark.ml实现支持随机森林,使用连续和分类特征,做二分类和多分类以及回归. 导入包 import org.apache. ...
- Django----djagorestframwork使用
restful(表者征状态转移,面向资源编程)------------------------------------------->约定 从资源的角度审视整个网络,将分布在网络中某个节点的资源 ...