即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?
即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.报错:org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.
1>.由于我默认就开启了自动创建topic,因此我们直接启动生产者:kafka-console-producer.sh --broker-list 10.1.3.116:9092 --topic yinzhengjie-kafka (在一台安装jdk8版本的机器上操作)
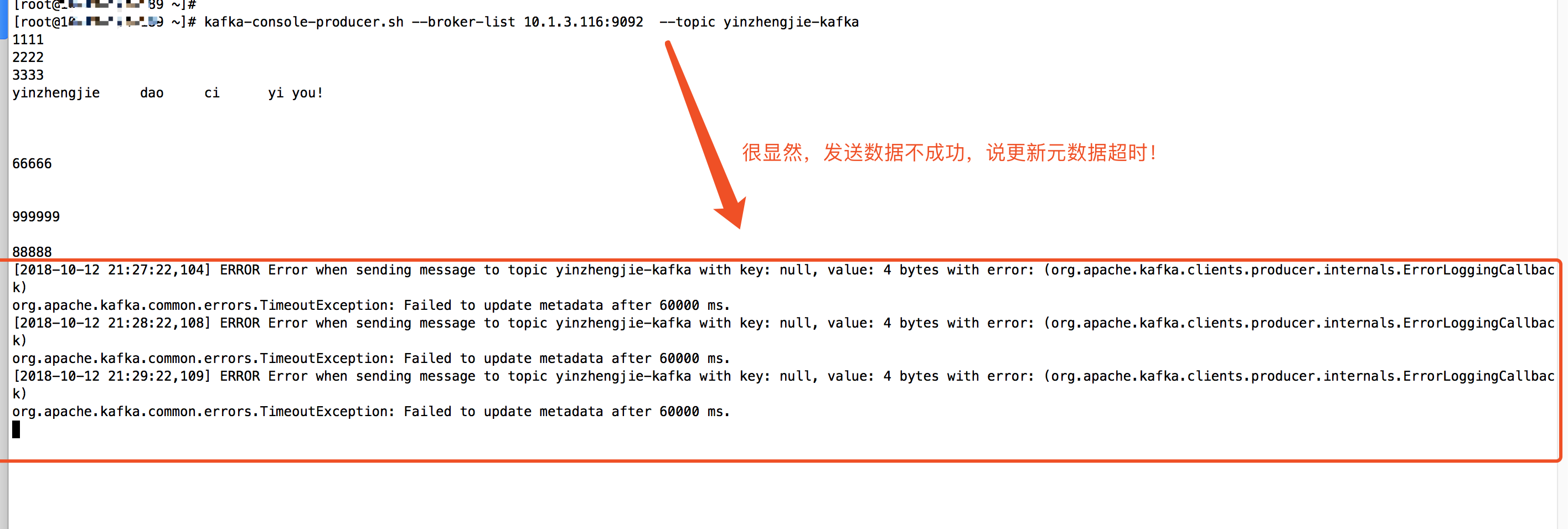
2>.紧接着我们启动消费者,观察是否能收到数据:kafka-console-consumer.sh --zookeeper 10.1.1.102:2181 --from-beginning --topic yinzhengjie-kafka(在一台jdk1.7上操作的)

解决办法:
查看Kafka集群是否正常启动,如果没有启动需要将Kafka集群启动起来!登陆CM观看自己的kafka集群发现该集群还未启动呢,导致的Kafka集群不可用

