Java实现:抛开jieba等工具,写HMM+维特比算法进行词性标注
一、前言:词性标注
词性标注(Part-Of-Speech tagging, POS tagging),是语料库语言学中将语料库中单词的词性按其含义和上下文内容进行标记的文本数据处理技术。词性标注可以由人工或特定算法完成,使用机器学习(machine learning)方法实现词性标注是自然语言处理(NLP)的研究内容。常见的词性标注算法包括隐马尔可夫模型(Hidden Markov Model, HMM)、条件随机场(Conditional random fields, CRFs)等。
在进入本篇算法的应用和实践之前,建议学习以下两篇内容,会有更好更容易的理解。
1、隐马尔可夫模型(HMM)来龙去脉(一)(https://www.cnblogs.com/chenzhenhong/p/13537680.html)
2、隐马尔可夫模型(HMM)来龙去脉(二)(https://www.cnblogs.com/chenzhenhong/p/13592058.html)
本篇实践的目标:
除了用jieba等分词词性标注工具,不如自行写一个算法实现同样的功能,这个过程可以对理论知识更好地理解和应用。下面将详细介绍使用HMM+维特比算法实现词性标注。在给定的单词发射矩阵和词性状态转移矩阵,完成特定句子的词性标注。
二、经典维特比算法(Viterbi)
词性标注使用隐马尔可夫模型原理,结合维特比算法(Viterbi),具体算法伪代码如下:

维特比算法正是解决HMM的三个基本问题中的第二个问题:在给定的观察序列中,找出最优的隐状态序列。应用在词性标注上,就是找到概率最大化的单词的词性。
下面是对维特比算法更加容易的解释:
- 观察序列长度 T,状态个数N
- for 状态s from 1 to N:do
- //计算每个状态的概率,相当于计算第一观察值的隐状态t=1
- v[s,1] = a(0,s)*b(O1|s) //初始状态概率 * 发射概率
- //回溯保存最大概率状态
- back[s,1]=0
- //计算每个观察(词语)取各个词性的概率,保存最大者
- for from 观察序列第二个 to T do:
- for 状态s from 1 to N:do
- //当前状态由前一个状态*转移*发射(该状态/词性下词t的概率),保存最大者
- v[s,t]=max v[i,t-1]*a[i,s]*b(Ot | s)
- //保存回溯点,该点为前一个状态转移到当前状态的最大概率点
- back[s,t]=arg{1,N} max v[i,t-1]*a(i,s)
- //最后
- v[T]=max v[T]
- back[T] = arg{1,N} max v[T]
- //回溯输出隐状态序列
三、算法实现
第一步,拆分算法计算问题,计算状态转移概率矩阵和符号发射概率矩阵方法:
根据给出的单词出现次数和词性状态矩阵,使用computeProp()方法计算得到发射概率矩阵和状态转移矩阵。
public void computeProp(float[][] A) {//计算概率矩阵
int i, j;
float[] t = new float[A.length];
//平滑数据,对数组每个元素值加一
for (i = 0; i < A.length; i++) {
for (j = 0; j < A[i].length; j++) {
A[i][j] += 1;
t[i] += A[i][j];
}
}
//计算当前元素在该行中的概率
for (i = 0; i < A.length; i++)
for (j = 0; j < A[i].length; j++)
A[i][j] /= t[i];
}
得到状态转移概率矩阵如下:
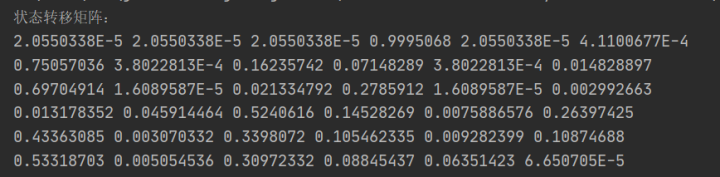
得到符号发射概率矩阵如下:
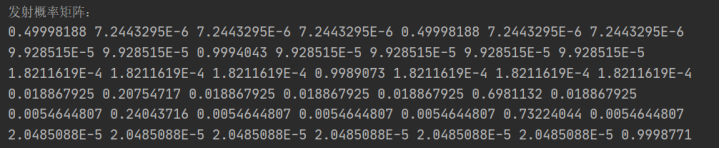
第二步,核心算法。本程序的关键部分是维特比算法的实现,计算得到最大概率的隐状态,然后保存最佳状态转移位置。对于每个观察值,先计算对应的可能的隐状态。
public int[] Viterbi(float[][] A, float[][] B, String[] O,double[] init) {
int back[][] = new int[A.length][O.length];
float V[][] = new float[A.length][O.length];
int i, s, k, t;
for (i = 0; i < A.length; i++) {
V[i][0] = (float) (init[i] * B[i][0]);
back[i][0] = i;
}
//计算每个观察值的取隐状态中的最大概率
for (t = 1; t < O.length; t++) {
int[][] path = new int[A.length][O.length];
//遍历每个隐状态,计算状态转移到当前状态的概率,得到最大概率状态
for (s = 0; s < A.length; s++) {
float maxSProb = -1;
int preS = 0;
for (i = 0; i < A.length; i++) {
