Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
对于Spark的初学者,往往会有一个疑问:Spark(如SparkRDD、SparkSQL)在处理数据的时候,会将数据都加载到内存再做处理吗?
很显然,答案是否定的!
对该问题产生疑问的根源还是对Spark计算模型理解不透彻。
对于Spark RDD,它是一个分布式的弹性数据集,不真正存储数据。如果你没有在代码中调用persist或者cache算子,Spark是不会真正将数据都放到内存里的。
此外,还要考虑persist/cache的缓存级别,以及对什么进行缓存(比如是对整张表生成的DataSet缓存还是列裁剪之后生成的DataSet缓存)(关于Spark RDD的特性解析参考《Spark RDD详解》
既然Spark RDD不存储数据,那么它内部是如何读取数据的呢?其实Spark内部也实现了一套存储系统:BlockManager。为了更深刻的理解Spark RDD数据的处理流程,先抛开BlockManager本身原理,从源码角度阐述RDD内部函数的迭代体系。
我们都知道RDD算子最终会被转化为shuffle map task和result task,这些task通过调用RDD的iterator方法获取对应partition数据,而这个iterator方法又会逐层调用父RDD的iterator方法获取数据(通过重写scala.collection.iterator的hasNext和next方法实现)。主要过程如下:
首先看ShuffleMapTask和ResultTask中runTask方法的源码:
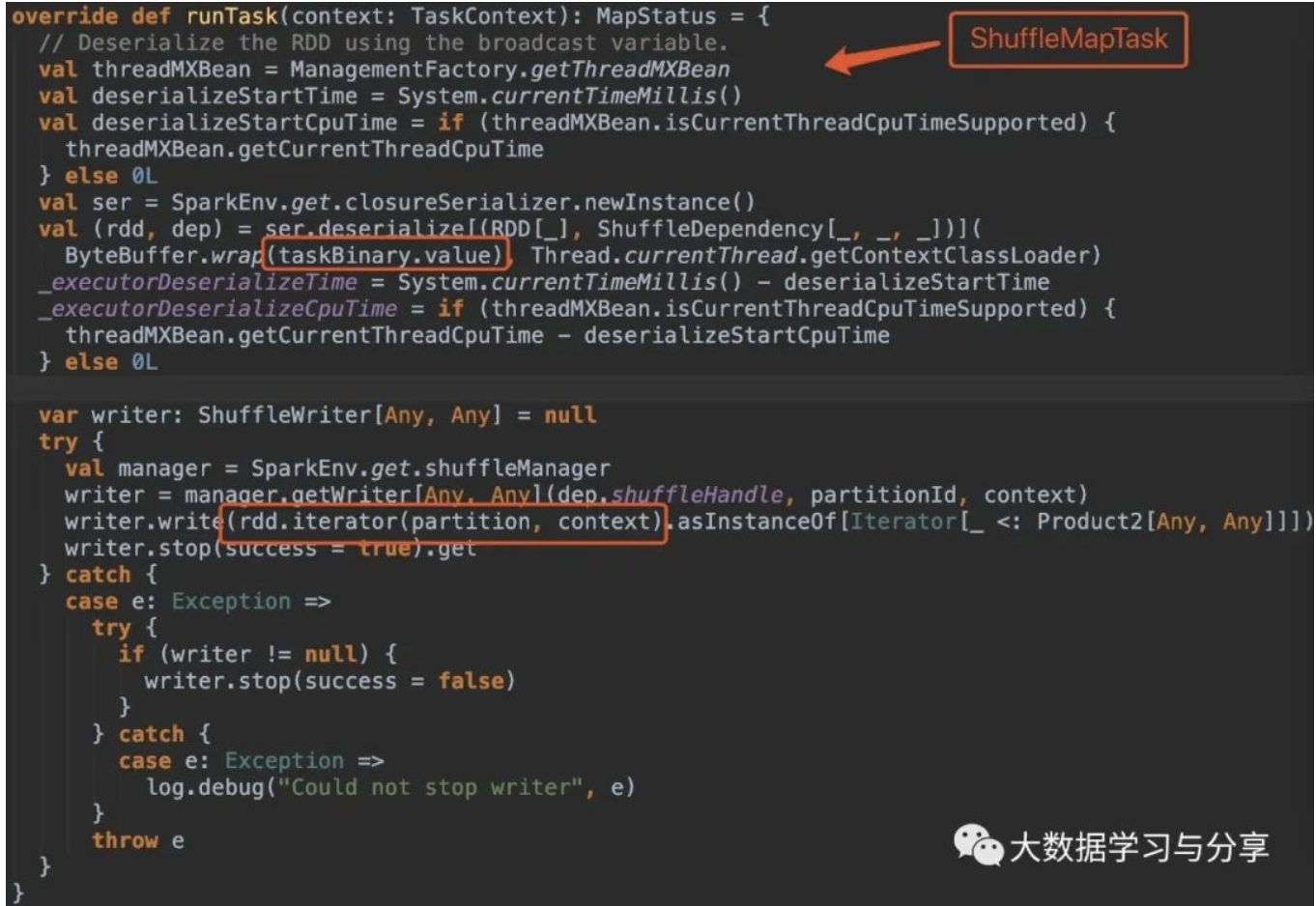
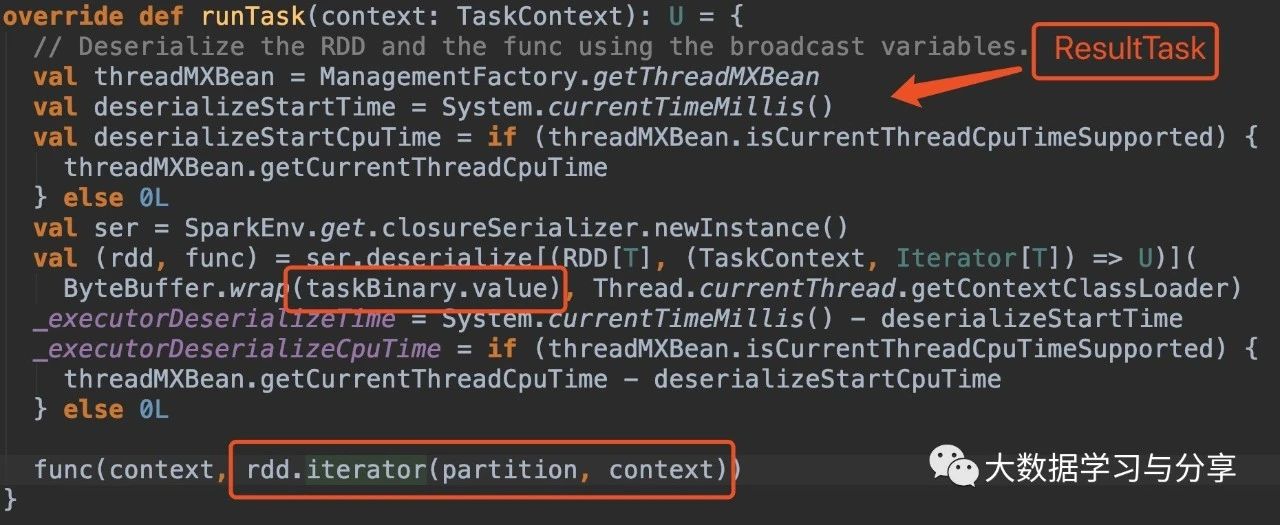
关键看这部分处理逻辑:
rdd.iterator(partition, context)
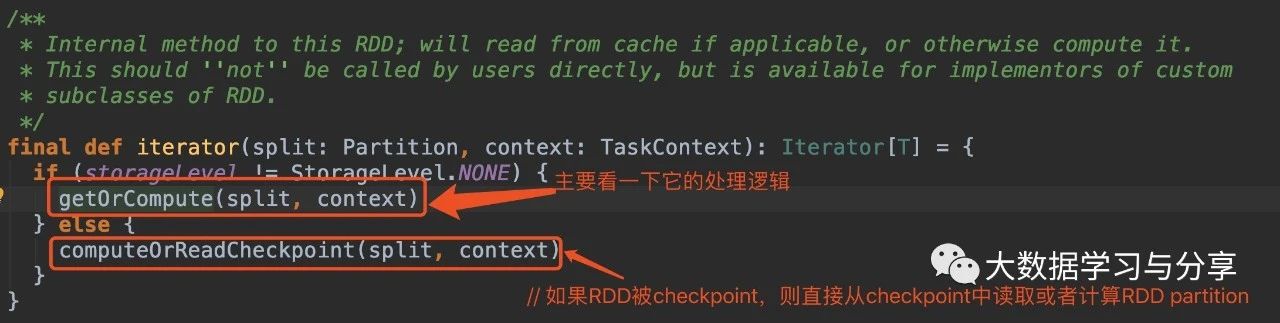
getOrCompute方法会先通过当前executor上的BlockManager获取指定blockId的block,如果block不存在则调用computeOrReadCheckpoint,如果要处理的RDD没有被checkpoint或者materialized,则接着调用compute方法进行计算。
compute方法是RDD的抽象方法,由继承RDD的子类具体实现。
