听闻 kubernetes,快速了解一番

看到 各位 大厂都在用这个, 而本人最多是用yarn 做些ML的事情, 赶快了解一下, 先扫盲记录一下。
一.名称趣闻
kubernetes缩写为k8s, 阿哈 ,原来是:k8s,意思就是k后面跳过8个字母后到s,就变成了k8s。 kubernetes /kubə'netis/,重音在第三个音节,读音:库伯耐踢死
不免说这些硅谷的人呀,起名有一套!
它是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
二、为啥会出现这个东西?
“”“
在建设分布式训练平台的过程中,我们和机器学习的各个业务方,包括搜索推荐、图像算法、交易风控反作弊等,进行了深入沟通。
那么,对算法工程师是如何的? 从调查中发现,算法业务方往往专注于模型和调参,而工程领域是他们相对薄弱的一个环节。
建设一个强大的分布式平台,整合各个资源池,提供统一的机器学习框架,将能大大加快训练速度,提升效率,带来更多的可能性,此外还有助于提升资源利用率。
”“”
方便人的工具才是好东西!
痛点一:对算力的需求问题
公司目前的 Yarn 不支持 GPU 资源管理,虽然近期版本已支持该特性,但存在稳定性风险。
缺乏资源隔离和限制,同节点的任务容易出现资源冲突。
监控信息不完善。在发生资源抢占时,往往无法定位根本原因。
缺少弹性能力,目前资源池是静态的,如果能借助公有云的弹性能力,在业务高峰期提供更大的算力,将能更快的满足业务需求。
痛点二:人肉管理的成本很高
人肉化的管理主要包含了部署和训练任务管理两大方面,越多的人肉管理就是越多的成本呀。
部署:
不同的训练任务对 Python 的版本和依赖完全不同,比如有些模型使用 Python 2.7,有些使用 Python 3.3,有些使用 TensorFlow 1.8,有些使用 TensorFlow 1.11 等等,非常容易出现依赖包冲突的问题。虽然沙箱能在一定程度上解决这问题,但是也带来了额外的管理负担。还有, 不同 GPU 机型依赖的 Nvidia 驱动也不同,较新的卡,比如 V100 所依赖的版本更高。人肉部署还需要管理和维护多个不同的驱动版本。 等等
管理:
启动训练任务时, 需要手动查看 / 评估资源的剩余可用情况,手动指定 PS 和 Worker 的数量,管理配置并进行服务发现。这些都给业务方带来了很大的负担。而,Kubernetes 提供了生命周期管理的 API,用户基于 API 即可一键式完成训练任务的增删改查,避免人工 ssh 的各种繁琐操作,可以大幅提升用户体验和效率。
痛点三:监控的缺失
监控也是分布式训练重要的一环,它是性能调优的重要依据。
例如如下的描述:
“”“”
比如在 PS-Worker 的训练框架下,我们需要为每个 PS/Worker 配置合适的 GPU/CPU/Memory,并设置合适的 PS 和 Worker 数量。如果某个参数配置不当,往往容易造成性能瓶颈,影响整体资源的利用率。比如当 PS 的网络很大时,我们需要增加 PS 节点,并对大参数进行 partition;当 worker CPU 负载过高时,我们应该增加 Worker 的核数。
早期版本的 Hadoop 和 Yarn 并不支持 GPU 的资源可视化监控,而 Kubernetes 已拥有非常成熟监控方案 Prometheus,它能周期采集 CPU,内存,网络和 GPU 的监控数据,即每个 PS/Worker 的资源使用率都能得到详细的展示,为优化资源配置提供了依据。事实上,我们也是通过监控信息为不同的训练任务分配合适的资源配置,使得在训练速度和整体的吞吐率上达到一个较好的效果。
“”
痛点四:资源隔离较弱
早期的机器学习平台基于 Yarn 的 Angel 和 XLearning,由于 Yarn 缺乏对实例之间的资源隔离,我们在内存,网络,磁盘等均遇到不同程度的问题。
