基于CPU版本的Caffe推理框架
最近一段时间,认真研究了一下caffe。但是,里面内容过多,集合了CPU版本和GPU版本的代码,导致阅读起来有些复杂。因此,特意对caffe代码进行了重构,搭建一个基于CPU版本的Caffe推理框架。
此简化的Caffe推理框架具有以下特点:
- 只有CPU推理功能,无需GPU;
- 只有前向计算能力,无后向求导功能;
- 接口保持与原版的Caffe一致;
- 精简了大部分代码,并进行了详尽注释。
通过对Caffe的重构,理解了如何搭建一个推理框架,如何从输入一张图片从而得到结果。注意:此框架只是用于教学使用,通过最简单的图片分类的方式来理解框架,不保证适合不同的任务。
项目地址为:https://gitee.com/dengshunge/simple-caffe-inference
一、SimpleCaffe的结构
SimpleCaffe中保持了与原版caffe同样的代码结构,整体结构始终贯穿着Blob、Layer和Net这3大类,分别负责数据的存储、网络的层次和网络骨架:
- Blob:负责数据的传输,其中数据主要包括每层的输入输出数据、模型的权重等;
- Layer:负责构建模型的每一层,主要处理如何将该层的输入转换成输出;
- Net:负责搭建网络的骨架,将每层Layer进行组合。
其主要结构图如下所示
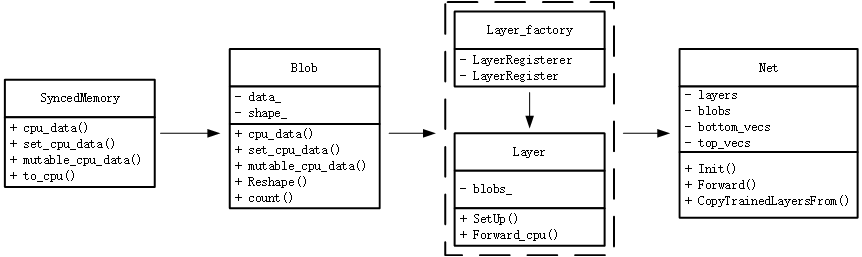
在SyncedMemory中,其主要负责CPU数据与GPU数据进行同步(此版本没有GPU,只是保留接口),其主要包含4个函数,分别用于读取CPU常量数据、设置CPU数据、获取CPU可变数据和将数据同步至CPU。
在Blob中,有两个重要的变量:$data\_$表示存储的数据,包括模型权重和每层的计算结果;$shape\_$表示这些数据的形状shape。而函数则包含:
- $Reshape()$根据传入的shape信息,通过调用SyncedMemory来为$data\_$分配内存空间;
- $count()$表示切片的容量,如果不传入参数的话,返回的结果是$N \times C \times H \times W$;
- $cpu\_data()$负责读取cpu中的数据,为常量,只可读,其实现就是调用SyncedMemory中的$cpu\_data()$;
- $set\_cpu\_data()$是为cpu中的数据空间进行赋值,其实现就是调用SyncedMemory中的$set\_cpu\_data()$;
- $mutable\_cpu\_data()$是获取指向该数据的指针,可以通过该指针来修改内部数据。
在Layer_factory和Layer中,其主要是利用了工厂模式的方式来进行组合,将每个特定层Layer进行注册,通过Layer_factory的多态性进行调用。在Layer中,$blob\_$表示模型的权重,即可学习的参数,例如卷积中的卷积核;而$SetUp()$函数是Layer中最重要的函数,其包含着检查输入输出是否合规、构建特定层和为top层分配空间等作用;最后的$Forward\_cpu()$则是前向计算的接口,将bottom的数据进行计算,放在top层空间中。
在Net中,其主要的作用是将所有构建的层按照特定顺序进行组合,并保存每层计算结果,得到最终模型输出结构。其中$layers$是一个vector,里面保存着指向在创建的layer,可以理解成指向每一层;$blobs$是一个vector,里面保存着指向blob的指针,代表着每层计算的结果;$bottom\_vecs$和$top\_vecs$里面保存在指向bottom层或者top层的指针。其余成员函数的作用分别是:
- $Init()$用于构建模型结构,可以理解成搭网络;
- $Forward()$表示模型的前向计算,其主要就是调用每个layer的$Forward\_cpu()$;
- $CopyTrainedLayersFrom()$的作用就是将训练好的caffemodel文件中的权重,拷贝到已经创建好的blob中。
二、SimpleCaffe的推理流程
接下来,结合具体的代码,讲述一下SimpleCaffe如何进行推理的,以图片分类为例。
