Hadoop生态系统之HDFS
一、介绍
HDFS : 分布式文件系统(distributed filesystem),主从结构。
以流式数据访问模式来存储超大文件,运行于商用硬件集群上。
超大文件: 几百M,几百G,甚至几百TB大小的文件。
流式数据访问: 一次写入,多次读取。每次读取都涉及到数据集的大部分数据甚至是全部,因
此读取整个数据集的延迟比读取一条数据的延迟更为重要)
商用硬件:不需要运行在高昂的高可靠的硬件上。
官方介绍: http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
二、NameNode 和 DataNodes
HDFS是一个主从master/slave架构。一个HDFS集群包含一个NameNode,这是一个master服务器,用来管理文件系统的命名空间以及调节客户端对文件的访问。除此,会有一堆DataNode,通常是集群里每个节点一个DataNode,管理在此节点上的数据存储。HDFS对外暴露一个文件系统命名空间,并允许用户数据以文件的形式存储。在内部,一个文件被分成一个或多个块并且这些块被存储在一组DataNode上。NameNode来执行文件系统命名空间的操作比如打开、关闭、重命名文件和目录。NameNode同时也负责决策将数据块映射到对应的DataNode。而DataNode负责服务文件系统客户端发出的读写请求。DataNode同时也负责接受NameNode的指令来进行数据块的创建、删除和复制。
NameNode和DataNode都是被设计为在普通PC机上运行的软件程序。这些机器最典型的就是运行在一个GNU/Linux操作系统上。HDFS是Java写的;任何支持Java的机器都可以运行NameNode或者DataNode。Java语言本身的可移植性意味着HDFS可以被广泛的部署在不同的机器上。一个典型的部署就是一台专用机器来运行NameNode。集群中的其他机器每台运行一个DataNode实例。该架构并不排除在同一台机器上运行多个DataNode实例,但在实际的部署中很少的情况下会这么做。
单一NameNode的设计极大的简化了集群的系统架构。NameNode是所有HDFS元数据的仲裁和存储库。系统被设计为用户数据从来不会流经NameNode。
整体架构
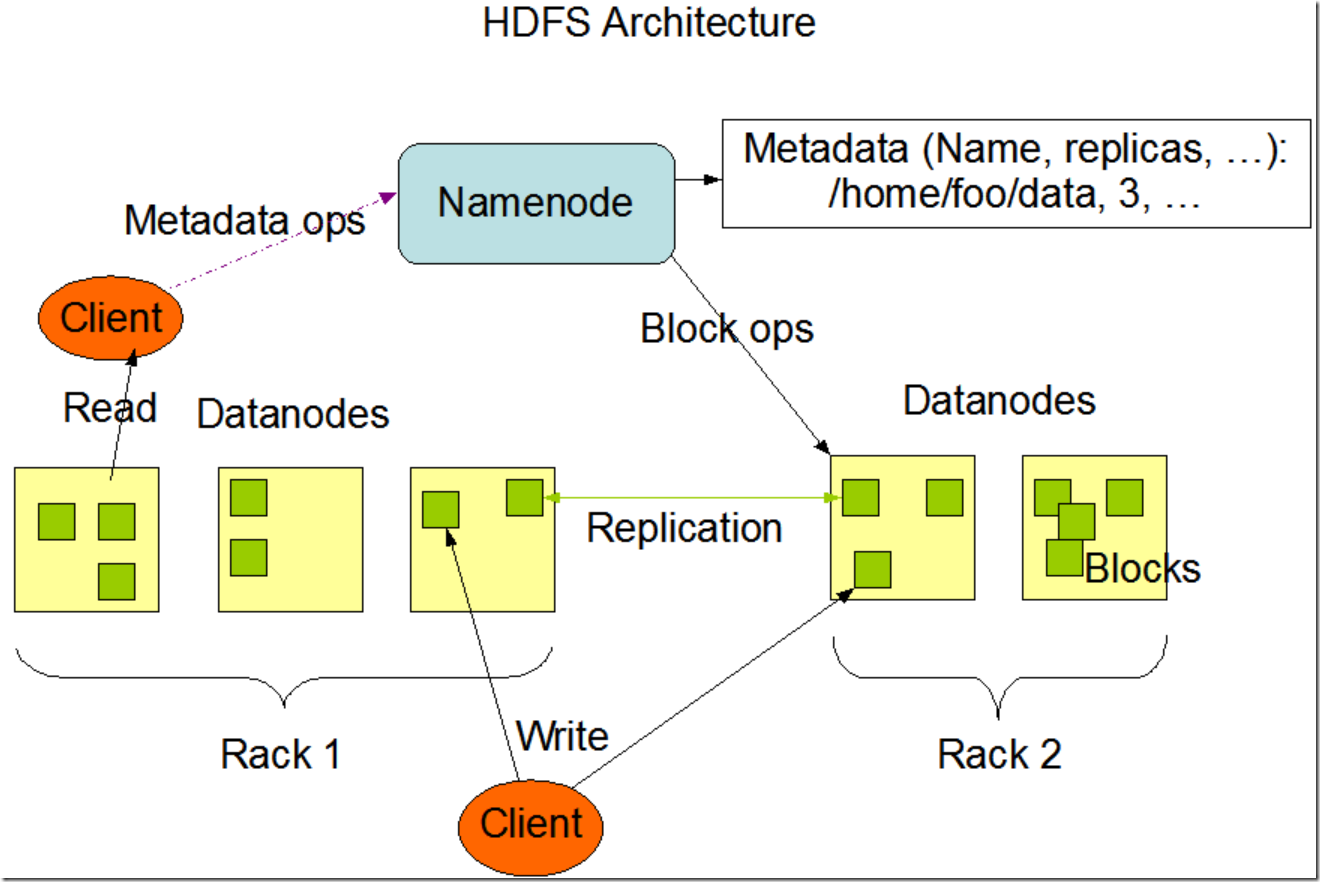
假设和目标
硬件失效
硬件失效是常态而不是特例。一个HDFS集群可能包含了成百上千的服务器,每个都会存储文件系统的部分数据。而大量的组件就会导致组件出错的概率非常高,而这也意味着HDFS的部分组件会经常不工作。因此,检查缺陷和快速自动地恢复就成了HDFS的核心架构目标。
流式数据访问
运行在HDFS上的应用程序需要流式访问数据集的能力。它们不是普通的运行在普通文件系统上的程序。HDFS被设计用来应对批量计算的场景,而不是用来和用户交互。重点是数据访问的高吞吐而不是低延迟。POSIX引入了大量的硬性需求来约束应用程序,而这些需求不是HDFS的目标需求。POSIX语义在一些关键领域被认为可以提高数据吞吐率。
大规模数据集