以WordCount为例:
sc.textFile(input)
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile(output)
textFile会构建一个HadoopRDD
flatMap/map会构建一个MapPartitionsRDD
reduceByKey触发shuffle时会构建一个ShuffledRDD
saveAsTextFile作为action算子会触发整个任务的执行
以flatMap/map产生的MapPartitionsRDD实现的compute方法为例:
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
底层调用了parent RDD的iterator方法,然后作为参数传入到了当前的MapPartitionsRDD。而f函数就是对parent RDD的iterator调用了相同的map类函数以执行用户给定的函数。
所以,这是一个逐层嵌套的rdd.iterator方法调用,子RDD调用父RDD的iterator方法并在其结果之上调用Iterator的map函数以执行用户给定的函数,逐层调用直到调用到最初的iterator(比如上述WordCount示例中HadoopRDD partition的iterator)。
而scala.collection.Iterator的map/flatMap方法返回的Iterator就是基于当前Iterator重写了next和hasNext方法的Iterator实例。比如,对于map函数,结果Iterator的hasNext就是直接调用了self iterator的hasNext,next方法就是在self iterator的next方法的结果上调用了指定的map函数。
flatMap和filter函数稍微复杂些,但本质上一样,都是通过调用self iterator的hasNext和next方法对数据进行遍历和处理。
所以,当我们调用最终结果iterator的hasNext和next方法进行遍历时,每遍历一个数据元素都会逐层调用父层iterator的hasNext和next方法。各层的map函数组成一个pipeline,每个数据元素都经过这个pipeline的处理得到最终结果。
这也是Spark的优势之一,map类算子整个形成类似流式处理的pipeline管道,一条数据被该链条上的各个RDD所包裹的函数处理。
