即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?
即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.报错:org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.
1>.由于我默认就开启了自动创建topic,因此我们直接启动生产者:kafka-console-producer.sh --broker-list 10.1.3.116:9092 --topic yinzhengjie-kafka (在一台安装jdk8版本的机器上操作)
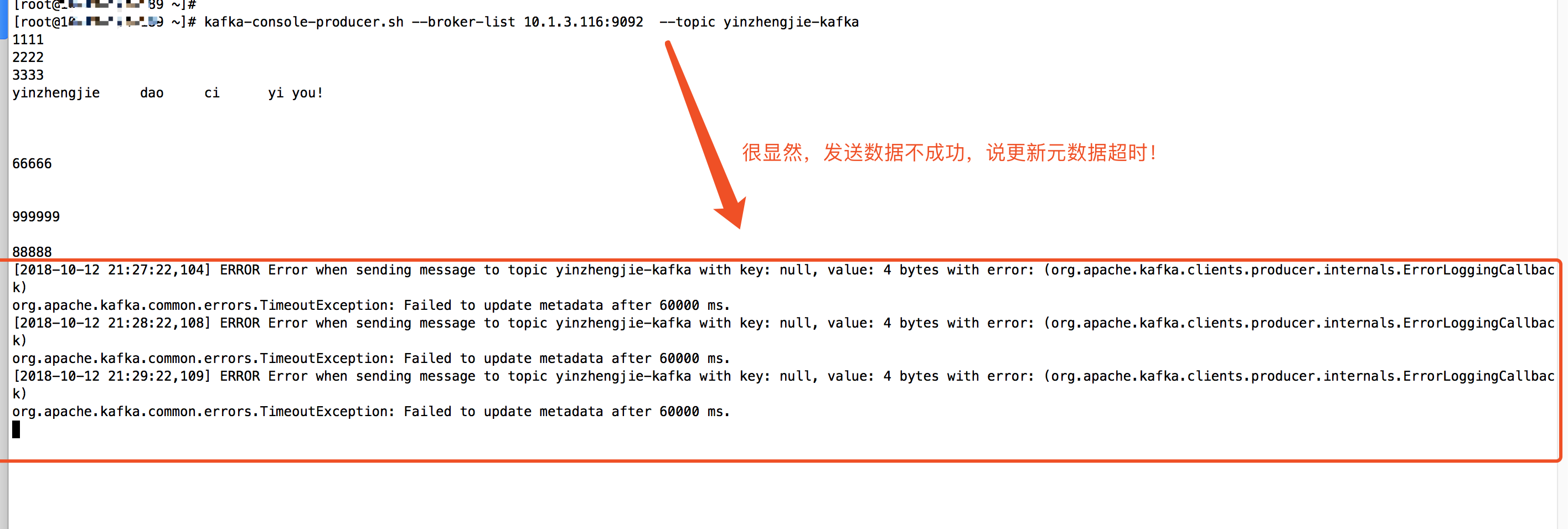
2>.紧接着我们启动消费者,观察是否能收到数据:kafka-console-consumer.sh --zookeeper 10.1.1.102:2181 --from-beginning --topic yinzhengjie-kafka(在一台jdk1.7上操作的)

解决办法:
查看Kafka集群是否正常启动,如果没有启动需要将Kafka集群启动起来!登陆CM观看自己的kafka集群发现该集群还未启动呢,导致的Kafka集群不可用