由于 Yarn 没有对任务的内存进行隔离,所以,业务方常常因对内存资源估计不准而导致 worker 的进程 OOM。由于所有的进程都共用宿主机的 IP,很容易造成端口冲突,此外磁盘 IO 和网络 IO 也很容易被打爆。

三. kubernetes作为机器学习基础平台
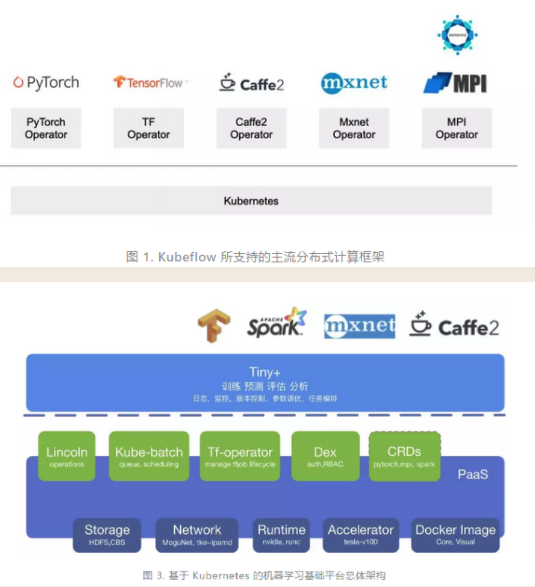
四、继续了解一下
Kubernetes 组件
- 1Master 组件
- 1.1kube-apiserver
- 1.2ETCD
- 1.3kube-controller-manager
- 1.4cloud-controller-manager
- 1.5kube-scheduler
- 1.6插件 addons
- 1.6.1DNS
- 1.6.2用户界面
- 1.6.3容器资源监测
- 1.6.4Cluster-level Logging
- 2节点(Node)组件
- 2.1kubelet
- 2.2kube-proxy
- 2.3docker
- 2.4RKT
- 2.5supervisord
- 2.6fluentd
Master 组件
- 节点(Node)控制器。
- 副本(Replication)控制器:负责维护系统中每个副本中的pod。
- 端点(Endpoints)控制器:填充Endpoints对象(即连接Services&Pods)。
- Service Account和Token控制器:为新的Namespace创建默认帐户访问API Token。
- 节点(Node)控制器
- 路由(Route)控制器
- Service控制器
- 卷(Volume)控制器
节点(Node)组件
- 安装Pod所需的volume。
- 下载Pod的Secrets。
- Pod中运行的 docker(或experimentally,rkt)容器。
- 定期执行容器健康检查。
- Reports the status of the pod back to the rest of the system, by creating amirror podif necessary.
- Reports the status of the node back to the rest of the system.
ha , 好复杂, 那么 如何将其玩转起来, 额, 这比较多了, 还是看这位老兄的吧, 写的挺多的,
http://baijiahao.baidu.com/s?id=1602795888204860650&wfr=spider&for=pc
参考:
https://mp.weixin.qq.com/s/cQNZnswSiKa8O0SkAiuRkQ
听闻 kubernetes,快速了解一番的更多相关文章
- Kubernetes快速入门
二.Kubernetes快速入门 (1)Kubernetes集群的部署方法及部署要点 (2)部署Kubernetes分布式集群 (3)kubectl使用基础 1.简介 kubectl就是API ser ...
- 【译】Hello Kubernetes快速交互实验手册
原文:https://kubernetes.io/docs/tutorials 翻译:Edison Zhou 一.基本介绍 此交互实验可以让你不用搭建K8S环境就可以轻松地尝试管理一个简单的容器化应用 ...
- (三)Kubernetes 快速入门
Kubernetes的核心对象 API Server提供了RESTful风格的编程接口,其管理的资源是Kubernetes API中的端点,用于存储某种API对象的集合,例如,内置Pod资源是包含了所 ...
