SparkSQL中产生笛卡尔积的几种典型场景以及处理策略
【前言:如果你经常使用Spark SQL进行数据的处理分析,那么对笛卡尔积的危害性一定不陌生,比如大量占用集群资源导致其他任务无法正常执行,甚至导致节点宕机。那么都有哪些情况会产生笛卡尔积,以及如何事前"预测"写的SQL会产生笛卡尔积从而避免呢?(以下不考虑业务需求确实需要笛卡尔积的场景)】
Spark SQL几种产生笛卡尔积的典型场景
首先来看一下在Spark SQL中产生笛卡尔积的几种典型SQL:
1. join语句中不指定on条件
select * from test_partition1 join test_partition2;
2. join语句中指定不等值连接
select * from test_partition1 t1 inner join test_partition2 t2 on t1.name <> t2.name;
3. join语句on中用or指定连接条件
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id or t1.name = t2.name;
4. join语句on中用||指定连接条件
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id || t1.name = t2.name;
除了上述举的几个典型例子,实际业务开发中产生笛卡尔积的原因多种多样。
同时需要注意,在一些SQL中即使满足了上述4种规则之一也不一定产生笛卡尔积。比如,对于join语句中指定不等值连接条件的下述SQL不会产生笛卡尔积:
--在Spark SQL内部优化过程中针对join策略的选择,最终会通过SortMergeJoin进行处理。
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id and t1.name<>t2.name;
此外,对于直接在SQL中使用cross join的方式,也不一定产生笛卡尔积。比如下述SQL:
-- Spark SQL内部优化过程中选择了SortMergeJoin方式进行处理
select * from test_partition1 t1 cross join test_partition2 t2 on t1.id = t2.id;
但是如果cross join没有指定on条件同样会产生笛卡尔积。那么如何判断一个SQL是否产生了笛卡尔积呢?
Spark SQL是否产生了笛卡尔积?
以join语句不指定on条件产生笛卡尔积的SQL为例:
-- test_partition1和test_partition2是Hive分区表
select * from test_partition1 join test_partition2;
通过Spark UI上SQL一栏查看上述SQL执行图,如下: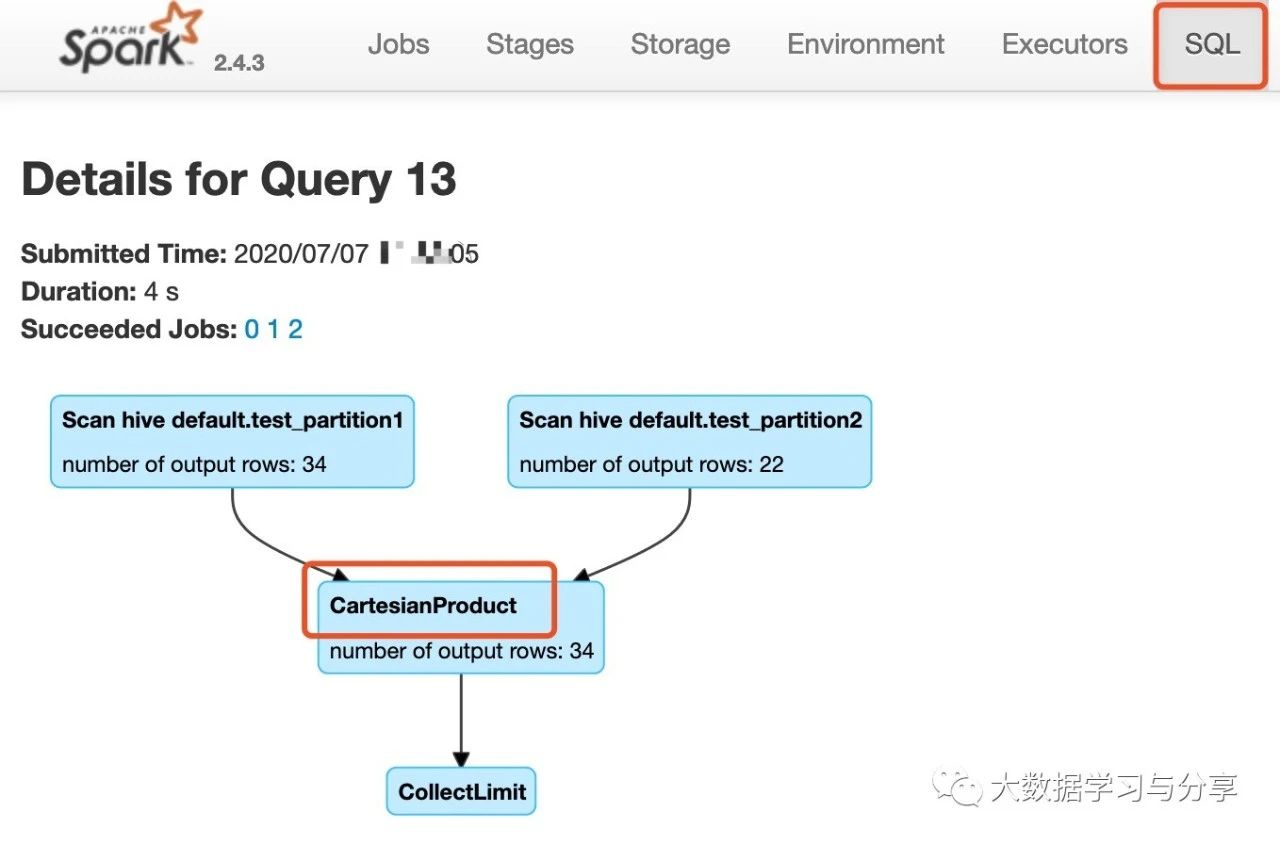
可以看出,因为该join语句中没有指定on连接查询条件,导致了CartesianProduct即笛卡尔积。
再来看一下该join语句的逻辑计划和物理计划:
== Parsed Logical Plan ==
'GlobalLimit 1000
+- 'LocalLimit 1000
+- 'Project [*]
+- 'UnresolvedRelation `t` == Analyzed Logical Plan ==
id: string, name: string, dt: string, id: string, name: string, dt: string
GlobalLimit 1000
+- LocalLimit 1000
+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]
+- SubqueryAlias `t`
+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]
+- Join Inner
:- SubqueryAlias `default`.`test_partition1`
: +- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- SubqueryAlias `default`.`test_partition2`
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89] == Optimized Logical Plan ==
GlobalLimit 1000
+- LocalLimit 1000
+- Join Inner
:- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89] == Physical Plan ==
CollectLimit 1000
+- CartesianProduct
:- Scan hive default.test_partition1 [id#84, name#85, dt#86], HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- Scan hive default.test_partition2 [id#87, name#88, dt#89], HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
通过逻辑计划到物理计划,以及最终的物理计划选择CartesianProduct,可以分析得出该SQL最终确实产生了笛卡尔积。
Spark SQL中产生笛卡尔积的处理策略