float prob = V[i][t - 1] * A[i][s] * B[s][t];//B[s][t]为隐状态s到观察值t的发射概率
if (prob > maxSProb) {
maxSProb = prob;
preS = i;
}
}
//保存该状态的最大概率
V[s][t] = maxSProb;
//记录路径
System.arraycopy(back[preS],0,path[s],0,t);
path[s][t]=s;//最大概率状态转移记录
}
back=path;//更新最优路径
}
//回溯路径,找到最后状态
float maxP = -1;
int lastS = 0;
for (s = 0; s < A.length; s++) {
if (V[s][O.length - 1] > maxP) {
maxP = V[s][O.length - 1];
lastS = s;
}
}
return back[lastS];//返回最佳路径
}
以上是维特比算法,重要的代码语句解析可见注释。算法实现了将待标注句子使用维特比算法计算最大概率,得到最佳路径。
网上大部分使用了python实现该算法,python写起来简单,所以我尝试使用java实现,略有不同,期间遇到了一些小问题,后来不断debug解决问题。得到正确的java编写的维特比算法。
四、完整代码


/*
* hmm_viterbi.java
* Copyright (c) 2020-10-17
* author : Charzous
* All right reserved.
*/ public class hmm_viterbi { public int[] Viterbi(float[][] A, float[][] B, String[] O) {
int back[][] = new int[A.length][O.length];
float V[][] = new float[A.length][O.length];
double[] init = {0.2, 0.1, 0.1, 0.2, 0.3, 0.1};
int i, s, k, t; for (i = 0; i < A.length; i++) {
V[i][0] = (float) (init[i] * B[i][0]);
back[i][0] = i;
}
//计算每个观察值的取隐状态中的最大概率
for (t = 1; t < O.length; t++) {
int[][] path = new int[A.length][O.length];
//遍历每个隐状态,计算状态转移到当前状态的最大概率
for (s = 0; s < A.length; s++) {
float maxSProb = -1;
int preS = 0;
for (i = 0; i < A.length; i++) {
float prob = V[i][t - 1] * A[i][s] * B[s][t];//B[s][t]为隐状态s到观察值t的发射概率
if (prob > maxSProb) {
maxSProb = prob;
preS = i;
}
}
//保存该状态的最大概率
V[s][t] = maxSProb;
//记录路径
System.arraycopy(back[preS],0,path[s],0,t);
path[s][t]=s;
}
back=path;
} //回溯路径
float maxP = -1;
int lastS = 0;
for (s = 0; s < A.length; s++) {
if (V[s][O.length - 1] > maxP) {
maxP = V[s][O.length - 1];
lastS = s;
}
}
return back[lastS];
} public void computeProp(float[][] A) {
int i, j;
float[] t = new float[A.length];
//平滑数据,对数组每个元素值加一
for (i = 0; i < A.length; i++) {
for (j = 0; j < A[i].length; j++) {
A[i][j] += 1;
t[i] += A[i][j];
}
}
//计算当前元素在该行中的概率
for (i = 0; i < A.length; i++)
for (j = 0; j < A[i].length; j++)
A[i][j] /= t[i]; System.out.println();
// for (i = 0; i < A.length; i++) {
// for (j = 0; j < A[i].length; j++)
// System.out.print(A[i][j] + " ");
// System.out.println();
// } } public static void main(String[] args) {
//状态转移矩阵
float A[][] = {{0, 0, 0, 48636, 0, 19}, {1973, 0, 426, 187, 0, 38}, {43322, 0, 1325, 17314, 0, 185}, {1067, 3720, 42470, 11773, 614, 21392}, {6072, 42, 4758, 1476, 129, 1522}, {8016, 75, 4656, 1329, 954, 0}};
