xgboost与sklearn的接口
xgb使用sklearn接口(推荐)
XGBClassifier
from xgboost.sklearn import XGBClassifier
clf = XGBClassifier(
silent=0 ,#设置成1则没有运行信息输出,最好是设置为0.是否在运行升级时打印消息。
#nthread=4,# cpu 线程数 默认最大
learning_rate= 0.3, # 如同学习率
min_child_weight=1,
# 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言
#,假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
#这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
max_depth=6, # 构建树的深度,越大越容易过拟合
gamma=0, # 树的叶子节点上作进一步分区所需的最小损失减少,越大越保守,一般0.1、0.2这样子。
subsample=1, # 随机采样训练样本 训练实例的子采样比
max_delta_step=0,#最大增量步长,我们允许每个树的权重估计。
colsample_bytree=1, # 生成树时进行的列采样
reg_lambda=1, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
#reg_alpha=0, # L1 正则项参数
#scale_pos_weight=1, #如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛。平衡正负权重
#objective= 'multi:softmax', #多分类的问题 指定学习任务和相应的学习目标
#num_class=10, # 类别数,多分类与 multisoftmax 并用
n_estimators=100, #树的个数
seed=1000 #随机种子
#eval_metric= 'auc'
)
clf.fit(X_train,y_train,eval_metric='auc')
5.3 基于Scikit-learn接口的分类
# ==============基于Scikit-learn接口的分类================
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割 # 训练模型
model = xgb.XGBClassifier(max_depth=5, learning_rate=0.1, n_estimators=160, silent=True, objective='multi:softmax')
model.fit(X_train, y_train) # 对测试集进行预测
y_pred = model.predict(X_test) # 计算准确率
accuracy = accuracy_score(y_test,y_pred)
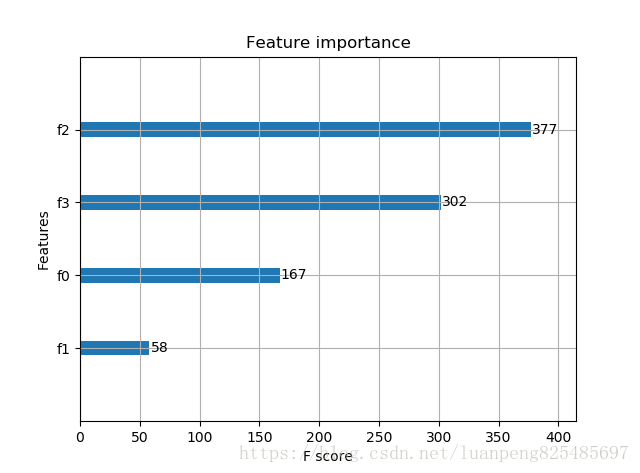
print("accuarcy: %.2f%%" % (accuracy*100.0)) # 显示重要特征
plot_importance(model)
plt.show()
输出结果:Accuracy: 96.67 %
基于Scikit-learn接口的回归
# ================基于Scikit-learn接口的回归================
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston boston = load_boston()
X,y = boston.data,boston.target # XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) model = xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=True, objective='reg:gamma')
model.fit(X_train, y_train) # 对测试集进行预测
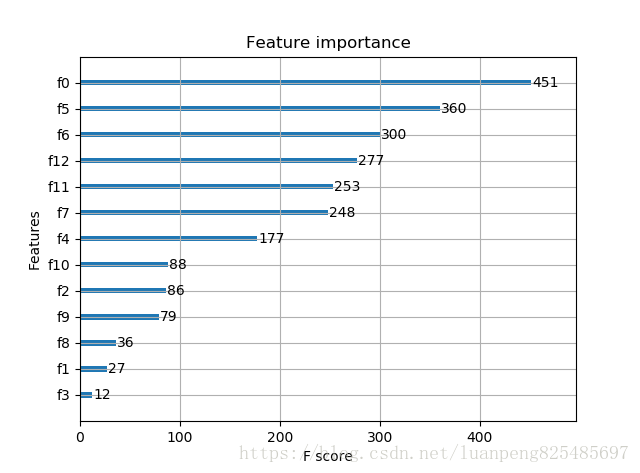
ans = model.predict(X_test) # 显示重要特征
plot_importance(model)
plt.show()
参数调优的一般方法
我们会使用和GBM中相似的方法。需要进行如下步骤:
1. 选择较高的学习速率(learning rate)。一般情况下,学习速率的值为0.1。但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动。选择对应于此学习速率的理想决策树数量。XGBoost有一个很有用的函数“cv”,这个函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。
2. 对于给定的学习速率和决策树数量,进行决策树特定参数调优(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在确定一棵树的过程中,我们可以选择不同的参数,待会儿我会举例说明。
3. xgboost的正则化参数的调优。(lambda, alpha)。这些参数可以降低模型的复杂度,从而提高模型的表现。
4. 降低学习速率,确定理想参数。
咱们一起详细地一步步进行这些操作。
第一步:确定学习速率和tree_based 参数调优的估计器数目。
为了确定boosting 参数,我们要先给其它参数一个初始值。咱们先按如下方法取值:
1、max_depth = 5 :这个参数的取值最好在3-10之间。我选的起始值为5,但是你也可以选择其它的值。起始值在4-6之间都是不错的选择。
2、min_child_weight = 1:在这里选了一个比较小的值,因为这是一个极不平衡的分类问题。因此,某些叶子节点下的值会比较小。
