打造云原生大型分布式监控系统(四): Kvass+Thanos 监控超大规模容器集群
概述
继上一篇 Thanos 部署与实践 发布半年多之后,随着技术的发展,本系列又迎来了一次更新。本文将介绍如何结合 Kvass 与 Thanos,来更好的实现大规模容器集群场景下的监控。
有 Thanos 不够吗 ?
有同学可能会问,Thanos 不就是为了解决 Prometheus 的分布式问题么,有了 Thanos 不就可以实现大规模的 Prometheus 监控了吗?为什么还需要个 Kvass?
Thanos 解决了 Prometheus 的分布式存储与查询的问题,但没有解决 Prometheus 分布式采集的问题,如果采集的任务和数据过多,还是会使 Prometheus 达到的瓶颈,不过对于这个问题,我们在系列的第一篇 大规模场景下 Prometheus 的优化手段 中就讲了一些优化方法:
- 从服务维度拆分采集任务到不同 Prometheus 实例。
- 使用 Prometheus 自带的 hashmod 对采集任务做分片。
但是,这些优化方法还是存在一些缺点:
- 配置繁琐,每个 Prometheus 实例的采集配置都需要单独配。
- 需要提前对数据规模做预估才好配置。
- 不同 Prometheus 实例采集任务不同,负载很可能不太均衡,控制不好的话仍然可能存在部分实例负载过高的可能。
- 如需对 Prometheus 进行扩缩容,需要手动调整,无法做到自动扩缩容。
Kvass 就是为了解决这些问题而生,也是本文的重点。
什么是 Kvass ?
Kvass 项目是腾讯云开源的轻量级 Prometheus 横向扩缩容方案,其巧妙的将服务发现与采集过程分离,并用 Sidecar 动态给 Prometheus 生成配置文件,从而达到无需手工配置就能实现不同 Prometheus 采集不同任务的效果,并且能够将采集任务进行负载均衡,以避免部分 Prometheus 实例负载过高,即使负载高了也可以自动扩容,再配合 Thanos 的全局视图,就可以轻松构建只使用一份配置文件的超大规模集群监控系统。下面是 Kvass+Thanos 的架构图:
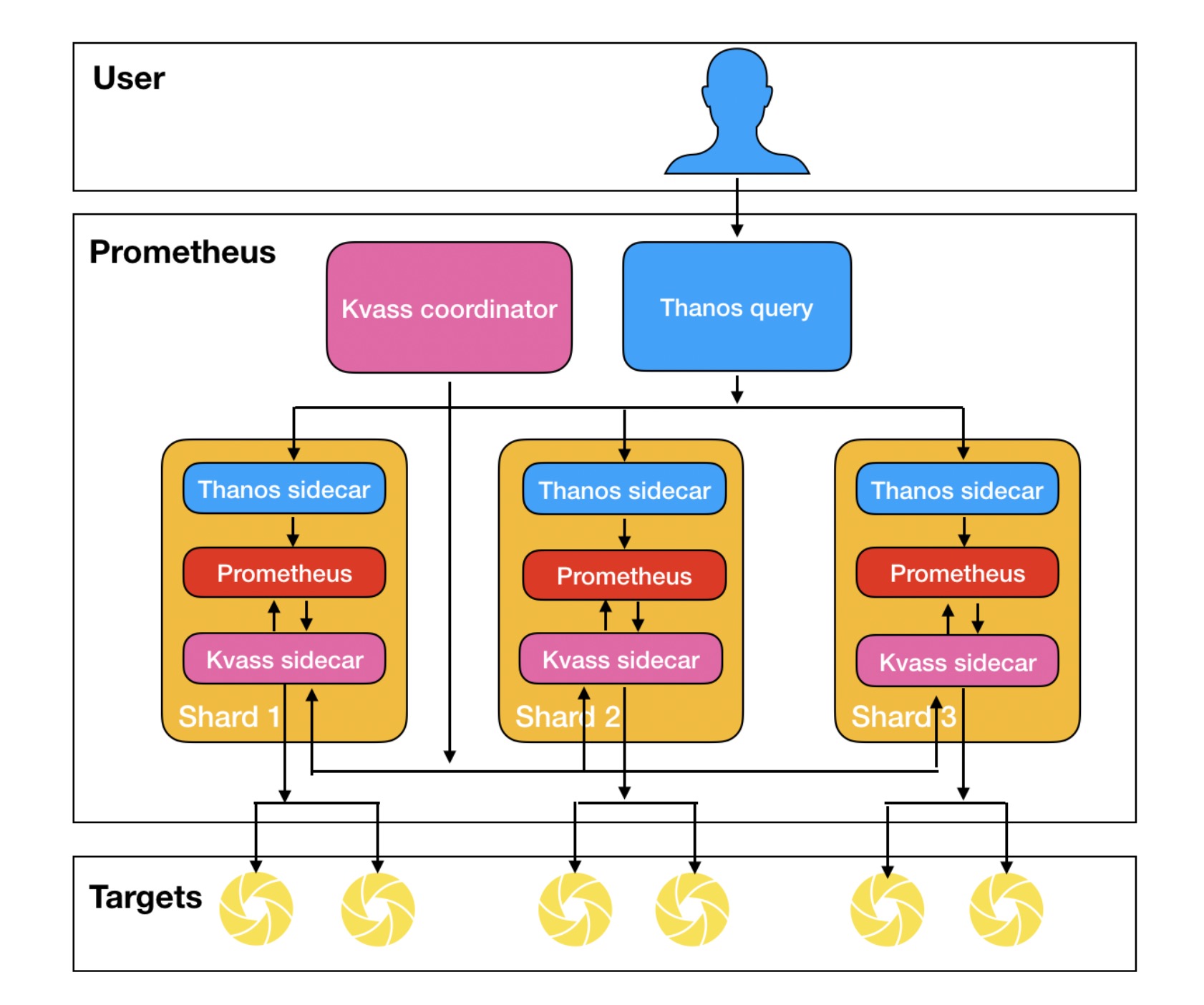
更多关于 Kvass 的详细介绍,请参考 如何用 Prometheus 监控十万 container 的 Kubernetes 集群 ,文章中详细介绍了原理和使用效果。
部署实践
部署准备
首先下载 Kvass 的 repo 并进入 examples 目录:
git clone https://github.com/tkestack/kvass.git
cd kvass/examples