二.[2018-10-12 21:40:12,864] WARN Fetching topic metadata with correlation id 0 for topics [Set(yinzhengjie-kafka)] from broker [BrokerEndPoint(267,kafka119.aggrx,9092)] failed (kafka.client.ClientUtils$)
1>.由于我默认就开启了自动创建topic,因此我们直接启动生产者:kafka-console-producer.sh --broker-list 10.1.3.116:9092 --topic yinzhengjie-kafka (在一台安装jdk8版本的机器上操作)
2>.紧接着我们启动消费者,观察是否能收到数据:kafka-console-consumer.sh --zookeeper 10.1.1.102:2181 --from-beginning --topic yinzhengjie-kafka(在一台jdk1.7上操作的)
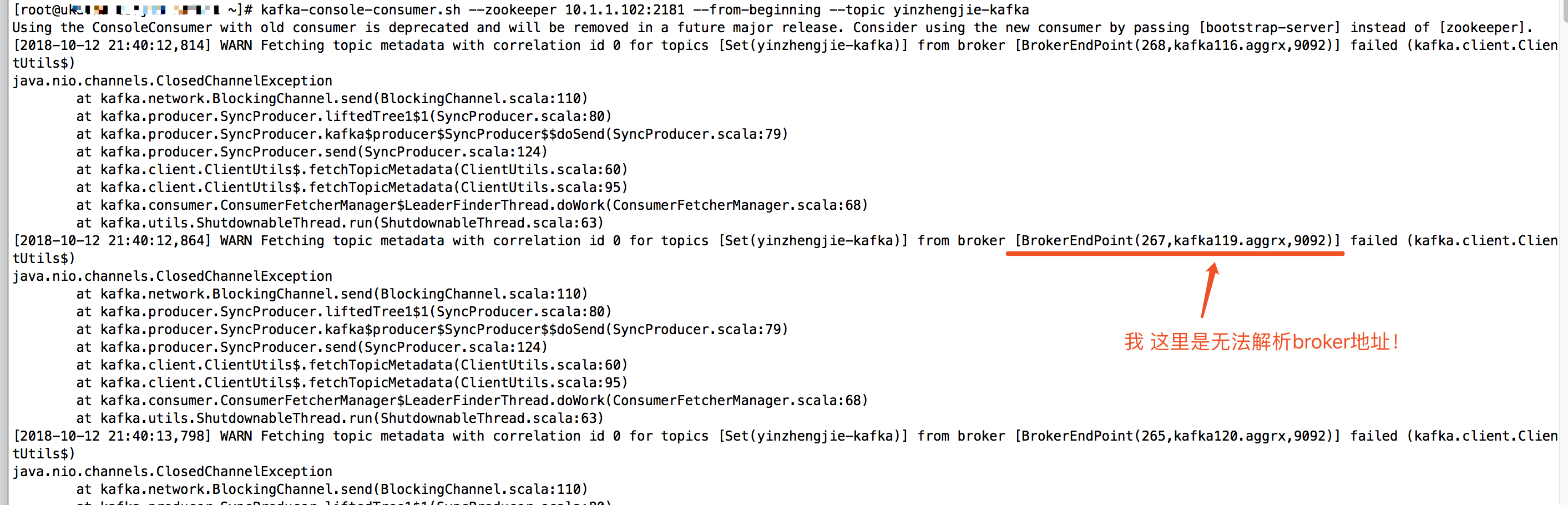
