python线性回归
一.理论基础
1.回归公式
对于单元的线性回归,我们有:f(x) = kx + b 的方程(k代表权重,b代表截距)。
对于多元线性回归,我们有:
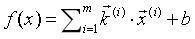
或者为了简化,干脆将b视为k0·x0,,其中k0为1,于是我们就有:
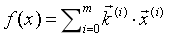
2.损失函数

3.误差衡量
MSE,RMSE,MAE越接近于0越好,R方越接近于1越好。
MSE平均平方误差(mean squared error)
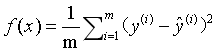
RMSE,是MSE的开根号
MAE平均绝对值误差(mean absolute error)
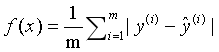
R方
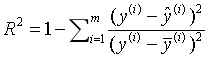
其中y_hat是预测值。
二.代码实现
本次,我们将用iris数据集实现单元线性回归的机器学习,使用boston数据集实现多元线性回归的机器学习。在python中,单元线性回归与多元线性回归的操作完全一样,这里只是为了演示而将其一分为二。
1.鸢尾花花瓣长度与宽度的线性回归
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 导入用于分割训练集和测试集的类
from sklearn.model_selection import train_test_split
# 导入线性回归类
from sklearn.linear_model import LinearRegression
import numpy as np
iris = load_iris()
'''
iris数据集的第三列是鸢尾花长度,第四列是鸢尾花宽度
x和y就是自变量和因变量
reshape(-1,1)就是将iris.data[:,3]由一维数组转置为二维数组,
以便于与iris.data[:,2]进行运算
'''
x,y = iris.data[:,2].reshape(-1,1),iris.data[:,3]
lr = LinearRegression()
'''
train_test_split可以进行训练集与测试集的拆分,
返回值分别为训练集的x,测试集的x,训练集的y,测试集的y,
分别赋值给x_train,x_test,y_train,y_test,
test_size:测试集占比
random_state:选定随机种子
'''
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25,random_state = 0)
# 利用训练集进行机器学习
lr.fit(x_train,y_train)
# 权重为lr.coef_
# 截距为lr.intercept_
# 运用训练出来的模型得出测试集的预测值
y_hat = lr.predict(x_test)
# 比较测试集的y值与预测出来的y值的前5条数据
print(y_train[:5])
print(y_hat[:5])
# 评价模型的准确性,用测试集来评价
# 导入分别用于求MSE,MAE和R方的包
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score
# 求解MSE
print('MSE:',mean_squared_error(y_test,y_hat))
# 求解RMSE,是MSE的开根号
print('RMSE:',np.sqrt(mean_squared_error(y_test,y_hat))
# 求解MAE
print('MAE:',mean_absolute_error(y_test,y_hat))
# 求解R方,有两种方法,注意lr.score的参数是x_test,y_test
print('R方:',r2_score(y_test,y_hat))
print('R方:',lr.score(x_test,y_test))
# 导入matplotlib模块,进行可视化
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = 15
plt.figure(figsize = (20,8))
# 训练集散点图
plt.scatter(x_train,y_train,color = 'green',marker = 'o',label = '训练集')