再回到WordCount例子。HadoopRDD直接跟数据源关联,内存中存储多少数据跟读取文件的buffer和该RDD的分区数相关(比如buffer*partitionNum,当然这是一个理论值),saveAsTextFile与此类似。MapPartitionsRDD里实际在内存里的数据也跟partition数有关系。ShuffledRDD稍微复杂些,因为牵扯到shuffle,但是RDD本身的特性仍然满足(记录文件的存储位置)。
说完了Spark RDD,再来看另一个问题:Spark SQL对于多表之间join操作,会先把所有表中数据加载到内存再做处理吗?
当然,肯定也不需要!
具体可以查看Spark SQL针对相应的Join SQL的查询计划,以及在之前的文章《Spark SQL如何选择join策略》中,针对目前Spark SQL支持的join方式,任何一种都不要将join语句中涉及的表全部加载到内存。即使是Broadcast Hash Join也只需将满足条件的小表完整加载到内存。
推荐文章:
通过spark.default.parallelism谈Spark谈并行度
Spark为什么只有在调用action时才会触发任务执行呢(附算子优化和使用示例)?
关注微信公众号:大数据学习与分享,获取更对技术干货
Spark在处理数据的时候,会将数据都加载到内存再做处理吗?的更多相关文章
- [WP8.1UI控件编程]Windows Phone大数据量网络图片列表的异步加载和内存优化
11.2.4 大数据量网络图片列表的异步加载和内存优化 虚拟化技术可以让Windows Phone上的大数据量列表不必担心会一次性加载所有的数据,保证了UI的流程性.对于虚拟化的技术,我们不仅仅只是依 ...
- Tomcat启动时加载数据到缓存---web.xml中listener加载顺序(例如顺序:1、初始化spring容器,2、初始化线程池,3、加载业务代码,将数据库中数据加载到内存中)
最近公司要做功能迁移,原来的后台使用的Netty,现在要迁移到在uap上,也就是说所有后台的代码不能通过netty写的加载顺序加载了. 问题就来了,怎样让迁移到tomcat的代码按照原来的加载顺序进行 ...
- js 鼠标滚动到某屏时,加载那一屏的数据,仿京东首页楼层异步加载模式
js用处:在做商城时,首页图片太多,严重影响首页打开速度,所以我们需要用到异步加载楼层.js名称:鼠标滚动到某屏时,加载那一屏的数据,仿京东首页楼层模式js解释:1.用于商城的楼层内容异步加载,滚动条 ...
