Kafka记录-Kafka简介与单机部署测试
1.Kafka简介
kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容
2.Kafka的架构组件
1、话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名;
2、生产者(Producer):是能够发布消息到话题的任何对象;
3、服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群,broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。
4、消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息;
我们将消息的发布(publish)称作 producer,将消息的订阅(subscribe)表述为 consumer,将中间的存储阵列称作 broker(代理),这样就可以大致描绘出这样一个场面:

生产者将数据生产出来,交给 broker 进行存储,消费者需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理操作。producer 到 broker 的过程是 push,也就是有数据就推送到 broker,而 consumer 到 broker 的过程是 pull,是通过 consumer 主动去拉数据的,而不是 broker 把数据主动发送到 consumer 端的。
简单说下整个系统运行的顺序:
(1)启动zookeeper 的 server
(2)启动kafka 的 server
(3)Producer 如果生产了数据,会先通过 zookeeper 找到 broker,然后将数据存放到 broker
(4)Consumer 如果要消费数据,会先通过 zookeeper 找对应的 broker,然后消费。
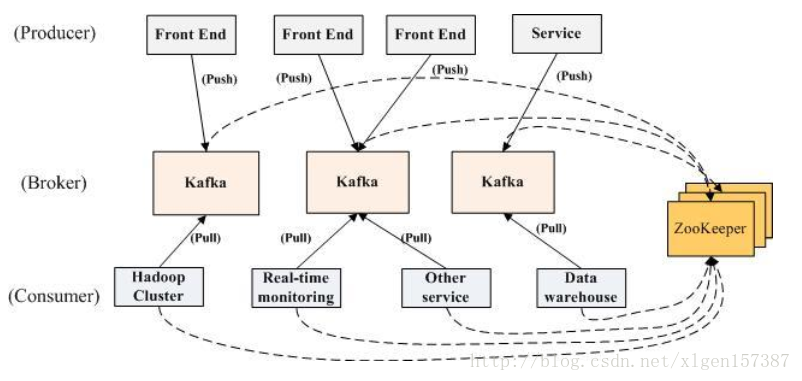
多个 broker 协同合作,producer 和 consumer 部署在各个业务逻辑中被频繁的调用,三者通过 zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布订阅系统就完成了。
3.Zookeeper在kafka的作用
(1)无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
(2)Kafka使用zookeeper作为其分布式协调框架,很好的将消息生产、消息存储、消息消费的过程结合在一起。
(3)同时借助zookeeper,kafka能够生产者、消费者和broker在内的所以组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
4.Kafka的特性
(1)高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,
每个topic可以分多个partition, consumer group 对partition进行consume操作;
(2)可扩展性:kafka集群支持热扩展;
(3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
(4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
(5)高并发:支持数千个客户端同时读写;
(6)支持实时在线处理和离线处理:可以使用Storm这种实时流处理系统对消息进行实时进行处理,同时还可以使用Hadoop这种批处理系统进行离线处理;
5.Kafka的使用场景
(1)日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,
例如Hadoop、Hbase、Solr等;
(2)消息系统:解耦和生产者和消费者、缓存消息等;
(3)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
(4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
(5)流式处理:比如spark streaming和storm;
(6)事件源;
6.Kafka单机部署
6.1 配置jdk/zookeeper/kafka
6.2 启动zookeeper
配置zoo.cfg
sh $zookeeper_home/bin/zkServer.sh start
6.3 配置kafka
#配置kafka/config/server.properties
mkdir -p /usr/app/kafka/logs/kafka #创建kafka日志目录
cd /usr/app/kafka/config #进入配置目录
vim server.properties #编辑修改相应的参数
broker.id=0
port=9092 #端口号
host.name=192.168.66.66 #服务器IP地址,修改为自己的服务器IP
log.dirs=/usr/app/kafka/logs/kafka #日志存放路径,上面创建的目录
zookeeper.connect=localhost:2181 #zookeeper地址和端口,单机配置部署,localhost:2181
#配置kafka下的zookeeper
mkdir -p /usr/app/kafka/zookeeper #创建zookeeper目录
mkdir -p /usr/app/kafka/logs/zookeeper #创建zookeeper日志目录
cd /usr/app/kafka/config #进入配置目录
vi zookeeper.properties #编辑修改相应的参数
dataDir=/usr/app/kafka/zookeeper #zookeeper数据目录
dataLogDir=/usr/app/kafka/log/zookeeper #zookeeper日志目录
clientPort=2181
maxClientCnxns=100
tickTime=2000
initLimit=10
#常用命令操作
vim kafkastart.sh
#!/bin/bash
#启动zookeeper ---自带zookeeper
#/usr/app/kafka/bin/zookeeper-server-start.sh /usr/app/kafka/config/zookeeper.properties &
#sleep 3 #等3秒后执行
#启动kafka
/usr/app/kafka/bin/kafka-server-start.sh /usr/app/kafka/config/server.properties &
vim kafkastop.sh
#!/bin/bash
#关闭zookeeper
#/usr/app/kafka/bin/zookeeper-server-stop.sh /usr/app/kafka/config/zookeeper.properties &
#sleep 3 #等3秒后执行
#关闭kafka
/usr/app/kafka/bin/kafka-server-stop.sh /usr/app/kafka/config/server.properties &
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 topic test ---创建topic test
./bin/kafka-topics.sh --list --zookeeper localhost:2181 ---查看所有topic

./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test 生产消息测试
推送输入消息
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning --topic test 消费消息测试
主动拉入消息
./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test ---查看指定的topic
#集群节点测试
#创建主题
kafka-topics --create --zookeeper 10.0.4.142:2181/kafka --replication-factor 1 --partitions 1 --topic test
#查看主题列表
kafka-topics --list --zookeeper 10.0.4.142:2181/kafka
#展示主题描述
kafka-topics --describe --zookeeper 10.0.4.142:2181/kafka --topic test
#生产者推送消息
kafka-console-producer --broker-list 10.0.4.142:9092 --topic test
#消费者拉入消息
kafka-console-consumer --zookeeper 10.0.4.142:2181/kafka --topic test --from-beginnin
#删除主题
kafka-topics.sh --delete --zookeeper 10.0.4.142:2181/kafka --topic tests
Kafka记录-Kafka简介与单机部署测试的更多相关文章
- Zookeeper(一)-- 简介以及单机部署和集群部署
一.分布式系统 由多个计算机组成解决同一个问题的系统,提高业务的并发,解决高并发问题. 二.分布式环境下常见问题 1.节点失效 2.配置信息的创建及更新 3.分布式锁 三.Zookeeper 1.定义 ...