main函数的入口为$tool/caffe.cpp$,其伪代码如下所示。这与人们常见的思维方式的流程一致,我写出了里面几个比较重要的函数,分别用于构建网络、加载权重和前向计算。接下来将会对这几部分进行注重讲解。
int main()
{
///设置prototxt和caffemodel的路径
//.. ///设置caffe的工作模型,cpu或者gpu
//.. ///根据prototxt文件来创建网络,并将caffemodel中的权重加载进网络中
Net<float> caffe_net(model, caffe::TEST, 0, nullptr);
caffe_net.CopyTrainedLayersFrom(weights);
//.. ///对图片进行处理,并将处理完的数据放入到网络的输入层对应的blob中
//.. ///进行模型的前向计算,并对结果进行后处理
caffe_net.Forward();
//..
}
2.1 构建网络
对于网络的构建,是通过构建Net的对象来完成的,其流程图如下所示。

具体的步骤如下描述:
- 读取并解析prototxt文件。
- 根据规则,加入或者排除某些层。因为在prototxt文件中里面包含着某些只有训练才用的层,例如loss层等。根据这些规则,在推理阶段可以将这些层给排除掉。
- 加入Split层。因为在我们搭建prototxt中,经常没有用split层,例如resnet中的的残差结构,没有专门写一份split层。这个split层的主要作用是将一个blob的数据复制成N份,方便接下来的层使用。所以,在这里需要判断哪些层需要进行Split,并在这些层之后创建Split层。
- 通过第1/2/3步,就已经能知道我们在这次推理中,需要哪些层了。接下来就是需要循环的创建每一层。
- 在第4步循环创建每一层中,首先需要调用工厂模式来创建一个指向该层的指针,但该指针只是指向该实例。
- 调用$AppendBottom()$和$AppendTop()$来为blob创建指针,但未开辟空间。这两个函数的配合方式是:在$AppendTop()$中创建指向blob的智能指针$blob\_pointer$ ,并将此指针加入到$top\_vecs$中,并记录下$blob\_name$,$layer\_id$和$blob\_id$;然后在$AppendBottom()$中,根据bottom的名字,找到上一层top的名字和上一层的$blob\_id$,由此得到在$AppendTop()$中的创建的$blob\_pointer$的指针,加入到$bottom\_vecs\_$。从而将同一层的bottom和top进行关联起来。
- 当把该层的bottom和top关联起来后,就需要调用在$include/caffe/layer.hpp$中的$SetUp()$函数,构建这一层,需要把bottom和top对应的指向blob的指针传入进去。
- 在$CheckBlobCounts()$函数中,会首先检查输入blob的数量和输出blob的数量是否满足在该层的定义的数量要求。例如relu层,需要满足一个输入和一个输入,如果你传入两个输入,则会报错。
- 调用$LayerSetUp()$函数,用于为为特定参数分配空间。例如在conv层中,需要记录下stride\pad\dilation等参数,同时为kernel分配空间大小。
- 在$Reshape()$中,需要为传入进行来top的指针(即top层对应的blob的指针)分配合适的空间。注意,这里只为top层分配空间,因为下一层的bottom会指向上一层的top。
通过上面的10步操作,就完成了网络的搭建,将每层的bottom和top关联起来,并分配了空间。
2.2 前向计算
当搭建完网络后,就需要进行前向计算。在前向计算中$net.cpp$会循环调用每一层的$Forward()$函数,在$layer.hpp$中的$Forward()$首先先进行$Reshape()$操作(即检查空间大小),然后执行虚函数$Forward\_cpu()$,这个虚函数$Forward\_cpu()$需要在每个层文件中自己定义如何进行实现,将bottom的数据计算得到top的数据。以普通的卷积conv层操作为例:
- 取出bottom和top的指针,循环每个batch size;
- 将特征图进行im2col转换,提高cache的命中率,加快计算速度;