# 测试集散点图
plt.scatter(x_test,y_test,color = 'orange',marker = 'o',label = '测试集')
# 回归线
plt.plot(x,lr.predict(x),'r-')
plt.legend()
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')就这样画出了一张很丑的图,如果想画更精美的图或者其他方面的比较,各位读者不妨自己去试一试吧。
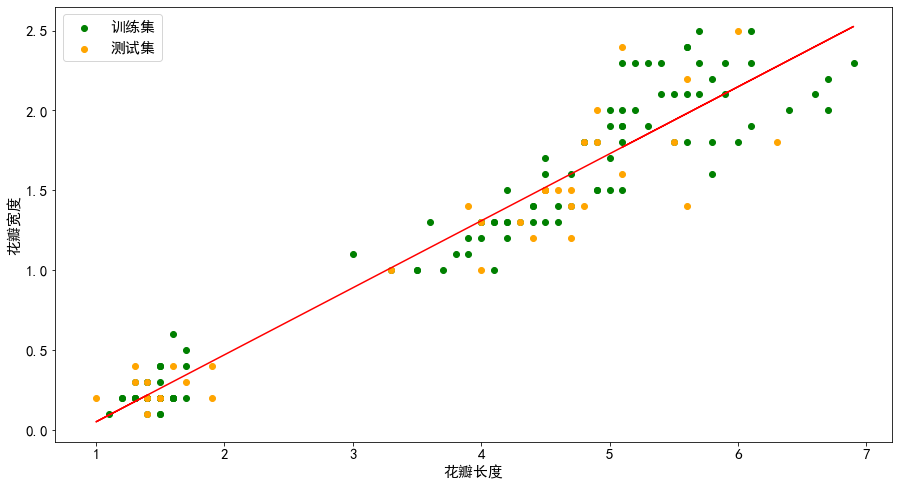
刚刚我们做了对鸢尾花花瓣长度和宽度的线性回归,探讨长度与宽度的关系,探究鸢尾花的花瓣宽度受长度变化的趋势是怎么样的。但是在现实生活当中的数据是十分复杂的,像这种单因素影响的事物是比较少的,我们需要引入多元线性回归来对多个因素的权重进行分配,从而与复杂事物相符合。
2.boston房价预测(多元线性回归)
呐,boston数据集的介绍在这里了,我就不详细介绍了
现在,我们要探讨boston当中每一个因素对房价的影响有多大,这就是一个多因素影响的典型例子。
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
boston = load_boston()
# lr继承LinearRegression类
lr = LinearRegression()
# 因为boston.data本身就是二维数组,所以无需转置,boston.target是房价
x,y = boston.data,boston.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.15,random_state = 0)
lr.fit(x_train,y_train)
# 显示权重,因为有很多因素,所以权重也有很多个
print(lr.coef_)
# 显示截距
print(lr.intercept_)
y_hat = lr.predict(x_test)
# 模型评判仍然是用那几个包,这里不再赘述。结果如下,可以发现每一个因素都有相应的权重。
[-1.24536078e-01 4.06088227e-02 5.56827689e-03 2.17301021e+00
-1.72015611e+01 4.02315239e+00 -4.62527553e-03 -1.39681074e+00
2.84078987e-01 -1.17305066e-02 -1.06970964e+00 1.02237522e-02
-4.54390752e-01]
36.09267761760974本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理
想要获取更多Python学习资料可以加
QQ:2955637827私聊
或加Q群630390733
大家一起来学习讨论吧!
python线性回归的更多相关文章
- Python 线性回归(Linear Regression) 基本理解
背景 学习 Linear Regression in Python – Real Python,对线性回归理论上的理解做个回顾,文章是前天读完,今天凭着记忆和理解写一遍,再回温更正. 线性回归(Lin ...
- python 线性回归示例
说明:此文的第一部分参考了这里 用python进行线性回归分析非常方便,有现成的库可以使用比如:numpy.linalog.lstsq例子.scipy.stats.linregress例子.panda ...
- Python 线性回归(Linear Regression) - 到底什么是 regression?
背景 学习 Linear Regression in Python – Real Python,对 regression 一词比较疑惑. 这个 linear Regression 中的 Regress ...
- Python - 线性回归(Linear Regression) 的 Python 实现
背景 学习 Linear Regression in Python – Real Python,前面几篇文章分别讲了"regression怎么理解","线性回归怎么理解& ...
- 机器学习之路: python线性回归 过拟合 L1与L2正则化
git:https://github.com/linyi0604/MachineLearning 正则化: 提高模型在未知数据上的泛化能力 避免参数过拟合正则化常用的方法: 在目标函数上增加对参数的惩 ...