在部署 Kvass 之前我们需要有服务暴露指标以便采集,我们提供了一个 metrics 数据生成器,可以指定生成一定数量的 series,在本例子中,我们将部署 6 个 metrics 生成器副本,每个会生成 10045 series,将其一键部署到集群:
kubectl create -f metrics.yaml
部署 Kvass
接着我们来部署 Kvass:
kubectl create -f kvass-rbac.yaml # Kvass 所需的 RBAC 配置
kubectl create -f config.yaml # Prometheus 配置文件
kubectl create -f coordinator.yaml # Kvass coordinator 部署配置
其中,config.yaml 的 Prometheus 配置文件,配了对刚才部署的 metrics 生成器的采集:
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
cluster: custom
scrape_configs:
- job_name: 'metrics-test'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
regex: metrics
action: keep
- source_labels: [__meta_kubernetes_pod_ip]
action: replace
regex: (.*)
replacement: ${1}:9091
target_label: __address__
- source_labels:
- __meta_kubernetes_pod_name
target_label: pod
coordinator.yaml 我们给 Coordinator 的启动参数中设置每个分片的最大 head series 数目不超过 30000:
--shard.max-series=30000
然后部署 Prometheus 实例(包含 Thanos Sidecar 与 Kvass Sidecar),一开始可以只需要单个副本:
kubectl create -f prometheus-rep-0.yaml
如果需要将数据存储到对象存储,请参考上一篇 Thanos 部署与实践 对 Thanos Sidecar 的配置进行修改。
部署 thanos-query
为了得到全局数据,我们需要部署一个 thanos-query:
kubectl create -f thanos-query.yaml
