lucene源码分析(3)facet实例
简单的facet实例
public class SimpleFacetsExample {
private final Directory indexDir = new RAMDirectory();
private final Directory taxoDir = new RAMDirectory();
private final FacetsConfig config = new FacetsConfig();
/** Empty constructor */
public SimpleFacetsExample() {
config.setHierarchical("Publish Date", true);
}
/** Build the example index. */
private void index() throws IOException {
IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig(
new WhitespaceAnalyzer()).setOpenMode(OpenMode.CREATE));
// Writes facet ords to a separate directory from the main index
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir);
Document doc = new Document();
doc.add(new FacetField("Author", "Bob"));
doc.add(new FacetField("Publish Date", "2010", "10", "15"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Lisa"));
doc.add(new FacetField("Publish Date", "2010", "10", "20"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Lisa"));
doc.add(new FacetField("Publish Date", "2012", "1", "1"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Susan"));
doc.add(new FacetField("Publish Date", "2012", "1", "7"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Frank"));
doc.add(new FacetField("Publish Date", "1999", "5", "5"));
indexWriter.addDocument(config.build(taxoWriter, doc));
indexWriter.close();
taxoWriter.close();
}
/** User runs a query and counts facets. */
private List<FacetResult> facetsWithSearch() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
// MatchAllDocsQuery is for "browsing" (counts facets
// for all non-deleted docs in the index); normally
// you'd use a "normal" query:
FacetsCollector.search(searcher, new MatchAllDocsQuery(), 10, fc);
// Retrieve results
List<FacetResult> results = new ArrayList<>();
// Count both "Publish Date" and "Author" dimensions
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
/** User runs a query and counts facets only without collecting the matching documents.*/
private List<FacetResult> facetsOnly() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
// MatchAllDocsQuery is for "browsing" (counts facets
// for all non-deleted docs in the index); normally
// you'd use a "normal" query:
searcher.search(new MatchAllDocsQuery(), fc);
// Retrieve results
List<FacetResult> results = new ArrayList<>();
// Count both "Publish Date" and "Author" dimensions
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
/** User drills down on 'Publish Date/2010', and we
* return facets for 'Author' */
private FacetResult drillDown() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
// Passing no baseQuery means we drill down on all
// documents ("browse only"):
DrillDownQuery q = new DrillDownQuery(config);
// Now user drills down on Publish Date/2010:
q.add("Publish Date", "2010");
FacetsCollector fc = new FacetsCollector();
