python小demo-01: 线程池+多进程实现cpu密集型操作
起因:
公司有一个小项目,大概逻辑如下:
服务器A会不断向队列中push消息,消息主要内容是视频的地址,服务器B则需要不断从队列中pop消息,然后将该视频进行剪辑最终将剪辑后的视频保存到云服务器。个人主要实现B服务器逻辑。
实现思路:
1 线程池+多进程
要求点一:主进程要以daemon的方式运行。
要求点二:利用线程池,设置最大同时运行的worker,每一个线程通过调用subprocess中的Popen来运行wget ffprobe ffmpeg等命令处理视频。
2 消息队列采用redis的list实现
3 主线程从队列中获取到消息后,从线程池中获取空闲从线程(在这里,非主线程统称为从线程,下同),从线程对该消息做一些逻辑上的处理后,然后生成进程对视频进行剪辑,最后上传视频。
要求点三:为了让daemon能在收到signint信号时,处理完当前正在进行的worker后关闭,且不能浪费队列中的数据,需要让主进程在有空闲worker时才从队列中获取数据。
大概就是这样:
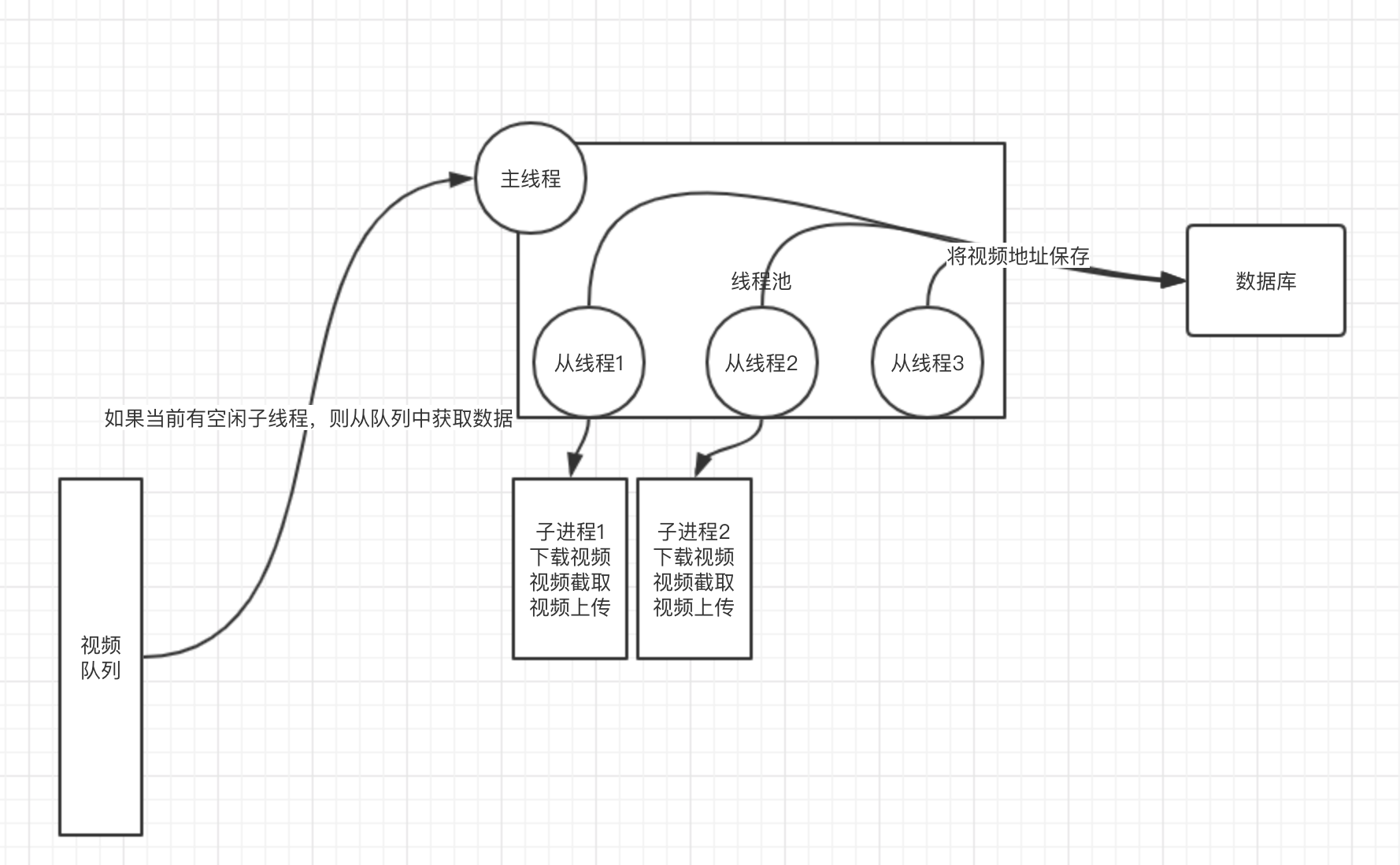
基本上主要资源耗费在视频下载以及视频处理上,且同时运行的worker(从线程)不会太多(一般cpu有几个就设置几个worker)。
上面一共有三个要求点,其中要求点二并不费事。所以忽略。
实现
要求点一实现:
# -*- coding: utf8 -*-
import os
import sys
import time
import signal
import traceback # from shadowsocks
def write_pid_file(pid_file, pid):
import fcntl
import stat try:
fd = os.open(pid_file, os.O_RDWR | os.O_CREAT,
stat.S_IRUSR | stat.S_IWUSR)
except OSError:
traceback.print_exc()
return -1
flags = fcntl.fcntl(fd, fcntl.F_GETFD)
assert flags != -1
flags |= fcntl.FD_CLOEXEC
r = fcntl.fcntl(fd, fcntl.F_SETFD, flags)
assert r != -1
# There is no platform independent way to implement fcntl(fd, F_SETLK, &fl)
# via fcntl.fcntl. So use lockf instead
try:
fcntl.lockf(fd, fcntl.LOCK_EX | fcntl.LOCK_NB, 0, 0, os.SEEK_SET)
except IOError:
r = os.read(fd, 32)
if r:
print('already started at pid %s' % (r))
else:
print('already started')
os.close(fd)
return -1
os.ftruncate(fd, 0)
os.write(fd, (str(pid)))
return 0 def freopen(f, mode, stream):
oldf = open(f, mode)
oldfd = oldf.fileno()
newfd = stream.fileno()
os.close(newfd)
os.dup2(oldfd, newfd) def daemon_start(settings, main_process_handler):