在之前的文章中《Spark SQL如何选择join策略》已经介绍过,Spark SQL中主要有ExtractEquiJoinKeys(Broadcast Hash Join、Shuffle Hash Join、Sort Merge Join,这3种是我们比较熟知的Spark SQL join)和Without joining keys(CartesianProduct、BroadcastNestedLoopJoin)join策略。
那么,如何判断SQL是否产生了笛卡尔积就迎刃而解。
1. 在利用Spark SQL执行SQL任务时,通过查看SQL的执行图来分析是否产生了笛卡尔积。如果产生笛卡尔积,则将任务杀死,进行任务优化避免笛卡尔积。【不推荐。用户需要到Spark UI上查看执行图,并且需要对Spark UI界面功能等要了解,需要一定的专业性。(注意:这里之所以这样说,是因为Spark SQL是计算引擎,面向的用户角色不同,用户不一定对Spark本身了解透彻,但熟悉SQL。对于做平台的小伙伴儿,想必深有感触)】
2. 分析Spark SQL的逻辑计划和物理计划,通过程序解析计划推断SQL最终是否选择了笛卡尔积执行策略。如果是,及时提示风险。具体可以参考Spark SQL join策略选择的源码:
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
// --- BroadcastHashJoin --------------------------------------------------------------------
// broadcast hints were specified
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// broadcast hints were not specified, so need to infer it from size and configuration.
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// --- ShuffledHashJoin ---------------------------------------------------------------------
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)
&& muchSmaller(right, left) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)
&& muchSmaller(left, right) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))
// --- SortMergeJoin ------------------------------------------------------------
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if RowOrdering.isOrderable(leftKeys) =>
joins.SortMergeJoinExec(
leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil
// --- Without joining keys ------------------------------------------------------------
// Pick BroadcastNestedLoopJoin if one side could be broadcast
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
// Pick CartesianProduct for InnerJoin
case logical.Join(left, right, _: InnerLike, condition) =>
joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nil
case logical.Join(left, right, joinType, condition) =>
val buildSide = broadcastSide(
left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)
// This join could be very slow or OOM
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
// --- Cases where this strategy does not apply ---------------------------------------------
case _ => Nil
}
此外,在业务开发中,要不断总结归纳产生笛卡尔积的情况,形成知识文档,以便在后续业务开发中避免类似的情况出现。
除了笛卡尔积效率比较低,BroadcastNestedLoopJoin效率也相对低效,尤其是当数据量大的时候还很容易造成driver端的OOM,这种情况也是需要极力避免的。
推荐文章:
Spark SQL中Not in Subquery为何低效以及如何规避
SparkSQL与Hive metastore Parquet转换
Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
关注微信公众号:大数据学习与分享,获取更对技术干货
SparkSQL中产生笛卡尔积的几种典型场景以及处理策略的更多相关文章
- MyBatis 中 @Param 注解的四种使用场景,最后一种经常被人忽略!