运行在HDFS上的程序拥有大规模的数据集。一个HDFS文件可能是GB级别或是TB级别的存储。因此HDFS被调优为存储大文件。它应该提供高聚合的数据带宽并且可以在单个集群内扩展到其他的上百上千的节点。程序应该支持在单实例中存在千万级别的文件。
简单的一致性模型
HDFS程序需要一个一次写入多次读出的文件访问模型。一旦一个文件被创建、写入数据然后关闭,这个文件应该不再需要被改动。此假设简化了数据一致性的问题,并且支持了数据的高吞吐。一个Map/Reduce程序或者一个网络爬虫程序就非常符合这种模型。未来有计划支持对于文件的追加写。
“迁移计算比迁移数据成本要低”
一个程序如果在运行计算任务时能更贴近其依赖的数据,那么计算会更高效。尤其是在数据集规模很大时该效应更加明显。因为这会最小化网络消耗而增加系统整体的吞吐能力。这一假设就是:把计算靠近数据要比把数据靠近计算成本更低。HDFS提供给应用程序接口来做到移动程序使其离数据更近。
跨异构硬件软件平台的可移植性
HDFS被设计为可以很容易的从一个平台移植到另一个平台。这有利于推广HDFS,使其作为广泛首选的大数据集应用的平台。
HDFS文件访问方式
replication(复制因子):定义了每份数据保存几个副本,可以在hdfs-core.xml配置文件中设置,默认值是 3。
1. 命令行访问:
上传文件到hdfs: hdfs dfs –put /localfile /hdfsdir
从hdfs拉文件到本地: hdfs dfs –get /hdfsdir /localfile
查看文件: hdfs dfs –ls /
创建目录: hdfs dfs –mkdir /newDir
2. http
通过http方式访问hdfs有两种方式:
a) 直接访问: 主要是访问namenode和datanode内嵌的web服务器作为WebHDFS的端节点运行(由于dfs.webhdfs.enabled被设置为true,WebHDFS默认是启用状态)。 文件元数据由namenode管理,文件读写操作首先被发往 namenode,由namenode发送一个http重定向至某个客户端,指示以流方式传输文件数据的目的或源datanode。
b) 依靠一个或者多个代理服务器http访问hdfs。(由于代理服务是无状态的,因此可以运行在标准的负载均衡器之后。)
3. NFS
使用hadoop的NFSv3网关将HDFS挂载为本地客户端的文件系统,然后你可以使用Unix实用程序(ls和cat)与该文件系统交互。
4. C语言
提供访问hdfs的c语言库。
Java接口
待补充
参考:
《hadoop权威指南》
http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
Hadoop生态系统之HDFS的更多相关文章
- Hadoop概念学习系列之Hadoop 生态系统(十二)
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Hadoop生态系统如何选择搭建
Apache Hadoop项目的目前版本(2.0版)含有以下模块: Hadoop通用模块:支持其他Hadoop模块的通用工具集. Hadoop分布式文件系统(HDFS):支持对应用数据高吞吐量访问的分 ...