def handle_exit(signum, _):
if signum == signal.SIGTERM:
sys.exit(0)
sys.exit(1) signal.signal(signal.SIGINT, handle_exit)
signal.signal(signal.SIGTERM, handle_exit)
pid = os.fork()
assert pid != -1 # Parent
if pid:
time.sleep(3)
sys.exit(0) print("child has forked")
# child signals its parent to exit
ppid = os.getppid()
pid = os.getpid()
if write_pid_file(settings.PID_FILE, pid) != 0:
os.kill(ppid, signal.SIGINT)
sys.exit(1) # set self to process-group-leader
os.setsid() signal.signal(signal.SIGHUP, signal.SIG_IGN) print('started')
os.kill(ppid, signal.SIGTERM) # octal 022
os.umask(18)
sys.stdin.close()
try:
freopen(settings.DEBUG_LOG_PATH, 'a', sys.stdout)
freopen(settings.DEBUG_LOG_PATH, 'a', sys.stderr)
except IOError:
print(traceback.print_exc())
sys.exit(1) main_process_handler() def daemon_stop(pid_file):
import errno
try:
with open(pid_file) as f:
pid = buf = f.read()
if not buf:
print('not running')
except IOError as e:
print(traceback.print_exc())
if e.errno == errno.ENOENT:
print("not running")
# always exit 0 if we are sure daemon is not running
return
sys.exit(1)
pid = int(pid)
if pid > 0:
try:
os.kill(pid, signal.SIGTERM)
except OSError as e:
if e.errno == errno.ESRCH:
print('not running')
# always exit 0 if we are sure daemon is not running
return
print(traceback.print_exc())
sys.exit(1)
else:
print('pid is not positive: %d', pid) # sleep for maximum 300s
for i in range(0, 100):
try:
# query for the pid
os.kill(pid, 0)
except OSError as e:
# not found the process
if e.errno == errno.ESRCH:
break
time.sleep(3)
print("waiting for all threads finished....")