//发射矩阵
float B[][] = {{0, 0, 0, 0, 0, 0, 69016, 0}, {0, 10065, 0, 0, 0, 0, 0, 0}, {0, 0, 0, 5484, 0, 0, 0, 0}, {10, 0, 36, 0, 382, 108, 0, 0}, {43, 0, 133, 0, 0, 4, 0, 0}, {0, 0, 0, 0, 0, 0, 0, 48809}}; int i, j;
//语料库词语
String[] word = {"bear", "is", "move", "on", "president", "progress", "the", "."};
//待标注句子
String O[] = {"The", "bear", "is", "on", "the", "move", "."};
//语料库词性
String Q[] = {"/AT ", "/BEZ ", "/IN ", "/NN ", "/VB ", "/PERIOD "};
String seq="Bear move on the president .";
String Os[]=seq.split(" ");
for (String w:O)
System.out.println(w); float emission[][] = new float[B.length][O.length]; hmm_viterbi hmmViterbi = new hmm_viterbi();
hmmViterbi.computeProp(A); //计算观察序列的转移矩阵
//根据待标注句子的词计算出每个单词的出现次数矩阵
for (i = 0; i < O.length; i++) {
int r = 0;
for (int t = 0; t < word.length; t++) {
if (O[i].equalsIgnoreCase(word[t]))
r = t;
}
for (j = 0; j < B.length; j++)
emission[j][i] = B[j][r];
}
hmmViterbi.computeProp(emission);
int path[];
path=hmmViterbi.Viterbi(A, emission, O); for (i=0;i<O.length;i++){
System.out.print(O[i]+Q[path[i]]);
} // for (int p:path)
// System.out.print(p+" "); }
}
五、效果演示:
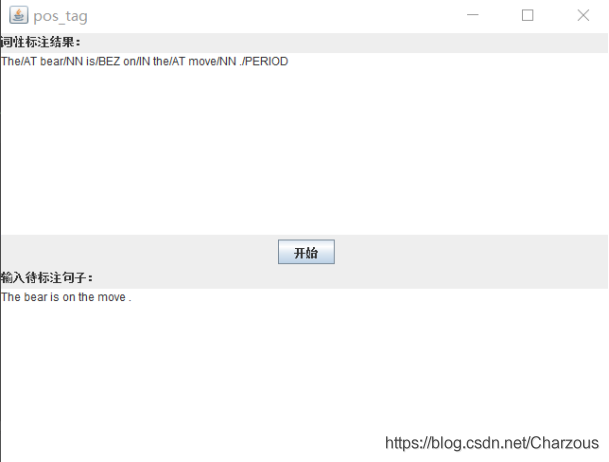
对于本实验的词性标注,简单设计了交互界面,方面测试不同句子的标注结果。在给定的测试句子”The bear is on the move .”上,实验结果如下:
The/AT bear/NN is/BEZ on/IN the/AT move/NN ./PERIOD
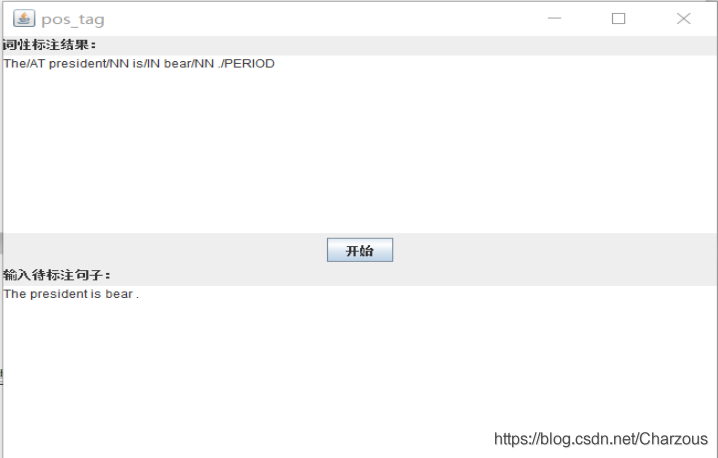
然后根据语料库自己造了一个句子,仅供测试用:”The president is bear .”实验结果:The/AT president/NN is/IN bear/NN ./PERIOD
感觉还可以,当然这只是一个例子,更确切需要更大的语料库。
六、总结
本篇详细介绍Java实现的HMM+维特比算法实现词性标注。在给定的单词发射矩阵和词性状态转移矩阵,完成特定句子的词性标注。这个任务可以在刚接触HMM和维特比算法进行词性标注作为实践,为之后实现特定语料库的词性标注铺垫。在完成本任务时,java编程实现算法时遇到了一些的问题,如:最佳路径的保存,回溯路径的返回。经过了一段时间的debug,实现了最基本的算法对句子进行词性标注。完成这个任务后,对HMM+Viterbi 算法的词性标注有了更深刻的理解,之后准备完成第三个任务:基于人民日报数据集的中文词性标注,可以对该算法进行更实际的应用,加深知识的理解。
我的博客园:https://www.cnblogs.com/chenzhenhong/p/13850687.html
我的CSDN博客:https://blog.csdn.net/Charzous/article/details/109138830
Java实现:抛开jieba等工具,写HMM+维特比算法进行词性标注的更多相关文章
- HMM——维特比算法(Viterbi algorithm)
1. 前言维特比算法针对HMM第三个问题,即解码或者预测问题,寻找最可能的隐藏状态序列: 对于一个特殊的隐马尔可夫模型(HMM)及一个相应的观察序列,找到生成此序列最可能的隐藏状态序列. 也就是说给定 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
- Java GUI图形界面开发工具
Applet 应用程序 一种可以在 Web 浏览器中执行的小程序,扩展了浏览器中的网页功能. 缺: 1.需要下载 Applet 及其相关文件 2.Applet 的功能是受限制的 优: 3.无需 ...