FacetsCollector.search(searcher, q, 10, fc);
// Retrieve results
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
FacetResult result = facets.getTopChildren(10, "Author");
indexReader.close();
taxoReader.close();
return result;
}
/** User drills down on 'Publish Date/2010', and we
* return facets for both 'Publish Date' and 'Author',
* using DrillSideways. */
private List<FacetResult> drillSideways() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
// Passing no baseQuery means we drill down on all
// documents ("browse only"):
DrillDownQuery q = new DrillDownQuery(config);
// Now user drills down on Publish Date/2010:
q.add("Publish Date", "2010");
DrillSideways ds = new DrillSideways(searcher, config, taxoReader);
DrillSidewaysResult result = ds.search(q, 10);
// Retrieve results
List<FacetResult> facets = result.facets.getAllDims(10);
indexReader.close();
taxoReader.close();
return facets;
}
/** Runs the search example. */
public List<FacetResult> runFacetOnly() throws IOException {
index();
return facetsOnly();
}
/** Runs the search example. */
public List<FacetResult> runSearch() throws IOException {
index();
return facetsWithSearch();
}
/** Runs the drill-down example. */
public FacetResult runDrillDown() throws IOException {
index();
return drillDown();
}
/** Runs the drill-sideways example. */
public List<FacetResult> runDrillSideways() throws IOException {
index();
return drillSideways();
}
/** Runs the search and drill-down examples and prints the results. */
public static void main(String[] args) throws Exception {
System.out.println("Facet counting example:");
System.out.println("-----------------------");
SimpleFacetsExample example = new SimpleFacetsExample();
List<FacetResult> results1 = example.runFacetOnly();
System.out.println("Author: " + results1.get(0));
System.out.println("Publish Date: " + results1.get(1));
System.out.println("Facet counting example (combined facets and search):");
System.out.println("-----------------------");
List<FacetResult> results = example.runSearch();
System.out.println("Author: " + results.get(0));
System.out.println("Publish Date: " + results.get(1));
System.out.println("Facet drill-down example (Publish Date/2010):");
System.out.println("---------------------------------------------");
System.out.println("Author: " + example.runDrillDown());
System.out.println("Facet drill-sideways example (Publish Date/2010):");
System.out.println("---------------------------------------------");
for(FacetResult result : example.runDrillSideways()) {
System.out.println(result);
}
}
}
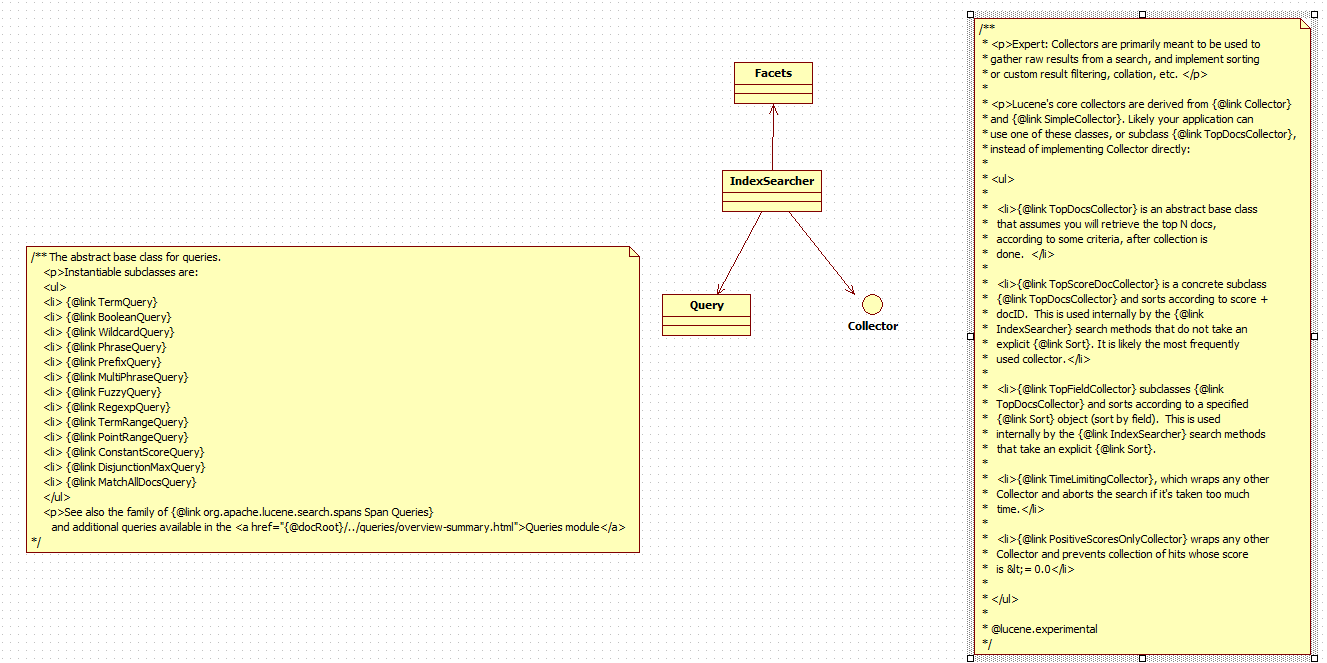
查询及其关系
查询
/** Lower-level search API.
*
* <p>{@link LeafCollector#collect(int)} is called for every matching document.
*
* @throws BooleanQuery.TooManyClauses If a query would exceed
* {@link BooleanQuery#getMaxClauseCount()} clauses.
