Java网络通信 —— 序列化问题
Java序列化的目的主要有两个:
1.网络传输
2.对象持久化
当选行远程跨迸程服务调用时,需要把被传输的Java对象编码为字节数组或者ByteBuffer对象。而当远程服务读取到ByteBuffer对象或者字节数组时,需要将其解码为发送时的Java 对象。这被称为Java对象编解码技术。
Java序列化仅仅是Java编解码技术的一种,由于它的种种缺陷,衍生出了多种编解码技术和框架
Java序列化的缺点
Java序列化从JDK1.1版本就已经提供,它不需要添加额外的类库,只需实现java.io.Serializable并生成序列ID即可,因此,它从诞生之初就得到了广泛的应用。
但是在远程服务调用(RPC)时,很少直接使用Java序列化进行消息的编解码和传输,这又是什么原因呢?下面通过分析.Tava序列化的缺点来找出答案。
1 无法跨语言
对于跨进程的服务调用,服务提供者可能会使用C十+或者其他语言开发,当我们需要和异构语言进程交互时Java序列化就难以胜任。由于Java序列化技术是Java语言内部的私有协议,其他语言并不支持,对于用户来说它完全是黑盒。对于Java序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用。
2 序列化后的码流太大
通过一个实例看下Java序列化后的字节数组大小。
3序列化性能太低
无论是序列化后的码流大小,还是序列化的性能,JDK默认的序列化机制表现得都很差。因此,我们边常不会选择Java序列化作为远程跨节点调用的编解码框架。
序列化 – 内置和第三方的MessagePack实战
内置
Netty内置了对JBoss Marshalling和Protocol Buffers的支持
集成第三方MessagePack实战(LengthFieldBasedFrame详解)
LengthFieldBasedFrame详解
maxFrameLength:表示的是包的最大长度,
lengthFieldOffset:指的是长度域的偏移量,表示跳过指定个数字节之后的才是长度域;
lengthFieldLength:记录该帧数据长度的字段,也就是长度域本身的长度;
lengthAdjustment:长度的一个修正值,可正可负;
initialBytesToStrip:从数据帧中跳过的字节数,表示得到一个完整的数据包之后,忽略多少字节,开始读取实际我要的数据
failFast:如果为true,则表示读取到长度域,TA的值的超过maxFrameLength,就抛出一个 TooLongFrameException,而为false表示只有当真正读取完长度域的值表示的字节之后,才会抛出 TooLongFrameException,默认情况下设置为true,建议不要修改,否则可能会造成内存溢出。
数据包大小: 14B = 长度域2B + "HELLO, WORLD"(单词HELLO+一个逗号+一个空格+单词WORLD)
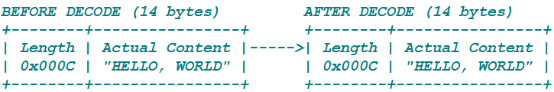
长度域的值为12B(0x000c)。希望解码后保持一样,根据上面的公式,参数应该为:
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment 无需调整
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
数据包大小: 14B = 长度域2B + "HELLO, WORLD"

长度域的值为12B(0x000c)。解码后,希望丢弃长度域2B字段,所以,只要initialBytesToStrip = 2即可。
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment 无需调整
4. initialBytesToStrip = 2 解码过程中,丢弃2个字节的数据
数据包大小: 14B = 长度域2B + "HELLO, WORLD"。长度域的值为14(0x000E)

长度域的值为14(0x000E),包含了长度域本身的长度。希望解码后保持一样,根据上面的公式,参数应该为:
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment = -2 因为长度域为14,而报文内容为12,为了防止读取报文超出报文本体,和将长度字段一起读取进来,需要告诉netty,实际读取的报文长度比长度域中的要少2(12-14=-2)
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
在长度域前添加2个字节的Header。长度域的值(0x00000C) = 12。总数据包长度: 17=Header(2B) + 长度域(3B) + "HELLO, WORLD"

长度域的值为12B(0x000c)。编码解码后,长度保持一致,所以initialBytesToStrip = 0。参数应该为:
1. lengthFieldOffset = 2
2. lengthFieldLength = 3
3. lengthAdjustment = 0无需调整
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
Header与长度域的位置换了。总数据包长度: 17=长度域(3B) + Header(2B) + "HELLO, WORLD"
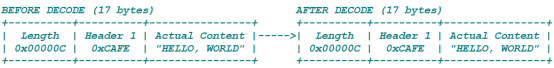
长度域的值为12B(0x000c)。编码解码后,长度保持一致,所以initialBytesToStrip = 0。参数应该为:
1. lengthFieldOffset = 0
2. lengthFieldLength = 3
3. lengthAdjustment = 2 因为长度域为12,而报文内容为12,但是我们需要把Header的值一起读取进来,需要告诉netty,实际读取的报文内容长度比长度域中的要多2(12+2=14)
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
带有两个header。HDR1 丢弃,长度域丢弃,只剩下第二个header和有效包体,这种协议中,一般HDR1可以表示magicNumber,表示应用只接受以该magicNumber开头的二进制数据,rpc里面用的比较多。总数据包长度: 16=HDR1(1B)+长度域(2B) +HDR2(1B) + "HELLO, WORLD"

长度域的值为12B(0x000c)
1. lengthFieldOffset = 1 (HDR1的长度)
2. lengthFieldLength = 2
3. lengthAdjustment =1 因为长度域为12,而报文内容为12,但是我们需要把HDR2的值一起读取进来,需要告诉netty,实际读取的报文内容长度比长度域中的要多1(12+1=13)
4. initialBytesToStrip = 3 丢弃了HDR1和长度字段
带有两个header,HDR1 丢弃,长度域丢弃,只剩下第二个header和有效包体。总数据包长度: 16=HDR1(1B)+长度域(2B) +HDR2(1B) + "HELLO, WORLD"