- java后台常用json解析工具问题小结
若排版紊乱可查看我的个人博客原文地址 java后台常用json解析工具问题小结 这里不细究造成这些问题的底层原因,只是单纯的描述我碰到的问题及对应的解决方法 jackson将java对象转json字符 ...
- 基于Java的简易表达式解析工具(二)
之前简单的介绍了这个基于Java表达式解析工具,现在把代码分享给大家,希望帮助到有需要的人们,这个分享代码中依赖了一些其他的类,这些类大家可以根据自己的情况进行导入,无非就是写字符串处理工具类,日期处 ...
- java中定义一个CloneUtil 工具类
其实所有的java对象都可以具备克隆能力,只是因为在基础类Object中被设定成了一个保留方法(protected),要想真正拥有克隆的能力, 就需要实现Cloneable接口,重写clone方法.通 ...
- java服务器访问其他服务器工具类编写
java服务器访问其他服务器工具类编写适合各种消息推送及微服务交互 package com.xiruo.medbid.components; import com.xiruo.medbid.util. ...
- JAVA程序员常用开发工具
1.JDK (Java Development Kit)Java开发工具集 SUN的Java不仅提了一个丰富的语言和运行环境,而且还提了一个免费的Java开发工具集(JDK).开发人员和最终用户可以利 ...
- java 文件读写的有用工具
java 文件读写的有用工具 package org.rui.io.util; import java.io.BufferedReader; import java.io.File; import j ...
随机推荐
- 必应API接口nodejs版
近期,在研究百度.必应.API等的url提交API时,发现有用Go语言做工具的大佬的分享 利用 API 自动向搜索引擎提交网址(Go语言版) - pyList. 其中提到bing API提交方法,并给 ...
- 使用App Metrics实现性能监控
App Metrics监控需要安装InfluxDB时序数据库和Grafana可视化分析工具 1.安装InfluxDB 下载地址:https://portal.influxdata.com/downlo ...
- Envoy 代理中的请求的生命周期
Envoy 代理中的请求的生命周期 翻译自Envoy官方文档. 目录 Envoy 代理中的请求的生命周期 术语 网络拓扑 配置 高层架构 请求流 总览 1.Listener TCP连接的接收 2.监听 ...
- 谈谈Netty内存管理
前言 正是Netty的易用性和高性能成就了Netty,让其能够如此流行. 而作为一款通信框架,首当其冲的便是对IO性能的高要求. 不少读者都知道Netty底层通过使用Direct Memory,减少了 ...
- Python新手入门基础
认识 Python 人生苦短,我用 Python -- Life is short, you need Python 目标 Python 的起源 为什么要用 Python? Python 的特点 Py ...
- 对之前IoT项目的完善
博文有点长,因为是两个大项目(四个小项目)放一起了,不过都很适合新手小白(有源程序的情况),也可以再接 OLED 屏,就是前几篇博客的操作 一.esp8266 读取 DHT11 数据并通过微信小程序发 ...
- MySQL-Atlas--读写分离架构
一.Atlas简介 Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目.它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础 ...
- 详解如何使用koa实现socket.io官网的例子
socket.io官网中使用express实现了一个最简单的IM即时聊天,今天我们使用koa来实现一下利用 socket.io 实现消息实时推送 框架准备 1.确保你本地已经安装好了nodejs和np ...
- [VBA原创源代码] excelhome 对花名册进行分类
最近在学习<菜鸟谈VBA最最基础入门<原创>>,其中第22节有一个VBA编程作业,实现对花名册进行分类. 自己花了点时间,自己丫丫学步,终于实现出来. 在原创聚集地cnblog ...
- 解决Use 'LimitInternalRecursion' to increase the limit if necessary的问题 CodeIgniter .htaccess
配置.htaccess如下: RewriteEngine on RewriteBase / RewriteCond $1 !^(index\.php|images|robots\.txt|css|js ...