根据上述计算,监控目标总计 6 个 target, 60270 series,根据我们设置每个分片不能超过 30000 series,则预期需要 3 个分片。我们发现,Coordinator 成功将 StatefulSet 的副本数改成了 3。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
kvass-coordinator-c68f445f6-g9q5z 2/2 Running 0 64s
metrics-5876dccf65-5cncw 1/1 Running 0 75s
metrics-5876dccf65-6tw4b 1/1 Running 0 75s
metrics-5876dccf65-dzj2c 1/1 Running 0 75s
metrics-5876dccf65-gz9qd 1/1 Running 0 75s
metrics-5876dccf65-r25db 1/1 Running 0 75s
metrics-5876dccf65-tdqd7 1/1 Running 0 75s
prometheus-rep-0-0 3/3 Running 0 54s
prometheus-rep-0-1 3/3 Running 0 45s
prometheus-rep-0-2 3/3 Running 0 45s
thanos-query-69b9cb857-d2b45 1/1 Running 0 49s
我们再通过 thanos-query 来查看全局数据,发现数据是完整的(其中 metrics0 为指标生成器生成的指标名):
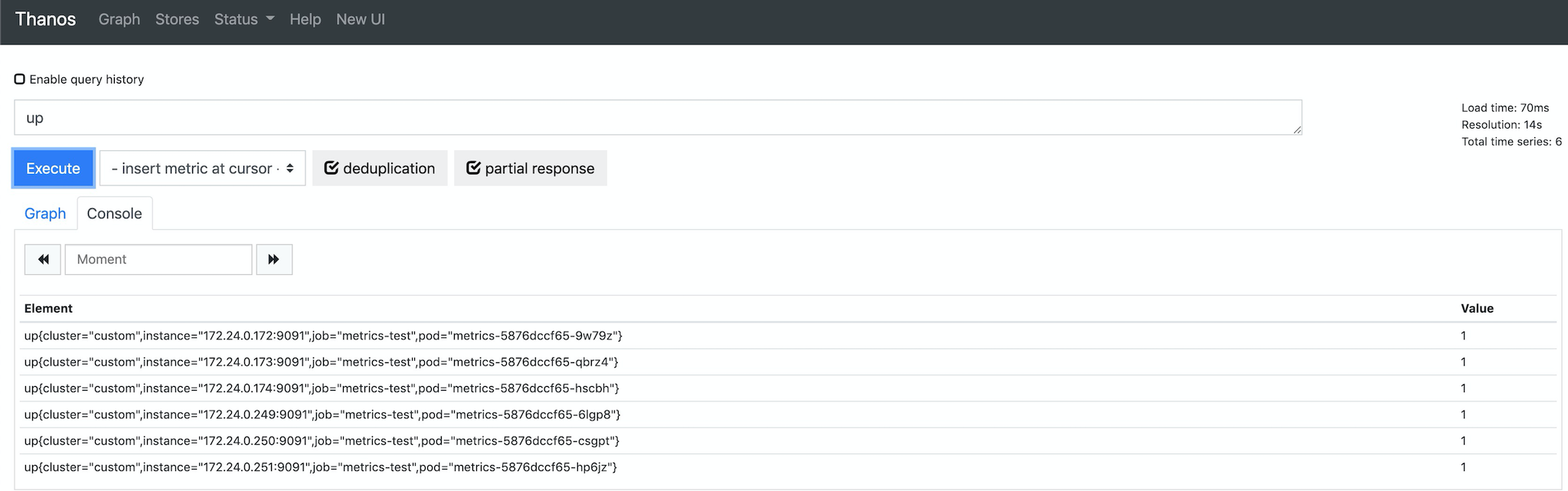
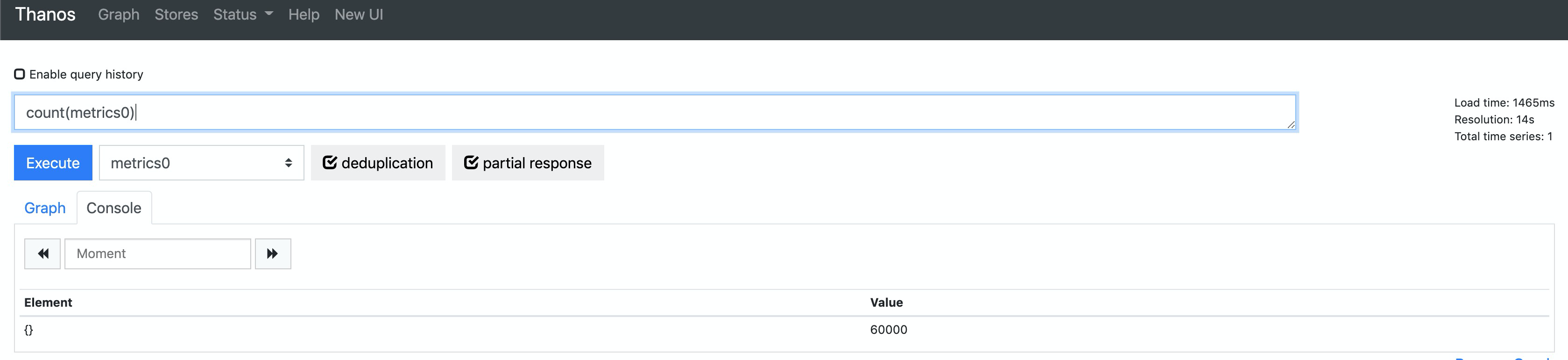
如果需要用 Grafana 面板查看监控数据,可以添加 thanos-query 地址作为 Prometheus 数据源: http://thanos-query.default.svc.cluster.local:9090。
小结
本文介绍了如何结合 Kvass 与 Thanos 来实现超大规模容器集群的监控,如果你使用了腾讯云容器服务,可以直接使用运维中心下的 云原生监控 服务,此服务就是基于 Kvass 构建的产品。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

打造云原生大型分布式监控系统(四): Kvass+Thanos 监控超大规模容器集群的更多相关文章
- 打造云原生大型分布式监控系统系列文章-腾讯工程师roc
附上本系列文章链接 打造云原生大型分布式监控系统(一): 大规模场景下 Prometheus 的优化手段 打造云原生大型分布式监控系统(二): Thanos 架构详解 打造云原生大型分布式监控系统(二 ...
