Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

arXiv:2001.01587v1 [cs.NE] 1 Jan 2020
Abstract
脉冲神经网络(SNN)被广泛应用于神经形态设备中,以模拟大脑功能。在这种背景下,SNN的安全性变得重要但缺乏深入的研究,这与深度学习的热潮不同。为此,我们针对SNN的对抗攻击,确认了与ANN攻击不同的几个挑战:i)当前的对抗攻击是基于SNN中以时空模式呈现的梯度信息,这在传统的学习算法中很难获得;ii)在梯度累积过程中,输入的连续梯度与二值脉冲输入不兼容,阻碍了基于脉冲的对抗样本的生成;iii)由于发放函数的导数中零占据主导,输入梯度可能为全零(即消失),有时容易中断样本更新。
近年来,基于时间反向传播(BPTT)启发的学习算法被广泛应用于SNN中,提高了SNN的性能,使得在给定时空梯度图的情况下对模型进行精确攻击成为可能。我们提出了两种方法来解决上述问题:梯度输入不相容和梯度消失。具体地说,我们设计了一个梯度-脉冲(G2S)转换器,将连续梯度转换为与脉冲输入兼容的三元梯度。然后,我们设计了一个梯度触发器(GT)来构造三元梯度,在满足梯度全零的情况下,能够以可控的翻转率随机翻转脉冲输入。将这些方法结合起来,建立了一种基于监督算法的SNN对抗攻击方法。此外,我们还分析了训练损失函数和倒数第二层发放阈值的影响,指出交叉熵损失下的“陷阱”区域可以通过阈值调整来逃脱。通过大量的实验验证了该方案的有效性,在大多数基准上攻击成功率达到99%以上,是SNN攻击的最佳结果。除了对影响因素进行定量分析外,我们还证明SNN比ANN之于对抗攻击更加健壮。这项工作有助于揭示SNN攻击中发生的情况,并有助于进一步研究SNN模型和神经形态设备的安全性。
Keywords: 对抗攻击,脉冲神经网络,监督学习,梯度兼容性和消失
I. INTRODUCTION
脉冲神经网络(SNN)[1]通过时空神经元动态和事件驱动活动(1-spike或0-nothing)密切模拟神经回路的行为。它们在处理动态和噪声信息方面显示出了很好的效率[2, 3],并被广泛应用于光流估计[4]、脉冲模式识别[5]、SLAM[6]、概率推理[3]、启发式求解NP-hard问题[7],快速求解优化问题[8]、稀疏表示[9]、机器人学[10]等。除了算法研究外,SNN还广泛应用于低功耗脑启发计算的神经形态设备中[8, 11–13]。
随着学术界和工业界对SNN的关注,SNN的安全问题变得越来越重要。在这里,我们关注的是对抗攻击[14],它是神经网络安全中最流行的威胁模型之一。在对抗攻击中,攻击者在输入数据中引入不可察觉的恶意干扰,即生成对抗样本,操纵模型越过决策边界,从而误导分类结果。通常,实现对抗攻击的方法有两类:基于内容的和基于梯度的。前者直接修改输入的语义信息(如亮度、旋转等)或将预定义得特洛伊木马注入输入[15-18];后者根据指定标签下的输入梯度修改输入[19-23]。基于梯度的对抗攻击能够获得更好的攻击效果,这是本文研究的重点。
尽管对抗攻击是人工神经网络(ANN)研究的热点,但在SNN领域却鲜有研究。我们通过对抗样本确定了攻击SNN模型的几个挑战。首先,SNN中的梯度信息是一种时空模式,传统的学习算法如无梯度无监督学习[24]和纯空间梯度ANN-SNN转换学习[25]难以获得。其次,梯度是连续值,与二值脉冲输入不兼容。这种数据格式的不兼容性阻碍了通过梯度累积产生基于脉冲的对抗样本。最后,当梯度与阶跃发放函数的主要为零的导数交叠时,会出现严重的梯度消失,这将中断对抗样本的更新。事实上,已经有很多关于SNN攻击的研究是使用输入扰动试错或迁移针对ANN攻击提出的技术。具体地说,可以通过简单地监视输出变化而不计算梯度来对输入扰动进行试错[26, 27];可以继承由对应ANN生成的对抗样本来攻击SNN模型[28]。然而,它们只是规避而不是直接解决SNN攻击问题,这会导致一些弊端,最终会降低攻击效果。例如,试错输入扰动法在没有监督梯度引导的情况下面临较大的搜索空间;SNN/ANN模型转换法需要额外的模型转换,忽略了时间维度的梯度信息。
近年来,基于时间反向传播(BPTT)启发的监督学习算法[2, 5, 29, 32]被广泛引入SNN中,以提高SNN的性能,使其能够直接获取空间和时间两个维度的梯度信息,即时空梯度图。这就为无需模型转换直接计算SNN中的监督梯度实现精确的SNN攻击提供了机会。然后,针对梯度输入不兼容和梯度消失的问题,我们提出了两种方法。我们设计了一个梯度-脉冲(G2S)转换器,将连续梯度转换为与脉冲输入兼容的三元梯度。G2S采用了概率采样、符号提取和溢出感知变换等智能技术,可以同时保持脉冲格式和控制扰动幅度。然后我们设计了一个梯度触发器(GT)来构造三元梯度,当面对全零梯度图时,可以随机翻转脉冲输入,其中输入的翻转率是可控的。在此攻击方法下,我们分析了训练损失函数的形式和发放阈值两个重要因素对攻击效果的影响。我们发现交叉熵(CE)损失训练的模型存在一个“陷阱”区域,与均方误差(MSE)损失训练的模型相比,该区域更难攻击。幸运的是,“陷阱”区域可以通过调整倒数第二层的发放阈值来逃脱。我们在神经形态数据集(如N-MNIST[33]和CIFAR10-DVS[34])和图像数据集(如MNIST[35]和CIFAR10[36])上广泛验证了我们的SNN攻击方法,并取得了优异的攻击效果。我们的贡献总结如下:
- 我们确认了SNN模型的对抗攻击挑战,这与ANN攻击有很大的不同。然后,通过脉冲兼容梯度,首次实现了精确的SNN攻击。这项工作有助于揭示攻击SNN时发生的情况,并可能促进对SNN模型和神经形态设备的安全性的更多研究。
- 针对梯度输入不兼容问题,我们设计了一个梯度-脉冲(G2S)转换器和一个梯度触发器(GT)来解决梯度消失问题,形成了一种基于梯度的监督算法训练SNN的对抗攻击方法。我们的设计很好地控制了扰动的大小。