- Hadoop组件之-HDFS(HA实现细节)
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- Hadoop 生态系统
1.概述 最近收到一些同学和朋友的邮件,说能不能整理一下 Hadoop 生态圈的相关内容,然后分享一些,我觉得这是一个不错的提议,于是,花了一些业余时间整理了 Hadoop 的生态系统,并将其进行了归 ...
- hadoop生态系统的详细介绍
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YAR ...
- hadoop 之Hadoop生态系统
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YAR ...
- 04_Apache Hadoop 生态系统
内容提纲: 1)对 Apache Hadoop 生态系统的认识(Hadoop 1.x 和 Hadoop 2.x) 2) Apache Hadoop 1.x 框架架构原理的初步认识 3) Apache ...
- Hadoop概念学习系列之Hadoop 生态系统
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Apache Kudu: Hadoop生态系统的新成员实现对快速数据的快速分析
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop's storage la ...
随机推荐
- 365. Water and Jug Problem量杯灌水问题
[抄题]: 简而言之:只能对 杯子中全部的水/容量-杯子中全部的水进行操作 You are given two jugs with capacities x and y litres. There i ...
- 数据库TCPIP协议开了,但还是远程连不上
可能是因为开着防火墙 把防火墙关掉,或者参考下面的链接,在防火墙添加例外 https://zhidao.baidu.com/question/394026326542219285.html
- [leetcode]75. Sort Colors三色排序
Given an array with n objects colored red, white or blue, sort them in-place so that objects of the ...
- Linux驱动之按键驱动编写(中断方式)
在Linux驱动之按键驱动编写(查询方式)已经写了一个查询方式的按键驱动,但是查询方式太占用CPU,接下来利用中断方式编写一个驱动程序,使得CPU占有率降低,在按键空闲时调用read系统调用的进程可以 ...
- 在桌面创建robotframework Ride的快捷方式启动RIDE
安装后robotframework-ride 后,每次启动时都要在Dos命令下启动 ,下面是创建快捷方式启动操作如下: 1.进入到python的安装目录的/Scripts目录下,找到ride.py文件 ...
- Java之IO流总结
IO流·Java流式输入/输出原理·Java流类的分类·输入/输出流类·常见的节点流和处理流·文件流·缓冲流·转换流·数据流·Print流·Object流 ①Java流式输入/输出原理 ...
- Mysql知识点个人整理
1.概念 数据库:保存有组织的数据的容器. 表: 某种特定类型数据的结构化清单 模式:关于数据库和表的布局和特性的信息?(有时指数据库) 主键: primary key 一个列或一组列,其值能唯一区分 ...
- python模块:datetime
# Stubs for datetime # NOTE: These are incomplete! import sys from typing import Optional, SupportsA ...
- MySQL-5.7安装
2.1 下载mysql 网址:https://www.mysql.com/ [root@localhost ~]# mkdir -p /root/soft/MySQL [root@localhost ...
- 展示博客---Alpha版本展示
Alpha版本展示 1. 团队成员的简介和个人博客地址,团队的源码仓库地址. 成员 简介 个人博客地址 祁泽文 被动态统计图搞扒下的我 http://www.cnblogs.com/jiaowoxia ...