- kubernetes快速应用入门
kubectl 就是 api server的客户端工具 创建一个nginx的pod [root@master ~]# kubectl run nginx-deploy --image=nginx:1. ...
- 第二章 Kubernetes快速入门
一.四组基本概念 Pod/Pod控制器: Name/Namespace: Label/Label选择器: Service/Ingress. 二.Pod/Pod控制器 2.1 Pod Pod是K8S里能 ...
- 企业运维 | MySQL关系型数据库在Docker与Kubernetes容器环境中快速搭建部署主从实践
[点击 关注「 WeiyiGeek」公众号 ] 设为「️ 星标」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 本章目录 目录 ...
- 坐标深圳 | Kubernetes!我要用这样的姿势拥抱你
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 从去年至今,容器.Kubernetes话题的热度就持续不减,有人说基于容器 +Kubernetes 的新型 PaaS 将会成为云计算的主流: ...
- bzoj 3992 [SDOI2015]序列统计——NTT(循环卷积&&快速幂)
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3992 有转移次数.模M余数.方案数三个值,一看就是系数的地方放一个值.指数的地方放一个值.做 ...
- Kubernetes之Pod使用
一.什么是Podkubernetes中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象.pod的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个 ...
随机推荐
- day16 函数的用法:内置函数,匿名函数
思维导图需要补全 : 一共有68个内置函数: #内置:python自带 # def func(): # a = 1 # b = 2 # print(locals()) # print(globals( ...
- 简单的使用Nginx框架搭建Web服务器~
系统环境Debian 8,内核版本 一.首先来安装nginx服务程序: 1.安装nginx服务需要的相关程序(记得在root权限下操作下面的指令) aptitude install libpcre3 ...
- UVa 11987 Almost Union-Find (虚拟点)【并查集】
<题目链接> 题目大意: 刚开始,1到n个集合中分别对应着1~n这些元素,然后对这些集合进行三种操作: 输入 1 a b 把a,b所在的集合合并 输入 2 a b 把b从b所在的旧集合移到 ...
- RFC2616-HTTP1.1-Header Field Definitions(头字段规定部分—单词注释版)
part of Hypertext Transfer Protocol -- HTTP/1.1RFC 2616 Fielding, et al. 14 Header Field Definitions ...
- Django单表操作
一.数据库相关设置 配置ORM的loggers日志: # 配置ORM的loggers日志 LOGGING = { 'version': 1, 'disable_existing_loggers': F ...
- Redis自学笔记:4.1进阶-事务
第4章:进阶 4.1事务 4.1.1概述 redis中的事务是一组命令的集合 事务同命令一样都是redis的最小执行单位,一个事务中的命令要么都执行, 要么都不执行 事务的原理是先将一个事务的命令发送 ...
- PHPstorm配置SVN的问题
开始尝试用PHPstorm做项目开发,在集成SVN的时候碰到了问题. 1. PHPstorm Cannot run program "svn" 2. Subversion comm ...
- python高级——垃圾回收机制
GC作为现代编程语言的自动内存管理机制,专注于两件事:1. 找到内存中无用的垃圾资源 2. 清除这些垃圾并把内存让出来给其他对象使用.GC彻底把程序员从资源管理的重担中解放出来,让他们有更多的时间放在 ...
- 主机ssh升级到6.7以上版本后,使用jsch jar包ssh连接不上报Algorithm negotiation fail问题的解决办法
ssh连接问题是由于主机ssh中缺少与jsch jar包匹配的加密算法导致,jsch jar包的默认加密算法貌似是diffie-hellman-group-exchange-sha1. 在目标主机ss ...
- Android EditText设置为Number类型后获取数字
s_video_seg1 = Integer.parseInt(video_seg1.getEditableText().toString().trim()); 此处要使用getEditableTex ...