长度域的值为16B(0x0010),长度为2,HDR1的长度为1,HDR2的长度为1,包体的长度为12,1+1+2+12=16。
1. lengthFieldOffset = 1
2. lengthFieldLength = 2
3. lengthAdjustment = -3因为长度域为16,需要告诉netty,实际读取的报文内容长度比长度域中的要 少3(13-16= -3)
4. initialBytesToStrip = 3丢弃了HDR1和长度字段
MessagePack集成
Java网络通信 —— 序列化问题的更多相关文章
- java对象序列化、反序列化
平时我们在Java内存中的对象,是无法进行IO操作或者网络通信的,因为在进行IO操作或者网络通信的时候,人家根本不知道内存中的对象是个什么东西,因此必须将对象以某种方式表示出来,即存储对象中的状态.一 ...
- Java对象序列化剖析
对象序列化的目的 1)希望将Java对象持久化在文件中 2)将Java对象用于网络传输 实现方式 如果希望一个类的对象可以被序列化/反序列化,那该类必须实现java.io.Serializable接口 ...
- JAVA的序列化和持久化的区别与联系
持久化(Persistence) 即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘).持久化的主要应用是将内存中的对象存储在关系型的数据库中,当然也可以存储在磁盘文件中.XML数据文 ...
- 理解Java对象序列化
http://www.blogjava.net/jiangshachina/archive/2012/02/13/369898.html 1. 什么是Java对象序列化 Java平台允许我们在内存中创 ...
- java 对象序列化与反序列化
Java序列化与反序列化是什么? 为什么需要序列化与反序列化? 如何实现Java序列化与反序列化? 本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为 ...
- Java的序列化ID的作用
Java的序列化ID的作用 简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的.在进行反序列化时,JVM会把传来的字节流中的serialVersio ...
- Java程序员从笨鸟到菜鸟之(十三)java网络通信编程
本文来自:曹胜欢博客专栏.转载请注明出处:http://blog.csdn.net/csh624366188 首先声明一下,刚开始学习java网络通信编程就对他有一种畏惧感,因为自己对网络一窍不通,所 ...
- Java基础-序列化
Java序列化是将一个对象编码成一个字节流,反序列化将字节流编码转换成一个对象. 序列化是Java中实现持久化存储的一种方法: 为数据传输提供了线路级对象表示法. Java的序列化机制是通过在运行时判 ...
- java 对象序列化
java 对象序列化 package org.rui.io.serializable; import java.io.ByteArrayInputStream; import java.io.Byte ...
随机推荐
- Kubernetes Pod OOM 排查日记
一.发现问题 在一次系统上线后,我们发现某几个节点在长时间运行后会出现内存持续飙升的问题,导致的结果就是Kubernetes集群的这个节点会把所在的Pod进行驱逐OOM:如果调度到同样问题的节点上,也 ...
- 2020-03-26:eureka 和其他注册中心比如zk有什么不同?
从eureka工作原理可以看出,eureka client有缓存功能,即使eureka所有的serve都宕掉,仍然能给服务消费者发送服务信息,所以eureka保证了服务可用性,不能保证数据一致性,是一 ...
- C#LeetCode刷题之#342-4的幂(Power of Four)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4058 访问. 给定一个整数 (32 位有符号整数),请编写一个函 ...
- Kubernetes用Helm安装Ingress并踩一下使用的坑
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! Ingress是Kubernetes一个非常重要的Controller,它类似一个路由转发的组件,可以让外界访问Kubern ...
- 关于什么时候用,怎么用:ExecuteNonQuery(),还有其它返回值
ExecuteScalar方法返回的类型是object类型,这个方法返回sql语句执行后的第一行第一列的值,由于不知到sql语句到底是什么样的结构(有可能是int,有可能是char等等),所以Exec ...
- 什么是P,NP和NPC问题?
P问题,NP问题,NPC问题?这些都是计算机科学领域,关于算法方面的术语.在认识这些术语之前,建议同学们先认真学习一下算法的时间复杂度,因为算法的时间复杂度与P,NP和NPC问题高度相关. 什么是P问 ...
- GitHub标星120K+的JDK并发编程指南,连续霸榜GitHub终于开源了
前言 在编程行业中,有一个东西是和广大程序员形影不离的,在最一开始接触编程就是配置它的运行环境,然后java / javac,对,这个东西就是jdk 昨天项目刚上线,可以稍微休息一下了,但是猛的闲下来 ...
- 深度优先搜索(dfs)与出题感想
在3月23号的广度优先搜索(bfs)博客里,我有提到写一篇深搜博客,今天来把这个坑填上. 第一部分:深度优先搜索(dfs) 以上来自百度百科. 简单来说,深度优先搜索算法就是——穷举法,即枚举所有情况 ...
- 记一次mysql数据库被勒索(下)
背景: nextcloud的mysql数据库被黑,删库勒索.参考:记一次mysql数据库被勒索(上) mysql数据库恢复成功,nextcloud还是无法连接.参考:记一次mysql数据库被勒索(中) ...
- CSS动画实例:Loading加载动画效果(三)
3.小圆型Loading 这类Loading动画的基本思想是:在呈现容器中定义1个或多个子层,再对每个子层进行样式定义,使得其均显示为一个实心圆形,最后编写关键帧动画控制,使得各个实心圆或者大小发生改 ...