- Tomcat启动时加载数据到缓存---web.xml中listener加载顺序(优先初始化Spring IOC容器)
JavaWebSpringTomcatCache 最近用到在Tomcat服务器启动时自动加载数据到缓存,这就需要创建一个自定义的缓存监听器并实现ServletContextListener接口,并且 ...
- Highcharts 基本曲线图;Highcharts 带有数据标签曲线图表;Highcharts 异步加载数据曲线图表
Highcharts 基本曲线图 实例 文件名:highcharts_line_basic.htm <html> <head> <meta charset="U ...
- python数据可视化-matplotlib入门(7)-从网络加载数据及数据可视化的小总结
除了从文件加载数据,另一个数据源是互联网,互联网每天产生各种不同的数据,可以用各种各样的方式从互联网加载数据. 一.了解 Web API Web 应用编程接口(API)自动请求网站的特定信息,再对这些 ...
- html ajax请求 php 下拉 加载更多数据 (也可点击按钮加载更多)
<input type="hidden" class="total_num" id="total" value="{$tot ...
- EF如何操作内存中的数据以及加载相关联表的数据:延迟加载、贪婪加载、显示加载
之前的EF Code First系列讲了那么多如何配置实体和数据库表的关系,显然配置只是辅助,使用EF操作数据库才是每天开发中都需要用的,这个系列讲讲如何使用EF操作数据库.老版本的EF主要是通过Ob ...
- EF如何操作内存中的数据和加载外键数据:延迟加载、贪婪加载、显示加载
EF如何操作内存中的数据和加载外键数据:延迟加载.贪婪加载.显示加载 之前的EF Code First系列讲了那么多如何配置实体和数据库表的关系,显然配置只是辅助,使用EF操作数据库才是每天开发中都需 ...
随机推荐
- docker通过dockerfile构建JDK最小镜像,Docker导出导入镜像
docker通过dockerfile构建JDK最小镜像,Docker导出导入镜像 一.docker通过dockerfile构建JDK最小镜像 1.1 下载JRE 1.2 解压JRE,删除相关不需要文件 ...
- php之在admin的目录下的php文件里加上JSON的报头,运行php文件会提示下载
去掉报头就正常,但在前端引用数据时要加上JSON.parse,不然读不出数据. $.get("fetchUpLast.php",{ rd:new Date().getTime()} ...
- three.js cannon.js物理引擎制作一个保龄球游戏
关于cannon.js我们已经学习了一些知识,今天郭先生就使用已学的cannon.js物理引擎的知识配合three基础知识来做一个保龄球小游戏,效果如下图,在线案例请点击博客原文. 我们需要掌握的技能 ...
- linux(9)find命令详解
find命令格式: find path -option [ -print ] [ -exec -ok command ] {} \; find命令的参数: path:要查找的目录路径. ~ 表示$HO ...
- 使用汇编语言实现memcpy
把内核放入内存,究竟需做什么 写满实现内核功能的代码的文件会被编译成一个ELF文件.这个ELF文件不同于LOADER BIN文件.后者实质是一个没有使用DOS命令的COM文件.因此,只需将它原封不动地 ...
- Docker下使用centos无法使用systemctl怎么办
提交正在使用的容器: docker commit [ContainerId] 提交停止正在运行无法使用Systemctl的容器: docker stop [ContainerId] 删除这个容器(可选 ...
- CSAPP_BombLab实验报告
Lab_2实验报告 目录 Lab_2实验报告 屏幕截图 考察内容 各题答案 bomb1 bomb2 bomb3 bomb4 bomb5 bomb6 secret_phase 解题思路 bomb1 bo ...
- 【noi 2.6_4982】踩方格(DP)
题意:一个无限大的方格矩阵,能向北.东.西三个方向走.问走N步共有多少种不同的方案. 解法: f[i]表示走 i 格的方案数. 状态转移方程推导如下--设l[i],r[i],u[i]分别为第 i 步向 ...
- Codeforces Round #650 (Div. 3) F1. Flying Sort (Easy Version) (离散化,贪心)
题意:有一组数,每次操作可以将某个数移到头部或者尾部,问最少操作多少次使得这组数非递减. 题解:先离散化将每个数映射为排序后所对应的位置,然后贪心,求最长连续子序列的长度,那么最少的操作次数一定为\( ...
- windows server 2016 安装有线网卡驱动
为自己的本本安装了server 2016系统,但是官网下载的有线网卡驱动一直安不上,解决方法如下: 1.到Intel官网下载一个叫PROWinx64的驱动程序,解压到任意文件夹.依次进入PRO1000 ...