- 我们探讨了训练损失函数和倒数第二层发放阈值对攻击效果的影响,并提出了阈值调整的方法来提高攻击效果。
- 在神经形态和图像数据集上进行了大量的实验,我们的方法在大多数情况下显示99%以上的攻击成功率,这是SNN攻击的最佳结果。此外,与ANN相比,SNN具有更强的对抗攻击健壮性。
本文的其余部分安排如下:第II节介绍了SNN攻击和对抗攻击的一些预备工作;第III节讨论了SNN攻击的挑战和我们与以往工作的区别;第IV节和第V节阐述了我们的攻击方法和影响攻击效果的两个因素;第VI节介绍了实验设置和结果分析;最后,第VII节对论文进行了总结和讨论。
II. PRELIMINARIES
A. Spiking Neural Networks
受生物神经回路的启发,SNN被设计用来模拟它们的行为。脉冲神经元是基本的结构单元,如图1所示,由树突、胞体和轴突组成;许多由加权突触连接的脉冲神经元形成SNN,其中二值脉冲事件携带神经元间通讯的信息。树突整合了加权的突触前输入,胞体因此更新膜电位,并决定是否发放一个脉冲。当膜电位超过一个阈值时,一个脉冲将被发放,并通过轴突发送到后神经元。
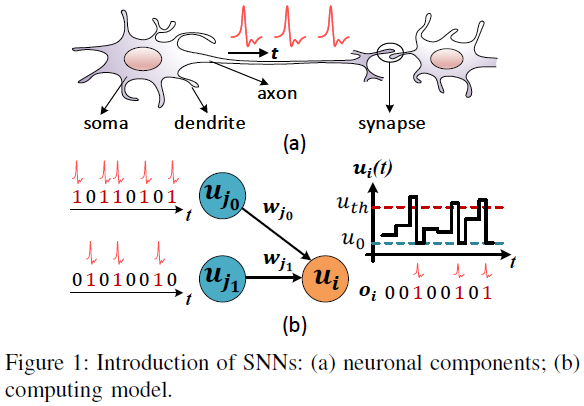
LIF模型[37]是应用最广泛的SNN模型。每个LIF神经元的行为可以简单地表达为
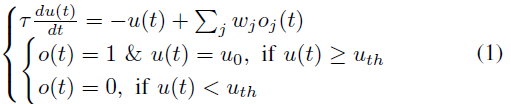
其中t表示时间步骤,τ表示时间常数,u和o分别表示膜电位和由此产生的输出脉冲。wj是第 j 个前神经元与当前神经元之间的突触权重,oj是第 j 个前神经元的输出脉冲(同时也是当前神经元的脉冲输入)。uth是所提到的发放阈值,u0是发放脉冲后使用的重置电位。
前馈SNN的网络结构可以与ANN的网络结构相似,包括卷积(Conv)层、池化层和全连接(FC)层。网络输入可以是动态视觉传感器[38]捕获脉冲事件(即神经形态数据集)或通过Bernoulli采样从正常图像数据集转换的事件[2]。根据输出层的脉冲进行分类。
B. Gradient-based Adversarial Attack
我们以ANN中基于梯度的对抗攻击为例。神经网络实际上是一个从输入到输出的映射,即y = f(x),其中x和y分别表示输入和输出,f: Rm → Rn是映射函数。卷积神经网络(CNN)的输入通常是静态图像。在对抗攻击中,攻击者试图通过在输入图像中添加不可察觉的扰动δ来操纵受害者模型以产生错误的输出。我们定义x' = x+δ为对抗样本。扰乱受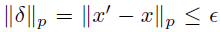 所约束,其中||·||p表示p-范数,ε反映最大容忍扰动。
所约束,其中||·||p表示p-范数,ε反映最大容忍扰动。
一般来说,根据攻击目标的不同,对抗攻击可以分为非目标攻击和目标攻击。非目标攻击愚弄了模型,将对抗样本分为除了原本正确的样本外的任何其他类,可以用f(x+δ) ≠ f(x)来说明。相反,对于目标攻击,对抗样本必须归类到指定的类,即f(x+δ) = ytarget。根据这些初步知识,对抗攻击可以表述为一个优化问题,如下所示,以搜索最小扰动:
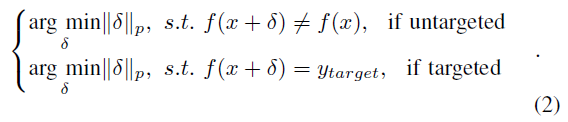
有几种广泛采用的对抗攻击算法可以找到上述优化问题的近似解。这里我们介绍两种方法:快速梯度符号法(fast gradient sign method,FGSM)[19]和基本迭代法(basic iterative method,BIM)[20]。
FGSM. FGSM的主要思想是根据输入的梯度信息生成对抗样本。具体地说,它计算输入图像的梯度图,然后用一个小的比例因子在原始图像中加上或减去该输入梯度图的符号。对抗样本的产生可以表述为:
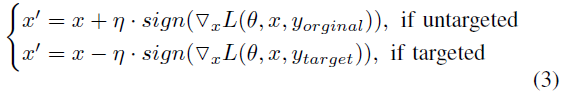
其中L和θ表示损失函数和受害者模型的参数。η用于控制扰动的大小,这通常很小。在非目标攻击中,对抗样本会将输出从原始正确类中驱除,这是基于梯度上升的输入修改所产生的;而在目标攻击中,由于基于梯度下降的输入修改,对抗样本下的输出会朝向目标类。
BIM. BIM算法实际上是上述FGSM的迭代版本,它以迭代的方式更新对抗样本,直到攻击成功。在BIM中,对抗样本的产生受下式控制:
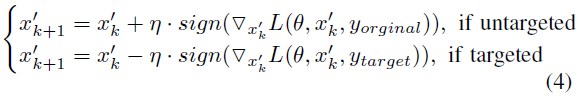
其中 i 是迭代索引。具体来说,当k=0时,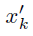 等于原始输入,即
等于原始输入,即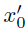 。
。
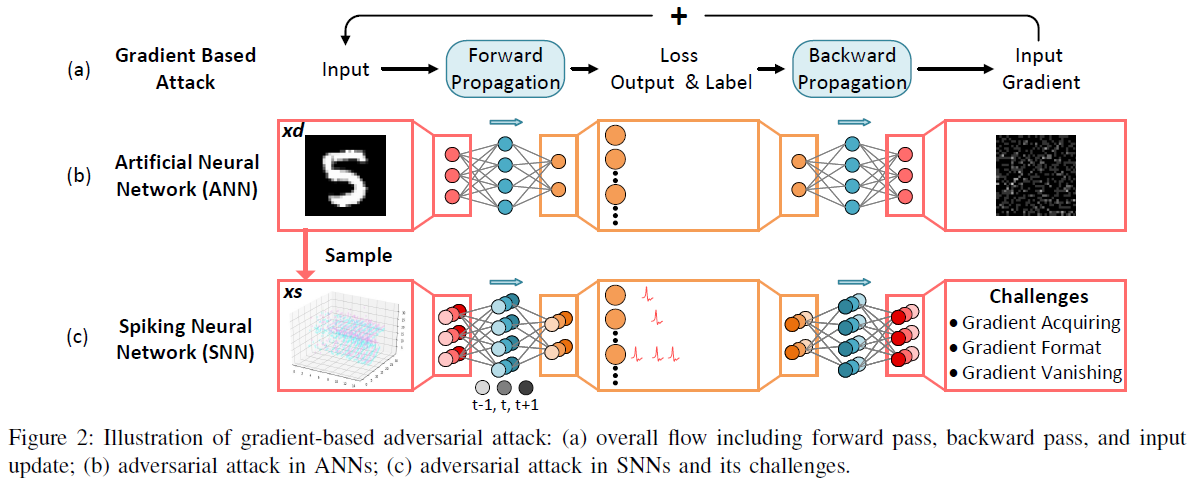
III. CHALLENGES IN SNN ATTACK
图2(a)简要说明了对抗攻击的工作流程。这里有三个阶段:前向传递以得到模型预测、后向传递以计算输入梯度和输入更新以产生对抗样本。这个流程很容易在ANN中实现,如图2(b)所示,这与ANN训练非常相似。唯一的区别在于输入更新代替了常规ANN训练中的参数更新。然而,在SNN场景中情况变得复杂,处理基于具有时间动态的二值脉冲,而不是具有立即响应的连续激活。根据图2(c),我们试图确认SNN攻击中的挑战,以区别于ANN攻击,并将我们的解决方案与以下小节中的先前研究进行比较。
A. Challenges and Solutions