*/
public void search(Query query, Collector results)
throws IOException {
query = rewrite(query);
search(leafContexts, createWeight(query, results.needsScores(), 1), results);
}
关系
lucene源码分析(3)facet实例的更多相关文章
- Lucene 源码分析之倒排索引(三)
上文找到了 collect(-) 方法,其形参就是匹配的文档 Id,根据代码上下文,其中 doc 是由 iterator.nextDoc() 获得的,那 DefaultBulkScorer.itera ...
- 一个lucene源码分析的博客
ITpub上的一个lucene源码分析的博客,写的比较全面:http://blog.itpub.net/28624388/cid-93356-list-1/
- Vue源码分析(二) : Vue实例挂载
Vue源码分析(二) : Vue实例挂载 author: @TiffanysBear 实例挂载主要是 $mount 方法的实现,在 src/platforms/web/entry-runtime-wi ...
- JVM源码分析-类加载场景实例分析
A类调用B类的静态方法,除了加载B类,但是B类的一个未被调用的方法间接使用到的C类却也被加载了,这个有意思的场景来自一个提问:方法中使用的类型为何在未调用时尝试加载?. 场景如下: public cl ...
- HashMap源码分析和应用实例的介绍
1.HashMap介绍 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.S ...
- Stack的源码分析和应用实例
1.Stack介绍 Stack是栈.它的特性是:先进后出(FILO:First In Last Out). java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实 ...
- lucene源码分析的一些资料
针对lucene6.1较新的分析:http://46aae4d1e2371e4aa769798941cef698.devproxy.yunshipei.com/conansonic/article/d ...
- lucene源码分析(1)基本要素
1.源码包 core: Lucene core library analyzers-common: Analyzers for indexing content in different langua ...
- mybatis源码分析(1)——SqlSessionFactory实例的产生过程
在使用mybatis框架时,第一步就需要产生SqlSessionFactory类的实例(相当于是产生连接池),通过调用SqlSessionFactoryBuilder类的实例的build方法来完成.下 ...
随机推荐
- unlimited channel buffer in Go
channel buffer可以事先分配大小,但是这些是需要占用内存的,事先分配几G内存给一个channel很浪费资源的,所以怎样创建一个无限的channel buffer呢?比较naive的写法就是 ...
- 如何将Jenkins multiline string parameter的多行文本优雅的保存为文件
[现象]: 使用multi-line string parameter获取的文本变量,在jenkins shell里面显示为单行文本(空格分割). [问题]:能否转换为多行文本,并存入文件. [解决方 ...
- 获取form表单元素值的4种方式
<html><head><title></title><script type="text/javascript"> f ...
- C++的访问关系
1.C++的访问关系
- 740. Delete and Earn
Given an array nums of integers, you can perform operations on the array. In each operation, you pic ...
- Segment Tree-732. My Calendar III
Implement a MyCalendarThree class to store your events. A new event can always be added. Your class ...
- poj1122
FDNY to the Rescue! Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 2917 Accepted: 89 ...
- 记录php漏洞--宇宙最强语言 PHP 爆出 DoS 漏洞,可以直接灌满 CPU
站长之家(Chinaz.com)5月20日消息 近日,PHP被爆出存在远程DOS漏洞,若黑客利用该漏洞构造PoC发起连接,容易导致目标主机CPU被迅速消耗.此漏洞涉及众多PHP版本,因而影响范围极大 ...
- vue学前班004(基础指令与使用技巧)
我学vue 的最终目的是为了 做apicloud 和vue 的开发 作为配合apicloud的前端框架使用 所以项目用不到的会暂时不介绍. (强烈建议 官网案例走一遍) 基础指令的学习(结合aui ...
- class字节码结构(三)(字段集合的结构)
<Java虚拟机原理图解>1.4 class文件中的字段表集合--field字段在class文件中是怎样组织的 字段区:包括了字段计数器和字段数据区: 字段是指在类中定义的静态或者非静态的 ...