- 机器学习之路: python 线性回归LinearRegression, 随机参数回归SGDRegressor 预测波士顿房价
python3学习使用api 线性回归,和 随机参数回归 git: https://github.com/linyi0604/MachineLearning from sklearn.datasets ...
- 机器学习之路:python线性回归分类器 LogisticRegression SGDClassifier 进行良恶性肿瘤分类预测
使用python3 学习了线性回归的api 分别使用逻辑斯蒂回归 和 随机参数估计回归 对良恶性肿瘤进行预测 我把数据集下载到了本地,可以来我的git下载源代码和数据集:https://gith ...
- Python线性回归算法【解析解,sklearn机器学习库】
一.概述 参考博客:https://www.cnblogs.com/yszd/p/8529704.html 二.代码实现[解析解] import numpy as np import matplotl ...
- ml的线性回归应用(python语言)
线性回归的模型是:y=theta0*x+theta1 其中theta0,theta1是我们希望得到的系数和截距. 下面是代码实例: 1. 用自定义数据来看看格式: # -*- coding:utf ...
随机推荐
- LNMP 一键安装脚本
这个脚本是使用shell编写,为了快速在生产环境上部署lnmp/lamp/lnmpa(Linux.Nginx/Tengine/OpenResty.MySQL/MariaDB/Percona.PHP), ...
- 一文搞懂所有Java集合面试题
Java集合 刚刚经历过秋招,看了大量的面经,顺便将常见的Java集合常考知识点总结了一下,并根据被问到的频率大致做了一个标注.一颗星表示知识点需要了解,被问到的频率不高,面试时起码能说个差不多.两颗 ...
- 现代富文本编辑器Quill的内容渲染机制
DevUI是一支兼具设计视角和工程视角的团队,服务于华为云DevCloud平台和华为内部数个中后台系统,服务于设计师和前端工程师.官方网站:devui.designNg组件库:ng-devui(欢迎S ...
- CentOS6.5上增加中文字体库,确保前端WEB可以正常显示
1 下载字体 可以在网上下载,也可以在 windows 目录下(C:\Windows\Fonts)找到对应字体,这里是从另一套系统上 copy simsun.ttf 文件. 2 查看当前系统中已安装的 ...
- 【刷题笔记】DP优化-状压
因为篇幅太长翻着麻烦,计划把DP拆成几个小专题,这里原文只留下状压,其他请至后续博文. 状态压缩优化 所谓状态压缩,就是将原本需要很多很多维来描述,甚至暴力根本描述不清的状态压缩成一维来描述. 时间复 ...
- 老猿学5G随笔:RAN、RAT以及anchor移动性锚点的概念
最近在学习UPF的功能时,有这样一句话"用户平面功能(UPF)包括以下功能. 用于RAT内/ RAT间移动性的锚点(适用时)",这句话不理解,后来看到了<关于移动锚点的理解! ...
- PyQt(Python+Qt)学习随笔:键盘焦点和逻辑焦点(Logic Focus与Keyboard Focus )
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 Qt中的焦点有键盘焦点和逻辑焦点(Logic Focus与Keyboard Focus )的区分,键 ...
- Oracle命令管理账户和权限
方式一.登陆数据库SQL PLUS: 步骤:Oracle - OraDb10g_home1 =>应用程序开发=>SQL PLUS 用户名:system 密码:tiger/admin 退出数 ...
- 攻防世界 web进阶区 ics-06
攻防世界 ics-06 涉及知识点: (1)php://filter协议 (2)php中preg_replace()函数的漏洞 解析: 进入题目的界面,一通乱点点出了唯一一个可以进入的界面. 观察ur ...
- Nginx 转发时的一个坑,运维居然让我背锅!!
最近遇到一个 Nginx 转发的坑,一个请求转发到 Tomcat 时发现有几个 http header 始终获取不到,导致线上出现 bug,运维说不是他的问题,这个锅我背了. 新增的几个 header ...