Acquiring Spatio-temporal Gradients. 在前馈神经网络中,激活和梯度只涉及空间维度而不涉及时间成分。对于每个特征图,其反向传播过程中的梯度仍为二维形状。然而,由于额外的时间维度,每个梯度图在SNN中变为三维。传统的SNN学习算法很难获得时空梯度。例如,无监督学习规则,如脉冲时间依赖可塑性(STDP)[24]根据局部神经元的活动更新突触,而不计算监督梯度;ANN到SNN的转换学习方法[25]只是将SNN学习问题转换为ANN学习问题,导致无法捕获时间梯度。近年来,基于时间反向传播(BPTT)启发的学习算法[2, 5, 29, 32]得到了广泛的研究,以提高SNN的准确性。这种新出现的监督学习通过直接获取空间和时间两个维度的梯度来保证SNN攻击的准确性。
Incompatible Format between Gradients and Inputs. 输入梯度是连续值,而SNN输入是二值脉冲(参见图2(c)的左边,每个点代表一个脉冲事件,即“1”;否则为“0”)。如果考虑到传统的梯度累积,这种数据格式的不兼容性阻碍了基于脉冲的对抗样本生成。在这项工作中,我们提出一个梯度-脉冲(G2S)转换器,以将连续梯度转换为脉冲兼容的三元梯度。该设计采用了概率采样、符号提取和溢出感知变换,能够保持脉冲格式并控制扰动幅度。
Gradient Vanishing Problem. 如等式(1)所述,LIF神经元的阈值脉冲发放实际上是一个不可微的阶跃函数。为了解决这个问题,引入了类似狄拉克函数来近似发放活动的导数[29]。然而,这种近似会在梯度窗口外产生大量的零梯度(后文将给出),导致反向传播过程中严重的梯度消失。我们发现,有时输入的梯度图可能都为零,这会中断对抗样本基于梯度的更新。为此,我们提出了一个梯度触发器(GT)来构造三元梯度,在全零梯度的情况下可以随机翻转二值输入。我们使用一个基准采样因子来限制整体翻转率,使扰动幅度可控。
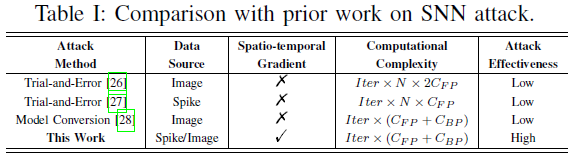
B. Comparison with Prior Work on SNN Attack
对SNN攻击的研究尚不多见,尚处于起步阶段。关于这个话题,我们只找到了一些相关的工作。在本小节中,我们总结了他们的方法,并澄清了我们与他们之间的差异。
Trial-and-Error Input Perturbation. 这种攻击算法通过监视输出的变化以试错的方式干扰输入。例如,A.Marchisio et al.[26]在脉冲采样之前修改原始图像输入。他们首先在图像中选择一个像素块,然后在每个像素上添加一个正或负的单位扰动。在这个过程中,他们总是监视输出变化以确定扰动,直到攻击成功或扰动超过阈值。然而,这种基于图像的扰动不适合仅具有脉冲事件的数据源[33, 34]。相比之下,A.Bagheri et al.[27]直接干扰脉冲输入,而不是原始图像输入。其主要思想是翻转脉冲输入并监视输出。
SNN/ANN Model Conversion. S.Sharmin et al.[28]将SNN攻击问题转化为ANN攻击问题。他们首先建立了一个具有相同网络结构且从训练的SNN模型复制参数的ANN替代模型。然后在建立的ANN模型上进行基于梯度的对抗攻击,生成对抗样本。
这些现有的工作有几个缺点,最终会降低攻击的有效性。对于试错输入扰动法,由于没有监督梯度的引导,搜索空间大,计算复杂度较高。具体地说,输入的每个选定元素需要运行前向通过一次(对于脉冲扰动)或两次(对于图像扰动)来监视输出。计算总复杂度为Iter×N×CFP,其中Iter为攻击迭代次数,N为搜索空间大小,CFP为每一次前向通过的计算代价。这一复杂度远高于通常的复杂度,Iter×(CFP+CBP),这是由于N较大。在如此大的空间内很难找到最优扰动,在有限的搜索时间内,攻击效果不能令人满意。对于SNN/ANN模型转换方法,在SNN到ANN的转换过程中需要额外的模型转换和时间信息的聚合。使用不同的模型作为替代模型,时间成分的缺失最终会影响攻击的有效性。此外,这种方法不适用于没有额外信号转换的无图像脉冲数据源。
与以上只是规避SNN攻击问题的工作相比,我们直接接触到它,有助于揭示攻击SNN的过程。在不需要额外模型转换的情况下,我们计算了空间和时间维度上的梯度,这与SNN的自然行为相匹配。其结果是,可以凭借监督的方式获取时空输入梯度,为有效攻击奠定基础。然后,我们所提出的G2S和GT使得即使在遇到梯度消失的情况下,也能基于连续梯度生成脉冲对抗样本。这种直接生成的脉冲对抗样本使我们的方法适合于无图像脉冲数据源。对于使用基于图像的数据源的SNN模型,我们的解决方案也适用于时空梯度的简单时间聚集。总之,表I显示了我们的工作和以前的工作之间的差异。
请注意,本文的重点是白盒攻击。具体来说,在白盒攻击场景下,敌方知道受害者模型的网络结构和模型参数(如权重、uth等)。这种场景选择的原因在于白盒攻击是理解对抗攻击的基本步骤,更适合于研究SNN直接对抗攻击的第一步工作。此外,为白盒攻击所建立的方法可以在将来很容易地迁移到黑盒攻击。
IV. ADVERSARIAL ATTACKS AGAINST SNNS
在这一部分中,我们首先简要介绍输入数据格式,然后详细说明我们的攻击方法的流程、方法和算法。
Input Data Format. SNN模型处理脉冲信号是很自然的。因此,考虑到包含脉冲事件的数据集,例如N-MNIST[33]和CIFAR10-DVS[34],这是首选。在这种情况下,输入最初是一个时空模式,每个元素有一个二进制值(0-nothing;1-spike)。攻击者可以翻转选定元素的状态,但必须保持二进制格式。由于现实中缺少脉冲数据源,图像数据集通过将其转换为脉冲版本,也被广泛应用于SNN领域[5, 39]。Bernoulli采样[2]是将像素强度转换为脉冲序列的常用方法(回忆图2中的“采样”),其中脉冲rate与强度值成正比。在这种情况下,攻击者可以通过添加连续扰动来修改选定像素的强度值。图3展示了这两个案例中的对抗样本。

A. Attack Flow Overview