else:
print('timed out when stopping pid %d', pid)
sys.exit(1)
print('stopped')
os.unlink(pid_file) def main():
args = sys.argv[1:]
assert len(args) == 2
if args[0] not in ["stop", "start"]:
print("only supported: [stop | start]")
return
if args[1] not in ["dev", "local", "prod"]:
print("only supported: [dev | local | prod]") from globals import set_settings, initialize_redis
set_settings(args[1])
initialize_redis()
from globals import settings
import entry if args[0] == "stop":
print("stopping...")
daemon_stop(settings.PID_FILE)
elif args[0] == "start":
print("starting...")
daemon_start(settings, entry.run) main()
daemon.py
要求点三实现:
线程池,采用python的futures模块。该模块提供了线程池的机制。稍微说一下他的线程池实现原理吧,ThreadPoolExecutor该类实现了线程池:
1 每个实例本身有个_work_queue属性,这是一个Queue对象,里面存储了任务。
2 每当我们调用该对象的submit方法时,都会向其_work_queue中放入一个任务,同时生成从线程,直到从线程数达到max_worker所设定的值。
3 该线程池实例中所有的从线程会不断的从_work_queue中获取任务,并执行。同时从线程的daemon属性被设置为True
# -*- coding: utf8 -*-
import json
import traceback
import signal
import sys
import time
from threading import Lock
from concurrent.futures import ThreadPoolExecutor
from .globals import settings, video_info_queue def handler(data):
# 业务逻辑 running_futures_count = 0 def run():
global running_futures_count
count_lock = Lock() pool = ThreadPoolExecutor(max_workers=settings.MAX_WORKER)
try:
def reduce_count(_):
global running_futures_count
with count_lock:
running_futures_count -= 1 def handle_exit(_, __):
print("get SIGINT signal")
pool.shutdown(False)
while True:
if running_futures_count == 0:
sys.exit(0)
time.sleep(1)
print("now running futures count is %s, please wait" % running_futures_count) def handle_data(data):
global running_futures_count
with count_lock:
running_futures_count += 1
future = pool.submit(handler, data)
future.add_done_callback(reduce_count) signal.signal(signal.SIGINT, handle_exit)
signal.signal(signal.SIGTERM, handle_exit) while not pool._shutdown:
print(len(pool._work_queue.queue), pool._shutdown)
while not pool._shutdown and (len(pool._work_queue.queue) < pool._max_workers):
data = video_info_queue.bpop(20)
if data:
handle_data(data)
else:
data = abnormal_video_info_queue.bpop(1)
print("video_info_queue is empty, get data: %s from abnormal_video_info_queue" % data)
if data:
print("abnormal_video_info_queue")
handle_data(data)
time.sleep(5)
print("now all the workers is busy, so wait and do not submit")
finally:
pool.shutdown(False)
entry.py
重点就是那嵌套的while循环。
踩坑&收获:
1 python中只有主线程才能处理信号,如果使用线程中的join方法阻塞主线程,如果从线程运行时间过长可能会导致信号长时间无法处理。所以尽量设置从线程的daemon为True。
2 Queue的底层是deque,而deque的底层是一个双端链表,为什么用双端链表而不用list?答案请在参考中找。
3 学会了进程以daemon方式运行的实现方式:
1 pid文件的来源
2 进程以及进程组的概念
3 信号的捕捉
4 dup2函数以及fcntl函数
4 进程使用Popen()创建时,如果用PIPE作为子进程(stdin stdout stderr)与父进程进行交互时,然后调用wait时,如果子进程的stdin stdout stderr中某个数据过多可能会导致主进程卡死。原因也在参考中找。
5 sudo执行脚本时环境变量去哪了?答案请在参考中找
6 python中的weakref模块很有用啊
参考:
1 http://blog.sina.com.cn/s/blog_4da051a60102uyvg.html
2 https://toutiao.io/posts/zr31ak/preview
3 https://www.cnblogs.com/chybot/p/5176118.html
5 http://siwind.iteye.com/blog/1753517
6 https://www.jianshu.com/p/646d1d09fc53
9 shadowsocks源码
python小demo-01: 线程池+多进程实现cpu密集型操作的更多相关文章
- 你创建线程池最好分为两种线程池,io密集型线程池,或者cpu密集型线程池
你创建线程池最好分为两种线程池,io密集型线程池,或者cpu密集型线程池. 否则,如果只用一个线程池的话,不管是iO密集的线程,或者cpu消耗大的都放在同一个线程池的话,会发生线程池被撑满的情况
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- python自带的线程池和进程池
#python自带的线程池 from multiprocessing.pool import ThreadPool #注意ThreadPool不在threading模块下 from multiproc ...