- 重磅!容器集群监控利器 阿里云Prometheus 正式免费公测
Prometheus 作为容器生态下集群监控的首选方案,是一套开源的系统监控报警框架.它启发于 Google 的 borgmon 监控系统,并于 2015 年正式发布.2016 年,Prometheu ...
- vivo 容器集群监控系统架构与实践
vivo 互联网服务器团队-YuanPeng 一.概述 从容器技术的推广以及 Kubernetes成为容器调度管理领域的事实标准开始,云原生的理念和技术架构体系逐渐在生产环境中得到了越来越广泛的应用实 ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis学习(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- Windows7系统中nginx与IIS服务器搭建集群实现负载均衡
10分钟搭建服务器集群——Windows7系统中nginx与IIS服务器搭建集群实现负载均衡 分布式,集群,云计算机.大数据.负载均衡.高并发······当耳边响起这些词时,做为一个菜鸟程序猿无疑 ...
- Kubernetes容器集群管理环境 - Prometheus监控篇
一.Prometheus介绍之前已经详细介绍了Kubernetes集群部署篇,今天这里重点说下Kubernetes监控方案-Prometheus+Grafana.Prometheus(普罗米修斯)是一 ...
- kubernetes生态--交付prometheus监控及grafana炫酷dashboard到k8s集群
由于docker容器的特殊性,传统的zabbix无法对k8s集群内的docker状态进行监控,所以需要使用prometheus来进行监控: 什么是Prometheus? Prometheus是由Sou ...
随机推荐
- 内网安装python第三方包
内网快速安装python第三方包 内网安装包是一个很麻烦的问题,很多时候,内网的源会出现问题,导致无法安装. 这里给出一种快速在内网中安装第三方包,无需使用内网的源. 外网操作 1.根据开发环境下的所 ...
- Socket 结构体
proto socket 关联结构: { .type = SOCK_STREAM, .protocol = IPPROTO_TCP, .prot = &tcp_prot, .ops = &am ...
- redmine系统部署
1.下载railsinstaller.注意版本,我用的是老版的 railsinstaller-3.2.0.exe 下载地址 http://railsinstaller.org/en 国外的网站比较慢, ...
- rootfs如何取消登录超时
一种简便的办法,在etc/inittab文件中,增加一行::respawn:-/bin/login.之后当登录超时后,还会在进入到登录界面,就不会出现登录超时后无法在登录的问题了. #first:ru ...
- Shodan搜索引擎详解及Python命令行调用
shodan常用信息搜索命令 shodan配置命令 shodan init T1N3uP0Lyeq5w0wxxxxxxxxxxxxxxx //API设置 shodan信息收集 shodan myip ...
- tp5 生成随机数
控制器调用 public function GetRanStr(){ if (request()->isPost()) { //生成6位数随机数 return GetRandStr(6); } ...
- 凭借着这份面经,我拿下了字节,美团的offer!
最近经常有粉丝私信问我问了一些诸如秋招该怎么复习的问题,我就想顺便把回答整理发一发.我也是把之前面试的一些经历经验和身边的人面试的经验总结了一下放在下面. 前期准备规划: 如果秋招的话一般过年回来就可 ...
- FL Studio钢琴卷轴之工具菜单的Riff命令
鼠标左键点击FL Studio钢琴卷轴窗口中的"工具"命令,我们就可以打开快捷工具菜单.快捷菜单中包含了用于音符编辑的各种工具.按照该菜单的顺序,我们先来看一下什么是Riff器命令 ...
- 如何用pdfFactory新建打印机并设置属性
今天我们来讲一讲,在pdfFactory中如何去修改PDF文件打印页面的页边距.页面大小.页面清晰度等属性参数. pdfFactory是一款Windows平台上的虚拟打印机,在没有打印机可以安装的情况 ...
- Guitar Pro指弹入门——特殊拍号
在吉他演奏技术不断提高的同时,我们经常会遇到一些奇怪的曲谱.他们的拍号不是正常的4/4拍或者3/4拍,而是5/4或者5/8等等我们不太了解的拍号,致使我们在演奏和练习之中陷入纷乱的节奏. 那么本期文章 ...