自己动手实现java数据结构(三) 栈
1.栈的介绍
在许多算法设计中都需要一种"先进后出(First Input Last Output)"的数据结构,因而一种被称为"栈"的数据结构被抽象了出来。
栈的结构类似一个罐头:只有一个开口;先被放进去的东西沉在底下,后放进去的东西被放在顶部;想拿东西必须按照从上到下的顺序进行操作。
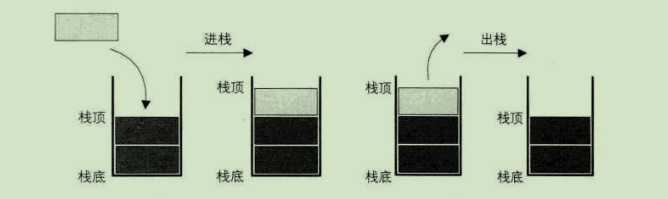 示意图来自《大话数据结构》
示意图来自《大话数据结构》
对于一个类似罐头的栈,用户能对其进行的操作很少:仅仅可以对栈顶开口处元素进行操作,因而栈的使用方式非常简单。
2.栈的ADT接口
/**
* 栈ADT 接口定义
* */
public interface Stack<E>{ /**
* 将一个元素 加入栈顶
* @param e 需要插入的元素
* @return 是否插入成功
* */
boolean push(E e); /**
* 返回栈顶元素,并且将其从栈中移除(弹出)
* @return 当前栈顶元素
* */
E pop(); /**
* 返回栈顶元素,不将其从栈中移除(窥视)
* @return 当前栈顶元素
* */
E peek(); /**
* @return 返回当前栈中元素的个数
*/
int size(); /**
* 判断当前栈是否为空
* @return 如果当前栈中元素个数为0,返回true;否则,返回false
*/
boolean isEmpty(); /**
* 清除栈中所有元素
* */
void clear(); /**
* 获得迭代器
* */
Iterator<E> iterator();
}
3.栈的实现
如果我们将开口朝上的栈旋转90度,会发现栈和先前我们介绍过的线性表非常相似。栈可以被视为一个只能在某一端进行操作的,被施加了特别限制的线性表。
3.1 栈的向量实现
栈作为一种特殊的线性表,使用向量作为栈的底层实现是很自然的(向量栈)。
jdk的栈结构(Stack)是通过继承向量类(Vector)来实现的,这一栈的实现方式被java集合框架(Collection Framework)的作者Josh Bloch在其所著书籍《Effective Java》中所批评,Josh Bloch认为这是一种糟糕的实现方式,因为继承自向量的栈对使用者暴露了过多的细节。
原文部分摘录:
复合优先于继承 继承打破了封装性。 java对象中违反这条规则的:stack不是vector,所以stack不应该扩展vector。如果在合适用复合的地方用了继承,会暴露实现细节。 继承机制会把超类中所有缺陷传递到子类中,而复合则允许设计新的API来隐藏这些缺陷。
考虑到这一点,我们的向量栈采用复合的方式实现。通过使用之前我们已经实现的向量数据结构作为基础,实现一个栈容器。
向量栈基本属性和接口:
/**
* 向量为基础实现的 栈结构
* */
public class VectorStack <E> implements Stack<E>{ /**
* 内部向量
* */
private ArrayList<E> innerArrayList; /**
* 默认构造方法
* */
public VectorStack() {
this.innerArrayList = new ArrayList<>();
} /**
* 构造方法,确定初始化时的内部向量大小
* */
public VectorStack(int initSize) {
this.innerArrayList = new ArrayList<>(initSize);
} @Override
public int size() {
return innerArrayList.size();
} @Override
public boolean isEmpty() {
return innerArrayList.isEmpty();
} @Override
public void clear() {
innerArrayList.clear();
} @Override
public Iterator<E> iterator() {
return innerArrayList.iterator();
} @Override
public String toString() {
return innerArrayList.toString();
}
}
由于我们的向量容器已经具备了诸如自动扩容等特性,因而向量栈的许多接口都可以通过简单的调用内部向量的接口来实现,不需要额外的操作。
栈的特有接口实现:
@Override
public boolean push(E e) {
//:::将新元素插入内部向量末尾(入栈)
innerArrayList.add(e); return true;
} @Override
public E pop() {
if(this.isEmpty()){
throw new CollectionEmptyException("Stack already empty");
} //:::内部向量末尾下标
int lastIndex = innerArrayList.size() - 1; //:::将向量末尾处元素删除并返回(出栈)
return innerArrayList.remove(lastIndex);
} @Override
public E peek() {
if(this.isEmpty()){
throw new CollectionEmptyException("Stack already empty");