解决办法:
这是由于无法识别我的Kafka集群的主机名,我的解决办法就是修改了Linux的hosts配置文件,
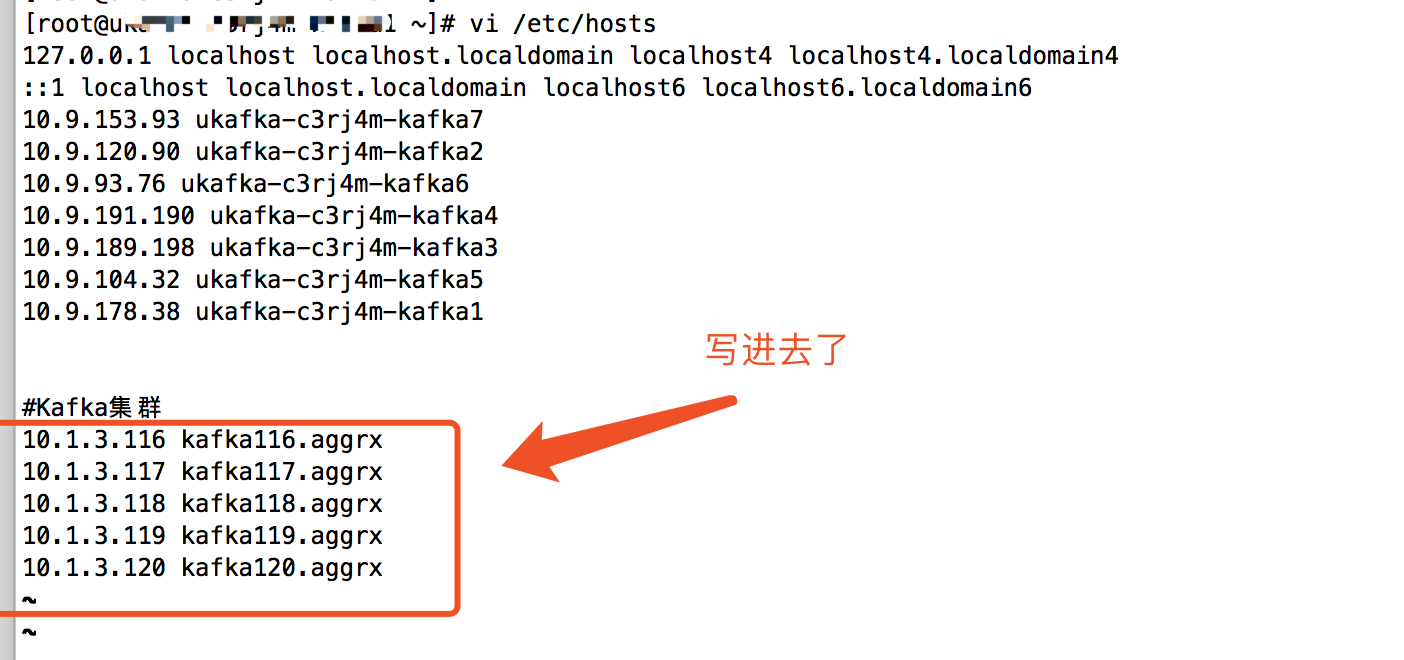
注意,以上两个问题的JDK版本是不一致的,但是问题最终都得到解决,和jdk版本无关!下面是查看java环境
生产者jdk版本如下:

消费者jdk版本如下:

三.使用--bootstrap-server参数无法消费Kafka种的数据
1>.启动生产者

2>.启动消费者拿不到数据

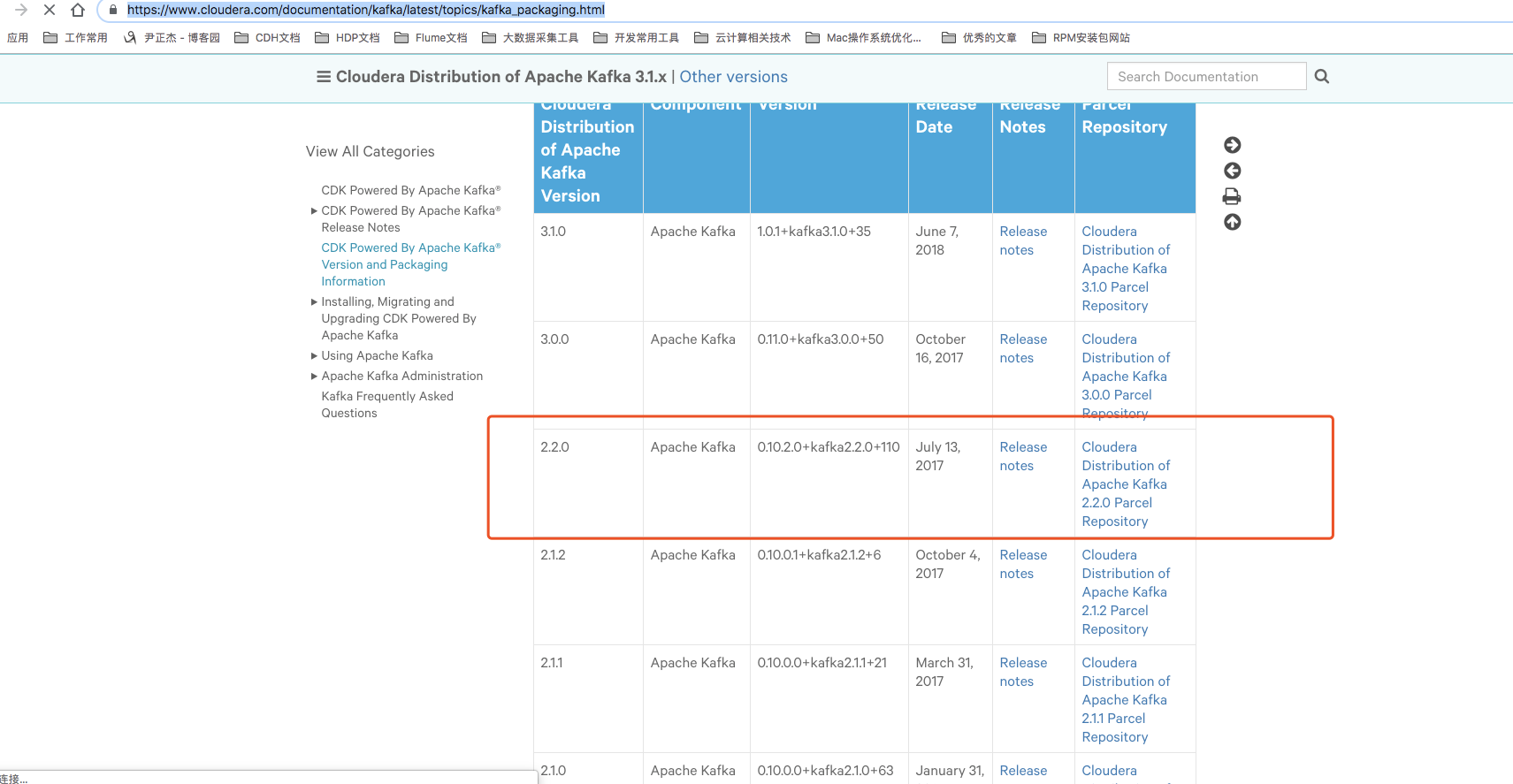
我的这个kafka版本是从:https://www.cloudera.com/documentation/kafka/latest/topics/kafka_packaging.html 下载的0.10.2.0版本。
我下载后采用的是CM部署的,但是无法使用“--bootstrap-server”进行消费。暂时还没有解决办法,打算周末在看看官方文档:http://kafka.apache.org/quickstart 。
好啦!时间不早了,我也该该走了,不然赶不上地铁了!!!晚安,兄弟们!