图4显示了针对SNN所提出的对抗攻击的概述。基本流程采用等式(4)中给出的BIM方法,这是在考虑SNN的脉冲输入后的结果。脉冲的扰动只能翻转选定输入元素的二值状态(0或1),而不能添加连续值。因此,为了生成能够跨越决策边界的脉冲对抗样本,候选元素的搜索比扰动量更为重要。FGSM不能做到这一点,因为它只探索扰动的大小,而BIM通过在不同的迭代中搜索新的候选元素来实现这一点。
如前所述,有三个阶段:前向通过(FP)、后向通过(BP)和输入更新,这三个阶段迭代执行,直到攻击成功。这里的梯度是一个时空模式,这与SNN的时空动态相匹配,使其具有更高的攻击效率。此外,提出的梯度-脉冲(G2S)转换器解决了连续梯度和二值输入之间的不相容性,并用梯度触发器(GT)解决了梯度消失问题。接下来,我们分别描述了脉冲输入和图像输入的具体流程,以便清晰地理解。
Spiking Inputs. 图4中的蓝色箭头说明了这种情况。脉冲对抗样本的产生依赖于以下三个步骤。在步骤1中,通过下式计算FP和BP阶段的连续梯度:
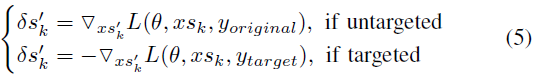
其中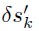 表示第k次迭代时的输入梯度图。由于中的所有元素都是连续值,因此它们不能直接累积到脉冲输入(即xsk)上,以避免破坏二值脉冲的数据格式。因此,在步骤2中,我们提出了G2S转换器,将连续梯度图转换成与脉冲输入兼容的三元梯度图,这样可以同时保持输入数据格式和控制扰动幅度。当输入梯度消失(即中的所有元素均为零)时,我们提出GT构造一个三元梯度图,它能够以可控的翻转率随机翻转脉冲输入。最后,步骤3将三元梯度累加到脉冲输入上。
表示第k次迭代时的输入梯度图。由于中的所有元素都是连续值,因此它们不能直接累积到脉冲输入(即xsk)上,以避免破坏二值脉冲的数据格式。因此,在步骤2中,我们提出了G2S转换器,将连续梯度图转换成与脉冲输入兼容的三元梯度图,这样可以同时保持输入数据格式和控制扰动幅度。当输入梯度消失(即中的所有元素均为零)时,我们提出GT构造一个三元梯度图,它能够以可控的翻转率随机翻转脉冲输入。最后,步骤3将三元梯度累加到脉冲输入上。
Image Inputs. 有时,基准模型通过Bernoulli采样将图像数据集转换为脉冲输入。在这种情况下,还需要一个步骤来生成图像风格的对抗样本,如图4中的红色箭头所示。在上述步骤2之后,三元梯度图应在时间维度上聚合,即根据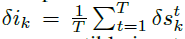 ,对属于同一空间位置但在不同时间步骤中的所有元素进行平均。在该时间聚合之后,可获得与图像兼容的输入扰动。注意,在每次更新迭代中,xik的强度值将裁剪到[0, 1]。
,对属于同一空间位置但在不同时间步骤中的所有元素进行平均。在该时间聚合之后,可获得与图像兼容的输入扰动。注意,在每次更新迭代中,xik的强度值将裁剪到[0, 1]。
B. Acquisition of Spatio-Temporal Gradients
我们介绍了SNN的最新监督学习算法[5, 29, 31],这些算法受到时间反向传播(BPTT)的启发,可以获得空间和时间维度上的梯度。这里我们以[5]中的一个为例。为了在现有的程序设计框架(如Pytorch)中进行模拟,首先将等式(1)中的原LIF神经元模型转换为等价的迭代模型。具体来说,我们有下式:

其中t和n分别表示模拟时间步骤和层的指标,dt是时间步长,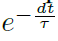 反映膜电位的泄漏效应。fire(·)是一个阶跃函数,当x≥0时满足fire(x)=1,否则fire(x)=0。这个迭代LIF模型包含了一个脉冲神经元的所有行为,包括积分、发放和复位。
反映膜电位的泄漏效应。fire(·)是一个阶跃函数,当x≥0时满足fire(x)=1,否则fire(x)=0。这个迭代LIF模型包含了一个脉冲神经元的所有行为,包括积分、发放和复位。
然后,基于梯度下降的监督学习需要一个损失函数L。脉冲rate编码广泛用于将输出层的时空脉冲模式转换为脉冲rate矢量,描述为下式:
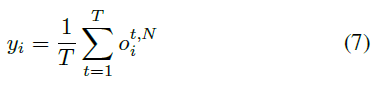
其中N是输出层索引,T是模拟时间窗口的长度。在ANN中,这个脉冲rate矢量可以看作是正常的输出矢量。通过这种输出转换,ANN的典型损失函数,如均方误差(MSE)和交叉熵(CE)也可以用作SNN的损失函数。
基于迭代LIF神经元模型和给定的损失函数,梯度传播可以由下式控制:

但是,发放函数是不可微的,即 不存在。如前所述,引入类似狄拉克函数来近似其导数[29]。具体来说,可以通过下式估计:
不存在。如前所述,引入类似狄拉克函数来近似其导数[29]。具体来说,可以通过下式估计:

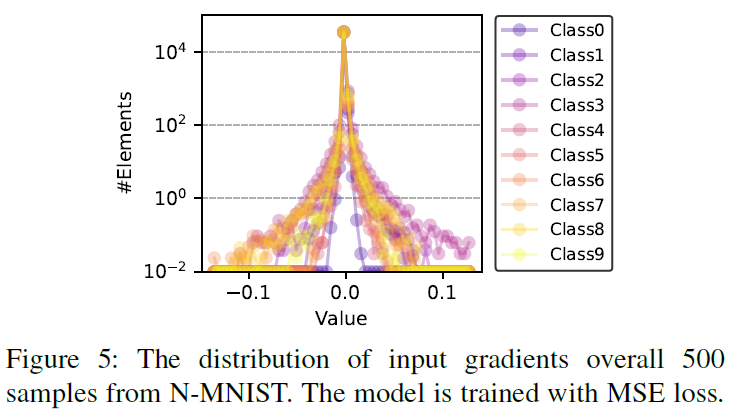
其中a是一个超参数,用于在反向传播期间传递发放函数时控制梯度宽度。这种近似表示只有膜电位接近发放阈值的神经元才有机会让梯度通过,如图5所示。可以看出,大量的零梯度产生,这可能导致梯度消失问题(所有输入梯度变为零)。
C. Gradient-to-Spike (G2S) Converter
在每次迭代中,G2S转换器的设计有两个目标:(1)最终梯度应与脉冲输入相兼容,即梯度累积后保持脉冲格式不变;(2)扰动幅度应不可察觉,即限制非零梯度的数目。为此,我们设计了三个步骤:概率采样、符号提取和溢出感知变换,如图6所示。
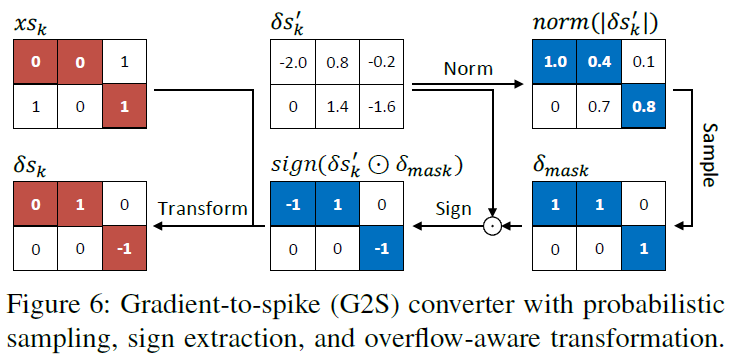
Probabilistic Sampling. 由等式(5)得到的输入梯度图的绝对值,即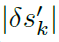 ,首先被归一化到[0, 1]的范围内。然后,对归一化梯度图,即范数()进行采样,生成具有相同形状的二值掩模,其中1表示梯度可以通过的位置。每个梯度元素的概率采样服从下式:
,首先被归一化到[0, 1]的范围内。然后,对归一化梯度图,即范数()进行采样,生成具有相同形状的二值掩模,其中1表示梯度可以通过的位置。每个梯度元素的概率采样服从下式:
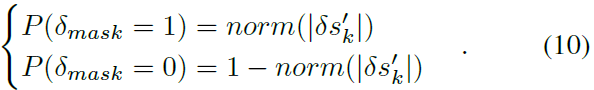
换句话说,较大的梯度有较大的可能性让梯度通过。通过将生成的掩模与原始梯度图相乘,可以显著减少非零元素的数量。为了证明这一结论,我们使用表V中提供的网络结构对来自N-MNIST的500个脉冲输入对SNN模型进行攻击,结果如图7所示。在MSE损失和无目标攻击的情况下,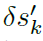 中的非零元素数目可以达到210个。采用概率采样后,可以大大减少
中的非零元素数目可以达到210个。采用概率采样后,可以大大减少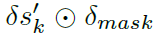 中非零元素的数量,掩模率>96%。
中非零元素的数量,掩模率>96%。

Sign Extraction. 现在,我们将解释如何生成一个三元梯度图,其中每个元素都在{-1, 0, 1}中,它可以在累加到二进制值为{0, 1}的脉冲输入后保持脉冲格式。此步骤仅基于符号提取:
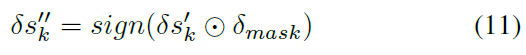
其中,如果x>0,则定义sign(x) = 1;如果x=0,则sign(x) = 0;否则sign(x) = -1。
Overflow-aware Transformation. 虽然上述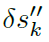 可以是三元的,但它不能保证由输入梯度累加产生的最终对抗样本仍然局限于{0, 1}。例如,xsk中具有“-1”梯度的原始“0”元素或具有“1”梯度的原始“1”元素将产生{0, 1}之外的“-1”或“2”输入。此溢出破坏了二值脉冲的数据格式。为了解决这个问题,我们提出了一个溢出感知梯度变换来限制最后一个对抗样本的范围,如表II所示。
可以是三元的,但它不能保证由输入梯度累加产生的最终对抗样本仍然局限于{0, 1}。例如,xsk中具有“-1”梯度的原始“0”元素或具有“1”梯度的原始“1”元素将产生{0, 1}之外的“-1”或“2”输入。此溢出破坏了二值脉冲的数据格式。为了解决这个问题,我们提出了一个溢出感知梯度变换来限制最后一个对抗样本的范围,如表II所示。

在介绍了上述三个步骤之后,现在可以将G2S转换器的函数简要总结如下:

其中transform(·)表示溢出感知变换。通过同时保持脉冲兼容和控制扰动幅度,G2S转换器能够实现上述两个目标。
D. Gradient Trigger (GT)
表III确定了由BPTT训练的SNN中的梯度消失问题,这是相当严重的。设计GT的目的是通过人工构造梯度来解决梯度消失问题。所构造的梯度图的约束条件与G2S转换器相同,即脉冲格式相容性和扰动幅度可控性。为此,我们设计了两个步骤:元素选择和梯度构造,如图8所示。

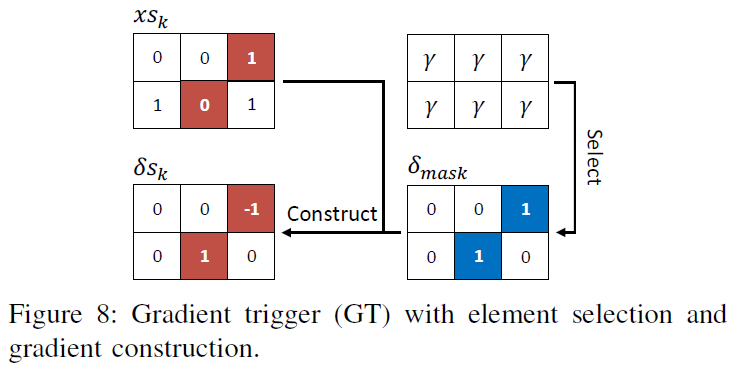
Element Selection. 这一步是选择让脉冲通过的元素。在G2S转换器中,概率采样用于产生二值掩模来指示单元的选择,而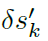 中的所有梯度在这里都是零。为了继续使用上述概率采样方法,我们提供了一个梯度初始化,将所有元素设置为γ,如图8所示。γ是在[0, 1]范围内的一个因子,它控制GT后非零梯度的数量。现在等式(10)中的概率采样仍然适用于生成掩模δmask。
中的所有梯度在这里都是零。为了继续使用上述概率采样方法,我们提供了一个梯度初始化,将所有元素设置为γ,如图8所示。γ是在[0, 1]范围内的一个因子,它控制GT后非零梯度的数量。现在等式(10)中的概率采样仍然适用于生成掩模δmask。
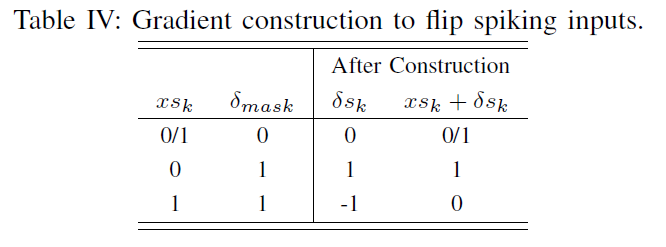
Gradient Construction. 为了保持对抗样本的脉冲格式,我们只需翻转所选区域中脉冲输入的状态。这里,翻转意味着如果当前元素状态为“1”,则将其切换为“0”,反之亦然。表IV说明了能够翻转脉冲输入的三元梯度的构造。
通过以上两个步骤,可以在很好地控制整体翻转率的情况下随机翻转脉冲输入。GT的总体函数可以表示为下式:
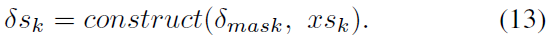
总而言之,GT继续更新被梯度消失打断的对抗样本。
E. Overall Attack Algorithm
根据G2S转换器和GT的说明,算法1提供了与图4所示攻击流程相对应的总体攻击算法。对于不同的输入数据格式,我们给出了生成对抗样本的不同方法。我们的算法有几个超参数,如最大攻击迭代次数(Iter)、量化扰动幅度||δ||p的范数格式(p)、扰动幅度上界(ε)、梯度缩放率(η)和GT中的采样因子(γ)。

V. LOSS FUNCTION AND FIRING THRESHOLD
在这项工作中,我们考虑了两个影响SNN攻击效果的设计旋钮:训练过程中的损失函数和攻击过程中倒数第二层的发放阈值。
A. MSE and CE Loss Functions
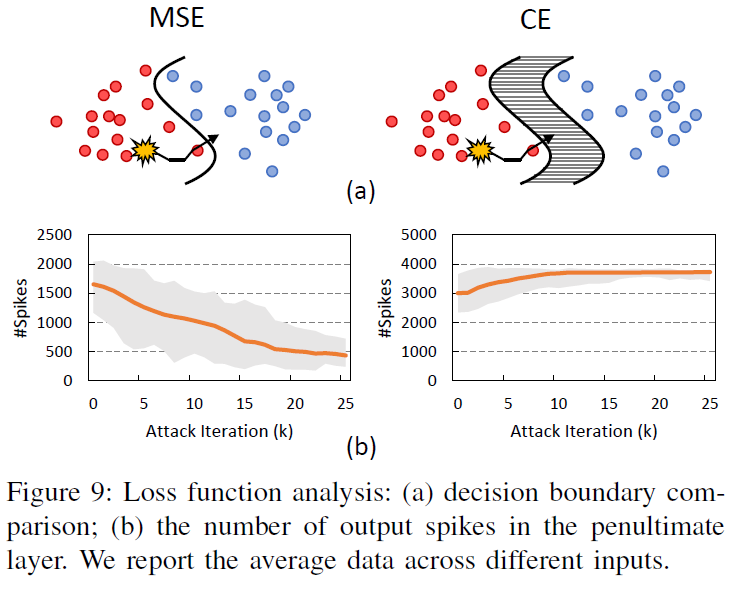
比较了两种常用的损失函数:均方误差(MSE)损失和交叉熵(CE)损失。前者直接接收输出层的发放率,后者则需要一个额外的softmax层在输出的发放率之后。我们观察到,当模型使用CE损失进行训练时,梯度消失的发生率更高。在这种情况下,似乎存在一个“陷阱”区域,这意味着无论GT如何修改输入,输出神经元都无法再改变响应。我们使用图9(a)来说明我们的发现。在训练过程中使用CE损失时,梯度通常在决策边界(即阴影区域)之间消失,GT无法恢复,而使用MSE损失时,这种现象很少发生。