} //:::内部向量末尾下标
int lastIndex = innerArrayList.size() - 1; //:::返回向量末尾处元素(窥视)
return innerArrayList.get(lastIndex);
}
栈的FIFO的特性,使得我们必须选择内部线性表的一端作为栈顶。
由于向量在头部的插入/删除需要批量移动内部元素,时间复杂度为O(n);而向量尾部的插入/删除由于避免了内部元素的移动,时间复杂度为O(1)。
而栈顶的元素是需要频繁插入(push)和删除(pop)的。出于效率的考虑,我们将向量的尾部作为栈顶,使得向量栈的出栈、入栈操作都达到了优秀的常数时间复杂度O(1)。
3.2 栈的链表实现
链表和向量同为线性表,因此栈的链表实现和向量实现几乎完全雷同。
由于链表在头尾出的增加/删除操作时间复杂度都是O(1),理论上链表栈的栈顶放在链表的头部或者尾部都可以。为了和向量栈实现保持一致,我们的链表栈也将尾部作为栈顶。
/**
* 链表为基础实现的 栈结构
* */
public class LinkedListStack<E> implements Stack<E>{ /**
* 内部链表
* */
private LinkedList<E> innerLinkedList; /**
* 默认构造方法
* */
public LinkedListStack() {
this.innerLinkedList = new LinkedList<>();
} @Override
public boolean push(E e) {
//:::将新元素插入内部链表末尾(入栈)
innerLinkedList.add(e); return true;
} @Override
public E pop() {
if(this.isEmpty()){
throw new CollectionEmptyException("Stack already empty");
} //:::内部链表末尾下标
int lastIndex = innerLinkedList.size() - 1; //:::将链表末尾处元素删除并返回(出栈)
return innerLinkedList.remove(lastIndex);
} @Override
public E peek() {
if(this.isEmpty()){
throw new CollectionEmptyException("Stack already empty");
} //:::内部链表末尾下标
int lastIndex = innerLinkedList.size() - 1; //:::返回链表末尾处元素(窥视)
return innerLinkedList.get(lastIndex);
} @Override
public int size() {
return innerLinkedList.size();
} @Override
public boolean isEmpty() {
return innerLinkedList.isEmpty();
} @Override
public void clear() {
innerLinkedList.clear();
} @Override
public Iterator<E> iterator() {
return innerLinkedList.iterator();
} @Override
public String toString() {
return innerLinkedList.toString();
}
}
4.栈的性能
栈作为线性表的限制性封装,其性能和其内部作为基础的线性表相同。
空间效率:
向量栈的空间效率和内部向量相似,效率很高。
链表栈的空间效率和内部链表相似,效率略低于向量栈。
时间效率:
栈的常用操作,pop、push、peek都是在线性表的尾部进行操作。因此无论是向量栈还是链表栈,栈的常用操作时间复杂度都为O(1),效率很高。
5.栈的总结
虽然从理论上来说,栈作为一个功能上被限制了的线性表,完全可以被线性表所替代。但相比线性表,栈结构屏蔽了线性表的下标等细节,只对外暴露出必要的接口。栈的引入简化了许多程序设计的复杂度,让使用者的思维能够聚焦于算法逻辑本身而不是其所依赖数据结构的细节。
通常,暴露出不必要的内部细节对于使用者是一种沉重的负担。简单为美,从栈的设计思想中可见一斑。
这篇博客的代码在我的 github上:https://github.com/1399852153/DataStructures,文章还存在许多不足之处,请多指教。
自己动手实现java数据结构(三) 栈的更多相关文章
- 自己动手实现java数据结构(一) 向量
1.向量介绍 计算机程序主要运行在内存中,而内存在逻辑上可以被看做是连续的地址.为了充分利用这一特性,在主流的编程语言中都存在一种底层的被称为数组(Array)的数据结构与之对应.在使用数组时需要事先 ...
- JAVA数据结构系列 栈
java数据结构系列之栈 手写栈 1.利用链表做出栈,因为栈的特殊,插入删除操作都是在栈顶进行,链表不用担心栈的长度,所以链表再合适不过了,非常好用,不过它在插入和删除元素的时候,速度比数组栈慢,因为 ...
- 自己动手实现java数据结构(四)双端队列
1.双端队列介绍 在介绍双端队列之前,我们需要先介绍队列的概念.和栈相对应,在许多算法设计中,需要一种"先进先出(First Input First Output)"的数据结构,因 ...