二.[2018-10-12 21:40:12,864] WARN Fetching topic metadata with correlation id 0 for topics [Set(yinzhengjie-kafka)] from broker [BrokerEndPoint(267,kafka119.aggrx,9092)] failed (kafka.client.ClientUtils$)
1>.由于我默认就开启了自动创建topic,因此我们直接启动生产者:kafka-console-producer.sh --broker-list 10.1.3.116:9092 --topic yinzhengjie-kafka (在一台安装jdk8版本的机器上操作)
2>.紧接着我们启动消费者,观察是否能收到数据:kafka-console-consumer.sh --zookeeper 10.1.1.102:2181 --from-beginning --topic yinzhengjie-kafka(在一台jdk1.7上操作的)
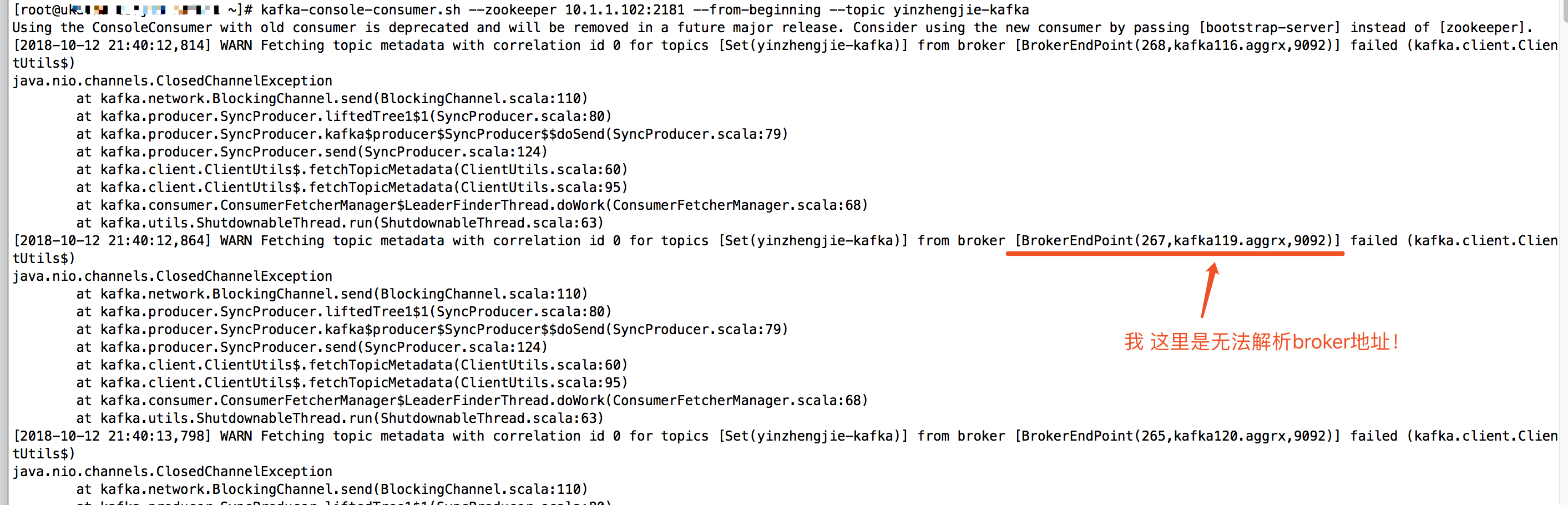