- python(13)线程池:threading
先上代码: pool = threadpool.ThreadPool(10) #建立线程池,控制线程数量为10 reqs = threadpool.makeRequests(get_title, da ...
- Python并发编程之线程池/进程池--concurrent.futures模块
一.关于concurrent.futures模块 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/ ...
- python——有一种线程池叫做自己写的线程池
这周的作业是写一个线程池,python的线程一直被称为鸡肋,所以它也没有亲生的线程池,但是竟然被我发现了野生的线程池,简直不能更幸运~~~于是,我开始啃源码,实在是虐心,在啃源码的过程中,我简略的了解 ...
- python 收录集中实现线程池的方法
概念: 什么是线程池? 诸如web服务器.数据库服务器.文件服务器和邮件服务器等许多服务器应用都面向处理来自某些远程来源的大量短小的任务.构建服务器应用程序的一个过于简单的模型是:每当一个请求到达就创 ...
- Python并发编程之线程池&进程池
引用 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/销毁进程或者线程是非常消耗资源的,这个时候我 ...
- Java多线程系列 JUC线程池01 线程池框架
转载 http://www.cnblogs.com/skywang12345/p/3509903.html 为什么引入Executor线程池框架 new Thread()的缺点 1. 每次new T ...
随机推荐
- Notes of Daily Scrum Meeting(12.23)
今天的团队任务总结如下: 团队成员 今日团队工作 陈少杰 调试网络连接,寻找新的连接方法 王迪 建立搜索的UI界面 金鑫 查阅相关资料,熟悉后台的接口 雷元勇 建立搜索的界面 高孟烨 继续美化界面,熟 ...
- Linux内核分析第四章读书笔记
第四章 进程调度 进程调度程序:确保进程能有效工作的一个内核子程序 决定将哪个进程投入运行,何时运行已经运行多长时间 进程调度程序可看做在可运行态进程之间分配有限的处理器时间资源的内核子系统 原则:只 ...
- Linux内核 实践二
实践二 内核模块编译 20135307 张嘉琪 一.实验原理 Linux模块是一些可以作为独立程序来编译的函数和数据类型的集合.之所以提供模块机制,是因为Linux本身是一个单内核.单内核由于所有内容 ...
- 关于对springboot程序配置文件使用jasypt开源工具自定义加密
一.前言 在工作中遇到需要把配置文件加密的要求,很容易就在网上找到了开源插件 jasypt (https://github.com/ulisesbocchio/jasypt-spring-boot# ...
- Leetcode 546. Remove Boxes
题目链接: https://leetcode.com/problems/remove-boxes/description/ 问题描述 若干个有序排列的box和它们的颜色,每次可以移除若干个连续的颜色相 ...
- spring 注入DI
web 项目的搭建 以注入对象的方式
- 转载 loadrunner的一些问题解决
sckOutOfMemory 7 内存不足 sckInvalidPropertyValue 380 属性值不效 sckGetNotSupported 394 属性不可读 sckGetNotSup ...
- [转帖]2016年时的新闻:ASP.NET Core 1.0、ASP.NET MVC Core 1.0和Entity Framework Core 1.0
ASP.NET Core 1.0.ASP.NET MVC Core 1.0和Entity Framework Core 1.0 http://www.cnblogs.com/webapi/p/5673 ...
- vCenter简单查看多少虚拟机在开机状态和一共多少虚拟机
vCenter 界面上面不好找 具体的开机 运行数目 但是数据库里面比较好差 登录vCenter的数据库. 查看表主要是 查看正在开机的虚拟机 select * from dbo.VPX_VM WHE ...
- poj 1904(强连通分量+输入输出外挂)
题目链接:http://poj.org/problem?id=1904 题意:有n个王子,每个王子都有k个喜欢的妹子,每个王子只能和喜欢的妹子结婚,大臣给出一个匹配表,每个王子都和一个妹子结婚,但是国 ...