为了加深理解,我们检查倒数第二层的输出模式(在非目标攻击期间),因为它直接与输出层交互,如图9(b)所示。在这里,网络结构将在表V中提供,500个测试输入是从N-MNIST数据集中随机选择的。当训练损失为MSE时,随着攻击过程的发展,倒数第二层输出脉冲数逐渐减少。相反,CE训练模型的脉冲数先增加后保持不变。基于这一观察,一个可能的假设是在倒数第二层有更多的输出脉冲可能增加决策边界之间的距离,从而引入梯度消失的“陷阱”区域。
B. Firing Threshold of the Penultimate Layer
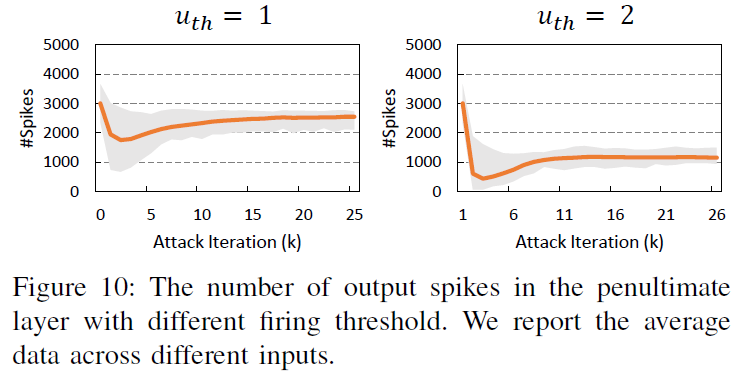
如上所述,由CE损失训练的模型容易在倒数第二层输出更多的脉冲,从而导致“陷阱”区域使攻击变得困难。为了解决这个问题,我们在攻击期间增加倒数第二层的发放阈值,以减少那里的脉冲数。具体来说,我们只在FP阶段修改发放阈值(参见图4)。结果如图10所示,其中使用了CE损失,其他设置与图9(b)中的相同。与先前实验中的初始阈值设置(uth=0.3)相比,倒数第二层的输出脉冲数可以显著减少。第VI-D节的后一个实验将证明,这种发放阈值的调整能够提高对抗攻击的有效性。
VI. EXPERIMENT RESULTS
A. Experiment Setup
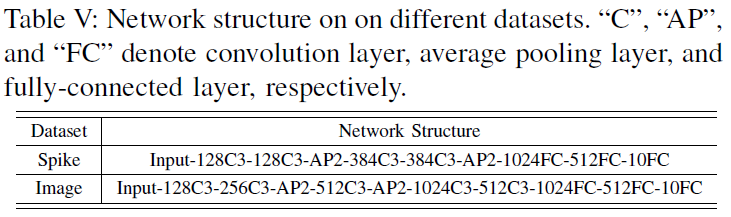
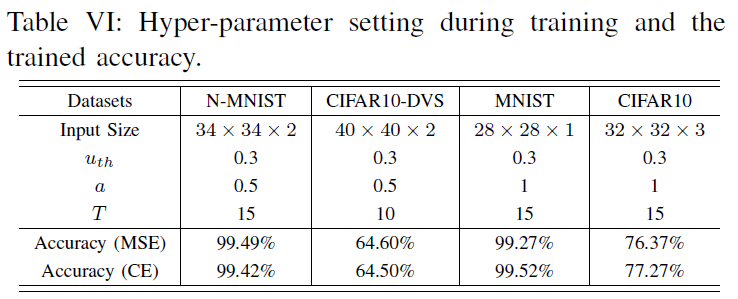
我们设计了在脉冲和图像数据集上的实验。脉冲数据集包括动态视觉传感器捕获的N-MNIST[33]和CIFAR10-DVS[34];而图像数据集包括MNIST[35]和CIFAR10[36]。对于这两种数据集,我们使用不同的网络结构,如表V所示。对于每个数据集,训练期间的详细超参数设置和训练精度如表VI所示。除非另有说明,否则默认的损失函数为MSE。注意,由于我们在这项工作中关注的是攻击方法,因此我们没有使用优化技术,如输入编码层、神经元规范化和基于投票的分类[5]来提高训练精度。
我们将对抗攻击的最大迭代次数(即算法1中的Iter)设置为25。我们在10个类中随机选择50个输入用于非目标攻击,在每个类中随机选择10个输入用于目标攻击。注意,只有模型能够正确识别的输入才会被选择进行攻击。在目标攻击中,我们将目标设置为除真实值外的所有类。我们使用攻击成功率和扰动幅度(即||δ||p)作为评估攻击效果的两个指标。我们分别在具有脉冲输入和图像输入的场景中设置p=1和p=2。
B. Influence of G2S Converter
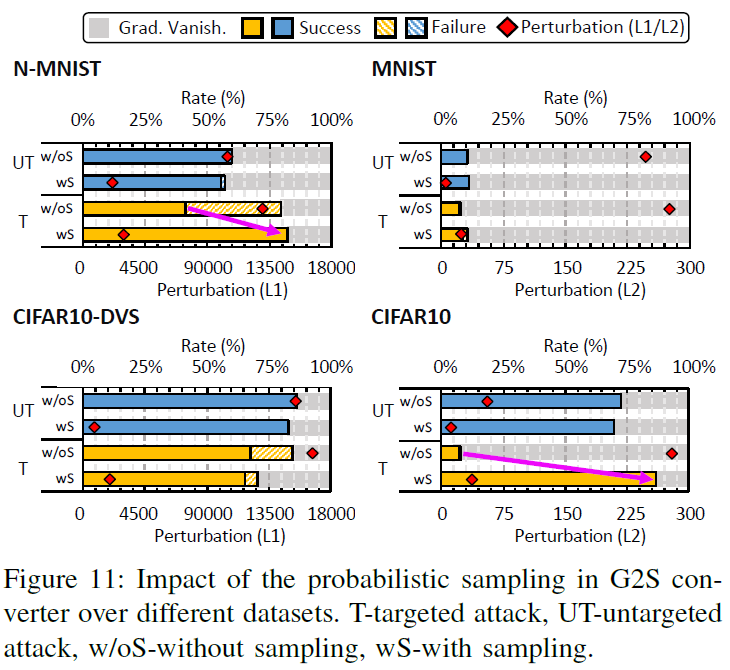
我们首先验证了G2S转换器的有效性。在第IV-C节所述的G2S转换器的三个步骤(即概率采样、符号提取和溢出感知变换)中,必须使用后两个步骤来解决脉冲兼容性,而第一个步骤仅用于控制扰动幅度。因此,我们研究了G2S转换器中的概率采样对攻击效果的影响。请注意,在本小节中,我们不使用GT来解决梯度消失问题。
图11显示了在有或无概率采样的四个数据集上攻击结果的比较(例如成功/失败率、梯度消失率和扰动幅度)。对非目标攻击和目标攻击,我们都进行了测试。我们提供以下几点意见。首先,目标攻击所需的扰动幅度高于非目标攻击,目标攻击的成功率通常低于非目标攻击。这些结果反映了目标攻击的难度,需要将输出准确地移动到预期类。其次,概率采样可以在所有情况下显著降低扰动幅度,因为它消除了许多小的梯度。最后,由于改进的攻击收敛性和较小的扰动,通过采样优化可以在很大程度上提高大多数数据集的成功率(尤其是较难的目标攻击)。在概率采样的情况下,如果梯度不消失,攻击失败率可以降到几乎为零。
C. Influence of GT
然后,我们验证了该方法的有效性。在GT中,超参数γ控制所选元素的数量,从而影响扰动幅度。请记住,较大的γ表示通过翻转脉冲输入中更多元素的状态而产生的较大扰动。
我们首先分析γ对攻击成功率和扰动幅度的影响,如图12所示。第VI-B节中观察到的类似结论也认为,目标攻击比非目标攻击更困难。随着γ的减小,具有翻转状态的元素的数目减少,从而导致较小的扰动。然而,γ对攻击成功率的影响很大程度上取决于攻击场景和数据集。对于更容易的无目标攻击,似乎一个稍小的γ已经有所帮助。即使γ=0.01,攻击成功率也将饱和接近100%。对于难度较大的目标攻击,在γ=0.05的数据集上似乎存在明显的成功率峰值。结果是合理的,因为γ的影响是双重的:i)过大的γ将导致较大的扰动幅度和非收敛攻击;ii)过小的γ不能将模型移出梯度消失的区域。

我们还记录了不同γ设置下的触发次数,如图13所示。这里的“触发次数”是指在攻击过程中发生梯度消失的迭代次数。我们报告不同输入样本的平均值。当γ较大时,由于扰动大到足以将模型推出梯度消失区域,因此触发次数只能是一次。当γ变小时,所需的触发次数就变大。为了平衡攻击成功率(见图12)和触发时间(见图13),我们最后建议在测试的数据集上设置GT中的γ=0.05。在实际应用中,应根据实际需要重新探索理想的设置。

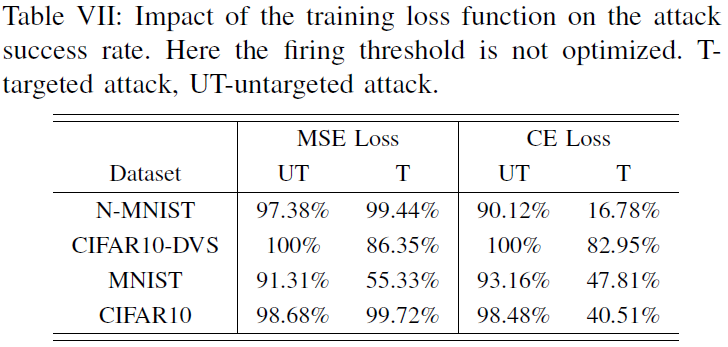
D. Influence of Loss Function and Firing Threshold
此外,我们还评估了不同训练损失函数对攻击成功率的影响。表VII总结了比较情况。此时G2S转换器和GT被打开。与MSE损失训练模型相比,CE损失训练模型的攻击成功率较低,且在目标攻击情况下差距特别大。如第V节所述,这反映了在攻击过程中,由于倒数第二层的脉冲活动增加,由CE损失训练的模型的“陷阱”区域。