- kafka集群部署以及单机部署
kafka单机部署 一.环境准备 当前环境:centos7.3一台软件版本:kafka_2.12部署目录:/usr/local/kafka启动端口:9092配置文件:/usr/local/kafk ...
- linux单机部署kafka(filebeat+elk组合)
filebeat+elk组合之kafka单机部署 准备: kafka下载链接地址:http://kafka.apache.org/downloads.html 在这里下载kafka_2.12-2.10 ...
- Linux下部署Kafka分布式集群,安装与测试
注意:部署Kafka之前先部署环境JAVA.Zookeeper 准备三台CentOS_6.5_x64服务器,分别是:IP: 192.168.0.249 dbTest249 Kafka IP: 192. ...
- 一、最新Kafka单节点部署+测试 完整
每次学一个东西从基础的开始,循序渐进. 不急不躁,路还很长. 所有教程都是学习汪文君大神的kafka教程的. 一.部署 这里选的kafka版本是 0.10.2.1 下载连接 https://dow ...
- OpenResty + Lua + Kafka 实现日志收集系统以及部署过程中遇到的坑
********************* 部署过程 ************************** 一:场景描述 对于线上大流量服务或者需要上报日志的nginx服务,每天会产生大量的日志,这些 ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- CentOS 7部署Kafka和Kafka集群
CentOS 7部署Kafka和Kafka集群 注意事项 需要启动多个shell脚本交互客户端进行验证,运行中的客户端不要停止. 准备工作: 安装java并设置java环境变量,在`/etc/prof ...
- kafka集群监控之kafka-manager部署(kafka-manager的进程为:ProdServerStart)
kafka集群监控之kafka-manager部署(ProdServerStart) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 雅虎官网GitHub项目:https://git ...
随机推荐
- js和JQuery区别
this.class="btn-default btn-info"; $(this).toggleClass("btn-default btn-info"); ...
- 安装rlwrap 的简单方法
1. 下载安装 epel包 rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm 2. 安装r ...
- [读书笔记]Linux命令行与shell编程读书笔记03 文件系统等
1. 文件系统的种类 ext ext2 ext3 ext4 JFS XFS 其中ext3 开始支持journal日志模式 与raid卡类似 有 数据模式 排序模式 以及回写模式 数据模式最安全 回写 ...
- SQLPLUS SQLCMD连接管理oracle sqlserver的简单用法
1. SQLPLUS 与plsql一样,其实不需要安装oracle客户端,只要是有sqlplus的即时客户端 以及将目录放置到path或者是相应的oralce_home变量中即可. 打开运行cmd s ...
- panda迭代
1.注意 - 不要尝试在迭代时修改任何对象.迭代是用于读取,迭代器返回原始对象(视图)的副本,因此更改将不会反映在原始对象上. 2.itertuples()方法将为DataFrame中的每一行返回一个 ...
- 【转】Caffe的solver文件配置
http://blog.csdn.net/czp0322/article/details/52161759 solver.prototxt 今天在做FCN实验的时候,发现solver.prototxt ...
- 51nod1268(基础dfs)
解题思路:直接搜索找就行了,搜两边,一个是加入这个数字,一边是不加入这个数字 代码: #include<iostream>#include<algorithm>#define ...
- JSON:如果你愿意一层一层剥开我的心,你会发现...这里水很深——深入理解JSON
我们先来看一个JS中常见的JS对象序列化成JSON字符串的问题,请问,以下JS对象通过JSON.stringify后的字符串是怎样的?先不要急着复制粘贴到控制台,先自己打开一个代码编辑器或者纸,写写看 ...
- ansible系列1-批量分发钥匙
auth.yaml- hosts: all gather_facts: false tasks: - name: deliver authorized_keys authorized_key: use ...
- Colored Sticks POJ - 2513(trie树欧拉路)
题意: 就是无向图欧拉路 解析: 不能用map..超时 在判断是否只有一个联通的时候,我比较喜欢用set,但也不能用set,会超时,反正不能用stl emm 用trie树来编号就好了 #include ...