- 自己动手实现java数据结构(二) 链表
1.链表介绍 前面我们已经介绍了向量,向量是基于数组进行数据存储的线性表.今天,要介绍的是线性表的另一种实现方式---链表. 链表和向量都是线性表,从使用者的角度上依然被视为一个线性的列表结构.但是, ...
- 自己动手实现java数据结构(六)二叉搜索树
1.二叉搜索树介绍 前面我们已经介绍过了向量和链表.有序向量可以以二分查找的方式高效的查找特定元素,而缺点是插入删除的效率较低(需要整体移动内部元素):链表的优点在于插入,删除元素时效率较高,但由于不 ...
- 自己动手实现java数据结构(五)哈希表
1.哈希表介绍 前面我们已经介绍了许多类型的数据结构.在想要查询容器内特定元素时,有序向量使得我们能使用二分查找法进行精确的查询((O(logN)对数复杂度,很高效). 可人类总是不知满足,依然在寻求 ...
- Java数据结构之栈(Stack)
1.栈(Stack)的介绍 栈是一个先入后出(FILO:First In Last Out)的有序列表. 栈(Stack)是限制线性表中元素的插入和删除只能在同一端进行的一种特殊线性表. 允许插入和删 ...
- java数据结构-07栈
一.什么是栈 栈是一种线性结构,栈的特点就是先进后出(FILO):就像弹夹装子弹一样,最先压进去的在最底下,最后才被射出. 二.相关接口设计 三.栈的实现 栈可以用之前的数组.链表等设计,这里我使 ...
- 自己动手实现java数据结构(九) 跳表
1. 跳表介绍 在之前关于数据结构的博客中已经介绍过两种最基础的数据结构:基于连续内存空间的向量(线性表)和基于链式节点结构的链表. 有序的向量可以通过二分查找以logn对数复杂度完成随机查找,但由于 ...
随机推荐
- Java 7 使用TWR(Try-with-resources)完成文件copy
try-with-resources语句是声明了一个或多个资源的try语句块.在java中资源作为一个对象,在程序完成后必须关闭.try-with-resources语句确保每个资源在语句结束时关闭. ...
- SSL、TLS协议格式、HTTPS通信过程、RDP SSL通信过程(缺heartbeat)
SSL.TLS协议格式.HTTPS通信过程.RDP SSL通信过程 相关学习资料 http://www.360doc.com/content/10/0602/08/1466362_30787868 ...
- git 忽略文件不起作用
本人需要提交项目文件,发现总有一些东西不需要提交,然后搜索有”.gitignore”文件可以忽略一些提交,但是发现添加上没有起作用. 要贴的是: /build/ target/ .idea/ *.im ...
- 用nodejs搭建类似于C++的服务器后台.类似网易pomelo
实际的情况,用nodejs跑业务,非常的快,只要用好其无阻塞和回调这两点,处理速度真的是杠杠的. 从年初开始,我用nodejs搭建了类似C++的服务器后台,也想和做同样的事情的朋友分享,本服务平台因为 ...
- POJ 3107.Godfather 树形dp
Godfather Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 7536 Accepted: 2659 Descrip ...
- 2019.02.21 bzoj2300: [HAOI2011]防线修建(set+凸包)
传送门 题意:动态维护凸包周长. 思路: 见这篇求面积的吧反正都是一个套路. 代码: #include<bits/stdc++.h> #define int long long #defi ...
- 2019.02.11 bzoj4818: [Sdoi2017]序列计数(矩阵快速幂优化dp)
传送门 题意简述:问有多少长度为n的序列,序列中的数都是不超过m的正整数,而且这n个数的和是p的倍数,且其中至少有一个数是质数,答案对201704082017040820170408取模(n≤1e9, ...
- sql server常用字符串函数
--返回字符表达式中最左侧字符的ASCII代码值 --将整数ASCII代码转换为字符 )--a )--A ')--A SELECT CHAR('A')--在将 varchar 值 'A' 转换成数据类 ...
- MySQL insert语句锁分析
最近对insert的锁操作比较费解,所以自己动手,一看究竟.主要是通过一下三个sql来看一下执行中的sql的到底使用了什么锁. select * from information_schema.INN ...
- Transport Layer Protocols
1 End-to-end Protocols(端到端协议) 传输层协议往往是主机对主机(host-to-host)或者说是端到端(end-to-end).通常希望传输层协议可以提供如下service: ...