解决办法:
这是由于无法识别我的Kafka集群的主机名,我的解决办法就是修改了Linux的hosts配置文件,
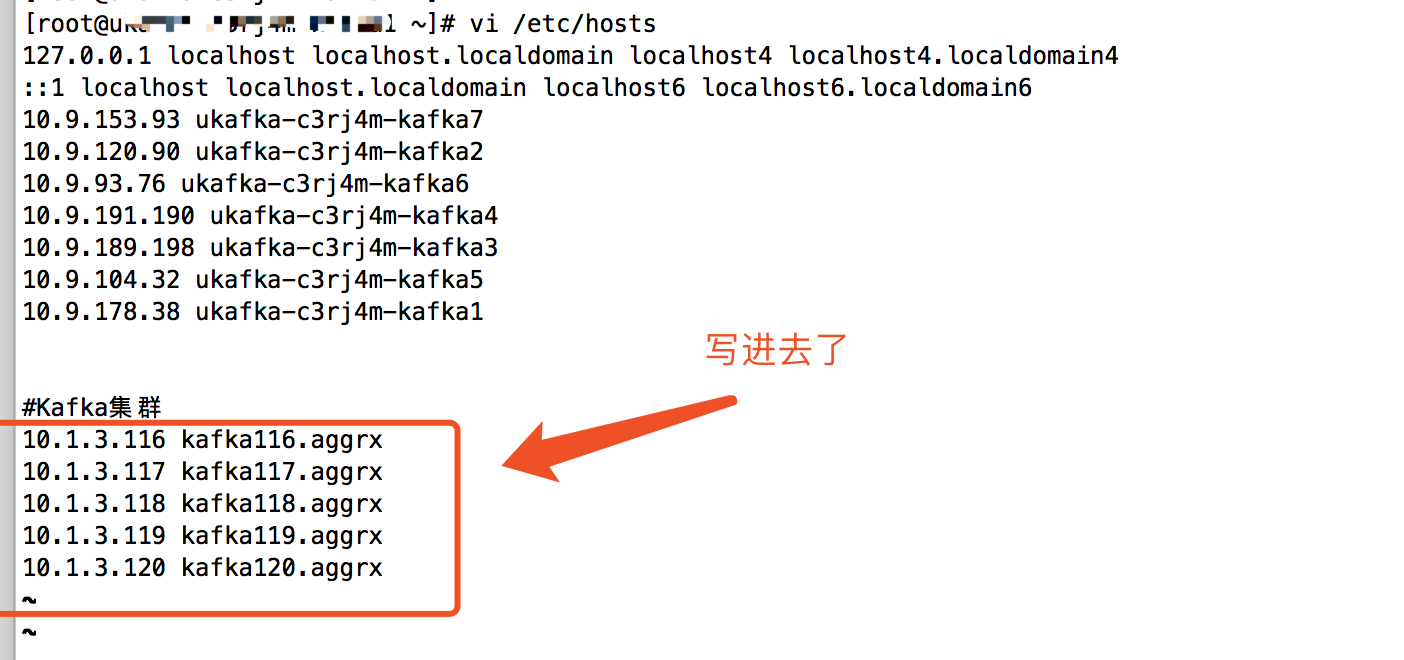
注意,以上两个问题的JDK版本是不一致的,但是问题最终都得到解决,和jdk版本无关!下面是查看java环境
生产者jdk版本如下:

消费者jdk版本如下:

三.使用--bootstrap-server参数无法消费Kafka种的数据
1>.启动生产者

2>.启动消费者拿不到数据

我的这个kafka版本是从:https://www.cloudera.com/documentation/kafka/latest/topics/kafka_packaging.html 下载的0.10.2.0版本。
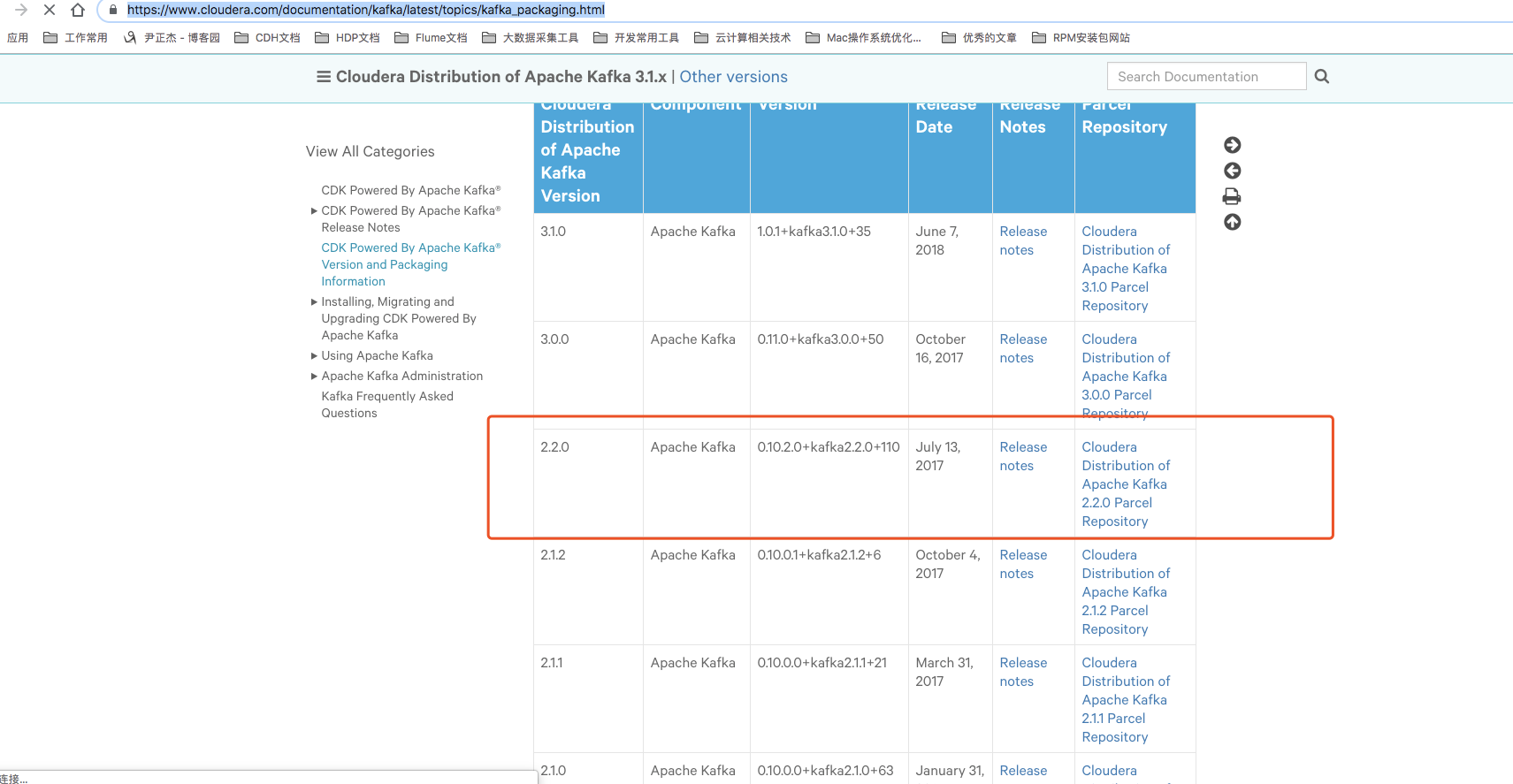
我下载后采用的是CM部署的,但是无法使用“--bootstrap-server”进行消费。暂时还没有解决办法,打算周末在看看官方文档:http://kafka.apache.org/quickstart 。
好啦!时间不早了,我也该该走了,不然赶不上地铁了!!!晚安,兄弟们!