为了提高攻击效果,我们在攻击过程中增加倒数第二层的发放阈值,以稀疏化脉冲活动。实验结果如图14所示。对于非目标攻击,提高发放阈值可以使所有数据集的攻击成功率提高到近100%。针对目标攻击,案例呈现不同的行为。具体地说,在图像数据集(即MNIST和CIFAR10)上,攻击成功率可以迅速提高并保持在100%左右;而在脉冲数据集(即N-MNIST和CIFAR10-DVS)上,攻击成功率先升高后降低,即存在一个最佳阈值设置。这可能是由于神经形态数据集的稀疏事件性质,如果发放阈值足够大,注入最后一层的脉冲数量将严重减少,从而导致固定的损失值,因此会降低攻击成功率。此外,从扰动分布可以看出,在大多数情况下,发放阈值的增加不会引入额外的扰动。以上结果表明,适当提高倒数第二层的发放阈值,可以在不增加扰动的情况下显著提高攻击效果。

E. Effectiveness Comparison with Existing SNN Attack
如第III-B节所述,我们的攻击与以前使用试错输入扰动[26, 27]或SNN/ANN模型转换[28]的工作完全不同。除了方法上的差异,这里我们粗略地讨论了攻击的有效性。由于试错方式的高度复杂性,测试数据集非常小(例如USPS数据集[26]),甚至只有一个样本[27]。相比之下,我们展示了对更大数据集(包括MNIST、CIFAR10、N-MNIST和CIFAR10-DVS)的有效对抗攻击。对于SNN/ANN模型转换方法[28],作者在MNIST数据集上给出了结果。然而,最高的非目标攻击成功率和目标攻击成功率分别只有约75%和65%(根据[28]中的数字推断)。相比之下,我们的攻击成功率在大多数情况下可以达到99%以上。N-MNIST的CE训练失败率最高,仅为81.44%(见图14(a)),但这是首次报道。总的来说,我们的工作为基于SNN的对抗攻击提供了最多的测试数据集,并取得了最好的效果。
F. Effectiveness Comparison with ANN Attack
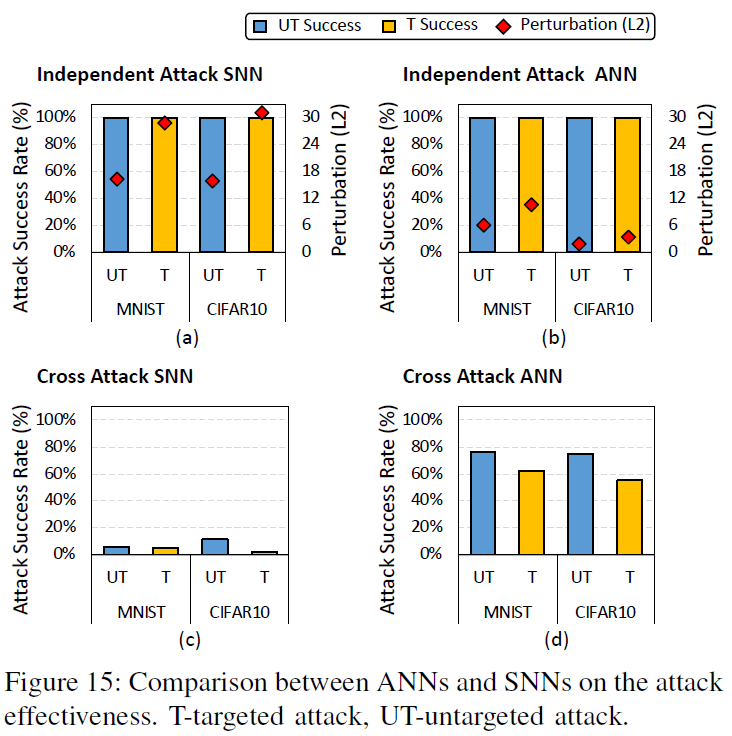
在本小节中,我们进一步比较了SNN和ANN对基于图像的数据集MNIST和CIFAR10的攻击有效性。对于ANN模型,我们使用与表V中给出的SNN模型相同的网络结构。这里的训练损失函数是CE。我们测试了两种攻击场景:独立攻击和交叉攻击。对于独立攻击,使用等式(4)中的BIM方法攻击ANN模型;而使用我们所提出的方法攻击SNN模型。注意,如图14所示,攻击期间SNN模型倒数第二层的发放阈值在本小节中设置为2。对于交叉攻击,我们使用攻击SNN模型产生的对抗样本来误导ANN模型,反之亦然。
从图15(a)-(b),我们可以很容易地观察到,在独立攻击场景中,所有攻击成功率都相当高。而攻击SNN模型比攻击ANN模型需要更多的扰动,这反映了SNN模型具有更高的健壮性。从图15(c)-(d)中的交叉攻击的结果中,我们发现利用攻击ANN模型生成的对抗样本来欺骗SNN模型是非常困难的,成功率只有<12%。这进一步有助于得出结论,攻击SNN模型比攻击具有相同网络结构的ANN模型更难。
VII. CONCLUSION AND DISCUSSION
SNN因其对脑启发计算的重要性而引起了广泛的关注,并被广泛应用于神经形态设备中。当然,SNN的安全问题应该被考虑。在这项工作中,我们选择了对由类似BPTT的监督学习训练的SNN的对抗攻击作为出发点。首先,我们确定了攻击SNN模型的挑战,即脉冲输入与连续梯度之间的不相容性,以及梯度消失问题。其次,我们分别设计了一个具有概率采样、符号提取和溢出感知变换的梯度-脉冲(G2S)转换器和一个具有元素选择和梯度构造的梯度触发器(GT)来解决上述两个挑战。我们的方法可以很好地控制扰动幅度,适用于脉冲和图像数据格式。有趣的是,我们发现在由CE损失训练的SNN模型中存在一个“陷阱”区域,可以通过调整倒数第二层的发放阈值来克服。我们在MNIST、CIFAR10、N-MNIST和CIFAR10-DVS等数据集上进行了广泛的实验,大多数情况下攻击成功率达99%以上,是SNN攻击的最佳结果。我们深入分析了G2S转换器、GT、损失函数、发放阈值等因素的影响。此外,我们还比较了SNN和ANN的攻击,揭示了SNN之于对抗攻击的健壮性。我们的发现有助于理解SNN攻击,并能促进更多的神经形态计算的安全性研究。
对于以后的工作,我们推荐几个有趣的课题。虽然我们只研究白盒对抗攻击,以避免转移我们方法论的重点,但黑盒对抗攻击更具实用性,因此应该加以研究。幸运的是,本文提出的方法可以迁移为黑盒攻击场景。其次,由于页数限制,我们只分析了损失函数和发放阈值的影响。发放活动的梯度逼近形式、rate编码的时间窗口长度或编码方案本身、网络结构等因素是否会影响攻击效果,仍然是一个悬而未决的问题。再者,对物理神经形态设备的攻击比起仅是理论模型更具吸引力。最后,与攻击方法相比,对于大规模神经形态系统的构建,防御技术受到更高的期待。
Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient的更多相关文章
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- A review of learning in biologically plausible spiking neural networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Contents: ABSTRACT 1. Introduction 2. Biological background 2.1. Spik ...
- Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks
目录 概 主要内容 算法 一些有趣的指标 鲁棒性定义 合格的抗干扰机制 Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, Ananthram ...