- 将卷积核和特征图进行矩阵相乘的操作$caffe\_cpu\_gemm$,并将计算后的结果放入top指向空间。
通过$Forward()$函数,就完成了该层的前向计算操作。由于是循环每一层的$Forward()$函数,最终就得到模型的输出结果。
2.3 加载权重
加载模型权重是通过调用$net.cpp$文件中的$CopyTrainedLayersFrom()$函数。其主要逻辑是:
- 解析caffemodel文件,会得到一个字典(key为layer的名字,value为值);
- 根据caffemodel的key的名字来寻找已经建好的网络中对应的layer的名字;
- 如果找到相应的名字,则调用$blob.cpp$文件中的$FromProto()$函数,检查分配的空间大小是否一致,然后将caffemodel中该层的每个值复制到已经建好的blob中。
由于在实际空间中,数据是以一维的尺寸进行存放的,而且是连续的,所以能进行循环的复制。如此一来,网络中的每个blob就得到了训练好的权重,可以进行推理了。
三、其余辅助文件
在完成上述操作的基础上,还需要很多辅助函数的帮助,下面介绍一下:
- $im2col$文件,这个文件的作用是将特征图进行im2col操作,提高cache命中率;
- $io$文件,主要负责读取和解析prototxt与caffemodel;
- $math\_functions$文件和$mkl\_alternate$文件,负责定义caffe中常用的数学操作,例如矩阵相乘,元素相加等;
- $upgrade\_proto$文件,负责兼容旧的caffe版本的网络,用于将旧的层升级成新的层。
四、总结
上述只是以宏观的视角,大略介绍了一下SimpleCaffe的框架,具体更多的细节,需要仔细研读下项目。然而,在本次项目中,存在着很多不懂的地方,有待补充:
- cmake文件的编写;
- cblas或者openblas的用法;
- proto的编写,和如何进行解析的。
参考资料:
- Caffe源码导读
- caffe源码深入学习5:超级详细的caffe卷积层代码解析
- caffe源码深入学习6:超级详细的im2col绘图解析,分析caffe卷积操作的底层实现
- Caffe源码(一):math_functions 分析
基于CPU版本的Caffe推理框架的更多相关文章
- VMware12虚拟机中Ubuntu16.04安装CPU版本Caffe
首先,可以自行下载VMware12进行安装,基本上都是直接点击‘下一步’直到安装完成,这里重点讲一下Ubuntu16及Caffe的安装步骤 第一步: 下载Ubuntu16.04版本的文件,这里给出链接 ...
- Caffe cpu版本 Linux配置命令及搭建
Caffee 安装过程 1.安装依赖包 $ sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-de ...
- Windows上快速编译caffe CPU版本
windows上快速安装配置Caffe的 cpu_only环境. 一:安装环境: 1.windows10: 2.Visual Studio2013: 3.Caffe版本:http://github.c ...
- 基于Protobuf的分布式高性能RPC框架——Navi-Pbrpc
基于Protobuf的分布式高性能RPC框架——Navi-Pbrpc 二月 8, 2016 1 简介 Navi-pbrpc框架是一个高性能的远程调用RPC框架,使用netty4技术提供非阻塞.异步.全 ...
- 基于 Vue.js 之 iView UI 框架非工程化实践记要 使用 Newtonsoft.Json 操作 JSON 字符串 基于.net core实现项目自动编译、并生成nuget包 webpack + vue 在dev和production模式下的小小区别 这样入门asp.net core 之 静态文件 这样入门asp.net core,如何
基于 Vue.js 之 iView UI 框架非工程化实践记要 像我们平日里做惯了 Java 或者 .NET 这种后端程序员,对于前端的认识还常常停留在 jQuery 时代,包括其插件在需要时就引 ...