后记:
第三个问题我谷歌了很久没有找到相应的解决方案,最终我放弃了,使用了apache官方的Kafka版本,最终之前的那些烦恼问题都烟消云散啦!总结一句话,官网最权威!cloudera虽好,但别太过痴迷,如果你公司有钱买企业版本的那就另当别论了!(我生产环境种,使用CM免费版本部署Hadoop生态圈常用组件,将kafka和flume自己采用源码安装!)
关于kafka完全分布式版本可参考我之前的笔记:https://www.cnblogs.com/yinzhengjie/p/9209319.html。
即将上线的Kafka 集群(用CM部署的)无法使用“--bootstrap-server”进行消费,怎么破?的更多相关文章
- zookeeper+kafka集群的安装部署
准备工作 上传 zookeeper-3.4.6.tar.gz.scala-2.11.4.tgz.kafka_2.9.2-0.8.1.1.tgz.slf4j-1.7.6.zip 至/usr/local目 ...
- kafka集群及监控部署
1. kafka的定义 kafka是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础 ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
- kafka集群与zookeeper集群 配置过程
Kafka的集群配置一般有三种方法,即 (1)Single node – single broker集群: (2)Single node – multiple broker集群: (3)Mult ...
- kafka1:Kafka集群部署步骤
参考: kafka 集群--3个broker 3个zookeeper创建实战 细细品味Kafka_Kafka简介及安装_V1.3http://www.docin.com/p-1291437890.ht ...
- 如何为Kafka集群选择合适的Partitions数量
转载:http://blog.csdn.net/odailidong/article/details/52571901 这是许多kafka使用者经常会问到的一个问题.本文的目的是介绍与本问题相关的一些 ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 大流量大负载的Kafka集群优化实战
前言背景 算法优化改版有大需求要上线,在线特征dump数据逐步放量,最终达到现有Kafka集群5倍的流量,预计峰值达到万兆网卡80%左右(集群有几十个节点,网卡峰值流出流量800MB左右/sec.写入 ...
- Kafka1 利用虚拟机搭建自己的Kafka集群
前言: 上周末自己学习了一下Kafka,参考网上的文章,学习过程中还是比较顺利的,遇到的一些问题最终也都解决了,现在将学习的过程记录与此,供以后自己查阅,如果能帮助到其他人,自然是更好的. ...
随机推荐
- 作业七:Linux内核如何装载和启动一个可执行程序
作业七:Linux内核如何装载和启动一个可执行程序 一.编译链接的过程和ELF可执行文件格式 可执行文件的创建——预处理.编译和链接 在object文件中有三种主要的类型. 一个可重定位(reloca ...
- Linux内核总结博客 20135332武西垚
http://www.cnblogs.com/wuxiyao/p/5220677.htmlhttp://www.cnblogs.com/wuxiyao/p/5247571.htmlhttp://www ...
- JQuery监听页面滚动总结
1.当前滚动的地方的窗口顶端到整个页面顶端的距离: var winPos = $(window).scrollTop(); 2.获取指定元素的页面位置: $(val).offset().top; 3. ...
- David Silver强化学习Lecture3:动态规划
课件:Lecture 3: Planning by Dynamic Programming 视频:David Silver强化学习第3课 - 动态规划(中文字幕) 动态规划 动态(Dynamic): ...
- select、poll、epoll之间的区别总结[整理]【转】
转自:http://www.cnblogs.com/Anker/p/3265058.html select,poll,epoll都是IO多路复用的机制.I/O多路复用就通过一种机制,可以监视多个描述符 ...
- React 组件库框架搭建
前言 公司业务积累了一定程度,需要搭建自己的组件库,有了组件库,整个团队开发效率会提高恨多. 做组件库需要提供开发调试环境,和组件文档的展示,调研了几个比较主流的方案,如下: docz 配置简单,功能 ...
- \r\n
转载自http://www.studyofnet.com/news/285.html '\r'是回车,'\n'是换行,前者使光标到行首,后者使光标下移一格,通常敲一个回车键,即是回车,又是换行(\r\ ...
- std::binary_serach, std::upper_bound以及std::lower_bound
c++二分查找的用法 主要是 std::binary_serach, std::upper_bound以及std::lower_bound 的用法,示例如下: std::vector<int& ...
- hadoop MapReduce 入门
原创播客,如需转载请注明出处.原文地址:http://www.cnblogs.com/crawl/p/7687120.html ------------------------------------ ...
- Codeforces Round #412 B. T-Shirt Hunt
B. T-Shirt Hunt time limit per test 2 seconds memory limit per test 256 megabytes input standard inp ...