- Inherent Adversarial Robustness of Deep Spiking Neural Networks: Effects of Discrete Input Encoding and Non-Linear Activations
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2003.10399v2 [cs.CV] 23 Jul 2020 ECCV 2020 1 https://github.com ...
- Learning in Spiking Neural Networks by Reinforcement of Stochastic Synaptic Transmission
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Summary 众所周知,化学突触传递是不可靠的过程,但是这种不可靠的函数仍然不清楚.在这里,我考虑这样一个假设,即大脑利用突触传递的随机 ...
- NeuroAttack: Undermining Spiking Neural Networks Security through Externally Triggered Bit-Flips
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2005.08041v1 [cs.CR] 16 May 2020 Abstract 由于机器学习系统被证明是有效的,因此它被广 ...
- Combining STDP and Reward-Modulated STDP in Deep Convolutional Spiking Neural Networks for Digit Recognition
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 灵长类视觉系统激发了深度人工神经网络的发展,使计算机视觉领域发生了革命性的变化.然而,这些网络的能量效率比它们的生物学对 ...
- 提高神经网络的学习方式Improving the way neural networks learn
When a golf player is first learning to play golf, they usually spend most of their time developing ...
- One Pixel Attack for Fooling Deep Neural Networks
目录 概 主要内容 问题描述 Differential Evolution (DE) 实验 Su J, Vargas D V, Sakurai K, et al. One Pixel Attack f ...
随机推荐
- Window版本的Python安装库大全
1. 位置 python的pip安装包网站 https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载方法 wget https://download.lfd.uci ...
- zookeeper 源码编译
环境:mac 1.github上下载 源码 项目地址:https://github.com/apache/zookeeper 2.安装 ant mac:brew update -> brew ...
- 线程_multiprocessing实现文件夹copy器
import multiprocessing import os import time import random def copy_file(queue,file_name,source_fold ...
- 1-Numpy的通用函数(ufunc)
一.numpy“通用函数”(ufunc)包括以下几种: 元素级函数(一元函数):对数组中的每个元素进行运算 数组级函数:统计函数,像聚合函数(例如:求和.求平均) 矩阵运算 随机生成函数 常用一元通用 ...
- Python basestring() 函数
描述 basestring() 方法是 str 和 unicode 的超类(父类),也是抽象类,每组词 www.cgewang.com 因此不能被调用和实例化,但可以被用来判断一个对象是否为 str ...
- MySQL选错索引导致的线上慢查询事故
前言 又和大家见面了!又两周过去了,我的云笔记里又多了几篇写了一半的文章草稿.有的是因为质量没有达到预期还准备再加点内容,有的则完全是一个灵感而已,内容完全木有.羡慕很多大佬们,一周能产出五六篇文章, ...
- Win10系统安装MySQL Workbench 8
系统:Window10 专业版 MySQL Workbench 8.0.19 下载地址:https://dev.mysql.com/downloads/workbench/8.0.html 点击Dow ...
- Maven 配置编译版本
pom.xml <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</gro ...
- 8 Java 条件逻辑语句
生活中,我们经常需要先做判断,然后才决定是否要做某件事情.例如,在上学的时候,如果期末考试成绩在全校能拿到前100名,则奖励一个 iPhone 11 .对于这种“需要先判断条件,条件满足后才执行的情况 ...
- 【工具】之002-Mac下常用工具
写在前面 我很懒,,,不想敲一个命令一个命令敲... "偷懒是有前提的,不是之前,就是之后." 常用命令 测试端口是否畅通 nc -z 10.254.3.86 30003 查看端口 ...