- 基于开源Dubbo分布式RPC服务框架的部署整合
一.前言 Dubbo 作为SOA服务化治理方案的核心框架,用于提高业务逻辑的复用.整合.集中管理,具有极高的可靠性(HA)和伸缩性,被应用于阿里巴巴各成员站点,同时在包括JD.当当在内的众多互联网项目 ...
- 基于SpringMVC下的Rest服务框架搭建【1、集成Swagger】
基于SpringMVC下的Rest服务框架搭建[1.集成Swagger] 1.需求背景 SpringMVC本身就可以开发出基于rest风格的服务,通过简单的配置,即可快速开发出一个可供客户端调用的re ...
- 从Theano到Lasagne:基于Python的深度学习的框架和库
从Theano到Lasagne:基于Python的深度学习的框架和库 摘要:最近,深度神经网络以“Deep Dreams”形式在网站中如雨后春笋般出现,或是像谷歌研究原创论文中描述的那样:Incept ...
- three.js粒子效果(分别基于CPU&GPU实现)
前段时间做了一个基于CPU和GPU对比的粒子效果丢在学习WebGL的群里,技术上没有多作讲解,有同学反馈看不太懂GPU版本,干脆开一篇文章,重点讲解基于GPU开发的版本. 一.概况 废话不多说,先丢上 ...
随机推荐
- 解决vue、js 下载图片浏览器默认预览而不是下载
在网页上,如果我们下载的地址对应的是一个jpg文件,txt文件等,点击链接时,浏览器默认的是打开这些文件而不是下载,那么如何才能实现默认下载呢? 后端解决 这就是Content-Disposition ...
- 多测师全方位面试题腾讯 _自动化面试题_高级讲师肖sir
作答注意:候选人可以两题都做,也可以两题任选一题做即可. 笔试题一:1.查询 https://www.newsmth.net/nForum/#!board/PieLove2.获取发贴时间是2020年8 ...
- C# 范型约束 new() 你必须要知道的事
C# 范型约束 new() 你必须要知道的事 注意:本文不会讲范型如何使用,关于范型的概念和范型约束的使用请移步谷歌. 本文要讲的是关于范型约束无参构造函数 new 的一些底层细节和注意事项.写这篇文 ...
- 使用Python对植物大战僵尸学习研究
根据上一篇 使用Python读写游戏1 中,使用Python win32库,对一款游戏进行了读内存 操作. 今天来写一下对内存进行写的操作 正文 要进行32位的读写,首先了解一下要用到的几个函数,通过 ...
- 游戏2048的核心算法c#版本的实现
接触游戏有一段时间了,也写了一些东西,效果还不错,今天没事,我就把2048 c# 版本的实现贴出来,代码已经测试过,可以正常.完美运行.当然了,在网上有很多有关2048的实现方法,但是没有提出到类里面 ...
- springboot2.2.2企业级项目整合redis与redis 工具类大全
1.springboot2.2.2整合redis教程很多,为此编写了比较完整的redis工具类,符合企业级开发使用的工具类 2.springboot与redis maven相关的依赖 <depe ...
- centos8下启用rc-local服务
一,centos8不建议写rc.local,默认启动时执行的命令放到何处? 以前我们会把linux开机执行的命令写入到/etc/rc.local 在centos8上系统不再建议我们写入到rc.loca ...
- poj2411 Mondriaan's Dream (轮廓线dp、状压dp)
Mondriaan's Dream Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 17203 Accepted: 991 ...
- 校招“避雷针”——GitHub 热点速览 Vol.43
作者:HelloGitHub-小鱼干 如果要选一个关键词来概述本周的 GitHub Trending,保护 便是不二之选.先是有 ShameCom 来为应届毕业生护航,让学弟学妹们不被黑名单上的公司上 ...
- JAVA NIO 基础学习
package com.hrd.netty.demo.jnio; import java.io.BufferedReader; import java.io.IOException; import j ...