后记:
第三个问题我谷歌了很久没有找到相应的解决方案,最终我放弃了,使用了apache官方的Kafka版本,最终之前的那些烦恼问题都烟消云散啦!总结一句话,官网最权威!cloudera虽好,但别太过痴迷,如果你公司有钱买企业版本的那就另当别论了!(我生产环境种,使用CM免费版本部署Hadoop生态圈常用组件,将kafka和flume自己采用源码安装!)
关于kafka完全分布式版本可参考我之前的笔记:https://www.cnblogs.com/yinzhengjie/p/9209319.html。
即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?的更多相关文章
- zookeeper+kafka集群的安装部署
准备工作 上传 zookeeper-3.4.6.tar.gz.scala-2.11.4.tgz.kafka_2.9.2-0.8.1.1.tgz.slf4j-1.7.6.zip 至/usr/local目 ...
- kafka集群及监控部署
1. kafka的定义 kafka是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础 ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
- kafka集群与zookeeper集群 配置过程
Kafka的集群配置一般有三种方法,即 (1)Single node – single broker集群: (2)Single node – multiple broker集群: (3)Mult ...
- kafka1:Kafka集群部署步骤
参考: kafka 集群--3个broker 3个zookeeper创建实战 细细品味Kafka_Kafka简介及安装_V1.3http://www.docin.com/p-1291437890.ht ...
- 如何为Kafka集群选择合适的Partitions数量
转载:http://blog.csdn.net/odailidong/article/details/52571901 这是许多kafka使用者经常会问到的一个问题.本文的目的是介绍与本问题相关的一些 ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 大流量大负载的Kafka集群优化实战
前言背景 算法优化改版有大需求要上线,在线特征dump数据逐步放量,最终达到现有Kafka集群5倍的流量,预计峰值达到万兆网卡80%左右(集群有几十个节点,网卡峰值流出流量800MB左右/sec.写入 ...
- Kafka1 利用虚拟机搭建自己的Kafka集群
前言: 上周末自己学习了一下Kafka,参考网上的文章,学习过程中还是比较顺利的,遇到的一些问题最终也都解决了,现在将学习的过程记录与此,供以后自己查阅,如果能帮助到其他人,自然是更好的. ...
随机推荐
- Oracle系列(一): Oracle数据恢复
Oracle数据恢复 在使用Oracle的时候,突然一部小心update或者delete全部数据后怎么办? select * from table as of timestamp to_timest ...
- ASP.NET MVC应用安全性(一)——自定义错误处理
很多 ASP.NET MVC 开发者都会写出高性能的代码,很好地交付软件,等等.但是却并没有安全性方面的计划. 有一种攻击是攻击者截获最终用户提交的表单数据,将其改变再将修改后的数据发送到服务器. ...
- PAT 1002 写出这个数
https://pintia.cn/problem-sets/994805260223102976/problems/994805324509200384 读入一个自然数n,计算其各位数字之和,用汉语 ...
- PyXB: Python XML Schema Bindings
http://pyxb.sourceforge.net/ PyXB (“pixbee”) is a pure Python package that generates Python source c ...
- Glace:generator-jhipster, adding User entity enhancement management
https://github.com/jhipster/generator-jhipster/issues/2538 jhipster,很好用的开发工具.国外知名度高,国内未普及,国外大公司在用. j ...
- jmeter 使用csv文件 注意项
1.首先在jmeter 中导入csv文件时我们程序并不知道csv文件中有多少行 : >1.获取的时候 使用 循环控制器来获取csv文件中的所有数据 : 通过 ${__jexl3("${ ...
- Mark 韦氏拼音 邮政式拼音 和汉语拼音
一直感觉很多大学名字不像是汉语拼音也不像是英文,百度了下原来是三种不同的拼音方式: 转载百度百科: 邮政式拼音和威妥玛拼音法并未完全消失.北京大学(Peking University).清华大学(Ts ...
- U9财务体系
- Linux基础学习(7)--用户和用户组管理
第七章——用户和用户组管理 一.用户配置文件 1.用户信息文件/etc/passwd: (1)用户管理简介:所以越是对服务器安全性要求高的服务器,越需要建立合理的用户权限等级制度和服务器操作规范. ...
- git worktree 是什么及其使用场景
先上总结: 在git worktree出现之前, git切换分支前后的文件都只存在在当前文件夹下, git worktree出现之后, 我们可以将分支切换到其他文件夹下 比如如果你的项目有很多个版本分 ...