有一些小伙伴觉得 MyBatis 只有方法中存在多个参数的时候,才需要添加 @Param 注解,其实这个理解是不准确的.即使 MyBatis 方法只有一个参数,也可能会用到 @Param 注解. 但是 ...
- MyBatis 中 @Param 注解的四种使用场景
https://juejin.im/post/6844903894997270536 第一种:方法有多个参数,需要 @Param 注解 第二种:方法参数要取别名,需要 @Param 注解 第三种:XM ...
- SpringMVC 中 @ControllerAdvice 注解的三种使用场景!
@ControllerAdvice ,很多初学者可能都没有听说过这个注解,实际上,这是一个非常有用的注解,顾名思义,这是一个增强的 Controller.使用这个 Controller ,可以实现三个 ...
- sqlserver中几种典型的等待
为了准备今年的双11很久没有更新blog,在最近的几次sqlserver问题的排查中,总结了sqlserver几种典型的等待类型,类似于oracle中的等待事件,如果看到这样的等待类型时候能够迅速定位 ...
- jQuery中开发插件的两种方式
jQuery中开发插件的两种方式(附Demo) 做web开发的基本上都会用到jQuery,jQuery插件开发两种方式:一种是类扩展的方式开发插件,jQuery添加新的全局函数(jQuery的全局函数 ...
- 【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一.前述 SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数. 开窗函数一般分组取topn时常用. 二.UDF和UDAF函数 1.UDF函数 java代码: Spar ...
- MySQL中MyISAM和InnoDB两种主流存储引擎的特点
一.数据库引擎(Engines)的概念 MySQ5.6L的架构图: MySQL的存储引擎全称为(Pluggable Storage Engines)插件式存储引擎.MySQL的所有逻辑概念,包括SQL ...
- Python3求笛卡尔积的两种方法
[本文出自天外归云的博客园] 电影异次元杀阵三部曲中密室线索反复出现笛卡尔积的运用.百度百科: 笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为 ...
- DataSnap高级技术(7)—TDSServerClass中Lifecycle生命周期三种属性说明
From http://blog.csdn.net/sunstone/article/details/5282666 DataSnap高级技术(7)—TDSServerClass中Lifecycle生 ...
随机推荐
- Leetcode(3)-无重复字符的最长子串
给定一个字符串,找出不含有重复字符的最长子串的长度. 示例: 给定 "abcabcbb" ,没有重复字符的最长子串是 "abc" ,那么长度就是3. 给定 &q ...
- μC/OS-III---I笔记6---互斥信号量
互斥信号量 操作系统中利用信号量解决进程间的同步和互斥(互斥信号量)的问题,在多道程序环境下,操作系统就是遮掩实现进程之间的同步和互斥.但是在使用的过程中厉害的前辈还是发现了这一优秀机制的缺陷,它会导 ...
- how to auto open demo and create it in a new codesandbox
how to auto open demo and create it in a new codesandbox markdown & iframe https://ant.design/do ...
- 如何正确的使用 Dart SDK API
如何正确的使用 Dart SDK API dart-core dart:core library https://api.dart.dev/stable/2.9.1/dart-core/dart-co ...
- base 64 bug & encodeURIComponent
base64 bug & encodeURIComponent window.btoa("jëh²H¶�%28"); // "autoskiptoclMjiu&q ...
- Make one your own Online Video Recorder by using WebRTC & vanilla javascript
Make one your own Online Video Recorder by using WebRTC & vanilla javascript Online Video Record ...
- SMS OTP 表单最佳做法 (短信验证)
<form action="/verify-otp" method="POST"> <input type="text" ...
- JVM元空间(Metaspace)
本文转载自JVM学习--元空间(Metaspace) 从方法区(PermGen)到元空间(Metaspace) 方法区(PermGen) JDK1.8以前的HotSpot JVM有方法区,也叫永久代( ...
- ipv4ipv6 地址字符串表示最大长度
1 for IPV4 #define INET_ADDRSTRLEN 16 111.112.113.114 32位IPV4地址,使用10进制+句点表示时,所占用的char数组的长度为16,其中包括最后 ...
- 【python】递归听了N次也没印象,读完这篇你就懂了
听到递归总觉得挺高大上的,为什么呢?因为对其陌生,那么今天就来一文记住递归到底是个啥. 不过先别急,一起来看一个问题:求10的阶乘(10!). 求x的阶乘,其实就是从1开始依次乘到x.那么10的阶乘就 ...