3、gamma = 0: 起始值也可以选其它比较小的值,在0.1到0.2之间就可以。这个参数后继也是要调整的。
4、subsample,colsample_bytree = 0.8: 这个是最常见的初始值了。典型值的范围在0.5-0.9之间。
5、scale_pos_weight = 1: 这个值是因为类别十分不平衡。
注意哦,上面这些参数的值只是一个初始的估计值,后继需要调优。这里把学习速率就设成默认的0.1。然后用xgboost中的cv函数来确定最佳的决策树数量。
第二步: max_depth 和 min_weight 参数调优
我们先对这两个参数调优,是因为它们对最终结果有很大的影响。首先,我们先大范围地粗调参数,然后再小范围地微调。
注意:在这一节我会进行高负荷的栅格搜索(grid search),这个过程大约需要15-30分钟甚至更久,具体取决于你系统的性能。你也可以根据自己系统的性能选择不同的值。
第三步:gamma参数调优
第四步:调整subsample 和 colsample_bytree 参数
第五步:正则化参数调优。
第6步:降低学习速率
最后,我们使用较低的学习速率,以及使用更多的决策树。我们可以用XGBoost中的CV函数来进行这一步工作。
xgboost与sklearn的接口的更多相关文章
- 【机器学习】集成学习之xgboost的sklearn版XGBClassifier使用教程
XGBClassifier是xgboost的sklearn版本.代码完整的展示了使用xgboost建立模型的过程,并比较xgboost和randomForest的性能. # -*- coding: u ...
- Xgboost的sklearn接口参数说明
from xgboost.sklearn import XGBClassifier model=XGBClassifier(base_score=0.5, booster='gbtree', cols ...
- xgboost的sklearn接口和原生接口参数详细说明及调参指点
from xgboost import XGBClassifier XGBClassifier(max_depth=3,learning_rate=0.1,n_estimators=100,silen ...
- xgboost 参数调优指南
一.XGBoost的优势 XGBoost算法可以给预测模型带来能力的提升.当我对它的表现有更多了解的时候,当我对它的高准确率背后的原理有更多了解的时候,我发现它具有很多优势: 1 正则化 标准GBDT ...
- Python机器学习笔记:XgBoost算法
前言 1,Xgboost简介 Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器.因为Xgboost是一种提升树模型,所以它是将许多 ...
- XGBoost类库使用小结
在XGBoost算法原理小结中,我们讨论了XGBoost的算法原理,这一片我们讨论如何使用XGBoost的Python类库,以及一些重要参数的意义和调参思路. 本文主要参考了XGBoost的Pytho ...
- Xgboost建模
xgboost参数 选择较高的学习速率(learning rate).一般情况下,学习速率的值为0.1.但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动.选择对应于此学习速率的理 ...
- XGBoost使用篇(未完成)
1.截止到本文(20191104)sklearn没有集成xgboost算法,需要单独安装xgboost库,然后导入使用 xgboost官网安装说明 Pre-built binary wheel for ...
- Boosting算法总结(ada boosting、GBDT、XGBoost)
把之前学习xgb过程中查找的资料整理分享出来,方便有需要的朋友查看,求大家点赞支持,哈哈哈 作者:tangg, qq:577305810 一.Boosting算法 boosting算法有许多种具体算法 ...
随机推荐
- Hadoop 2.6.0 HIVE 2.1.1配置
我用的hadoop 是2.6.0 版本 ,hive 是 2.1.1版本进入:/home/zkpk/apache-hive-2.1.1-bin/执行hive 后报错: (1)Exception in t ...
- C# 抽签小程序
设计背景 设置一个Excel名单表,对名单进行随机抽取. 设计思路 使用Timer定时器,运行定时器进行名单随机滚动,停止定时器获得抽签结果 相关技术 随机数 Excel读取/导出 XML文档读写 相 ...
- BZOJ5291 BJOI2018链上二次求和(线段树)
用线段树对每种长度的区间维护权值和. 考虑区间[l,r]+1对长度为k的区间的贡献,显然其为Σk-max(0,k-i)-max(0,k-(n-i+1)) (i=l~r). 大力展开讨论.首先变成Σk- ...
- http的无状态无连接
搞爬虫的核心:http协议. 在理解http中的无状态和无连接时,有一些困惑,下文可以解决. 转自:http://www.cnblogs.com/bellkosmos/p/5237146.html h ...
- 记一个鼠标略过时候的css动画
.circle{ width: 15px; height: 15px; background: rgba(0,0,0,0.7); border-radius: 50%; display: table- ...
- Timus 1005 解题报告
题目链接 http://acm.timus.ru/problem.aspx?space=1&num=1005 题目大意 给你一堆石头,现在需要你将这堆石头分成两堆,要求两堆石头的重量相差最小, ...
- maven管理工具
Maven解决的问题: 1. 使用maven前搭建项目需要引入各种jar包,并且还可能有jar包冲突的问题 解决jar包冲突的方式: 1. 第一声明优先原则 2. 路径近者优先原则. 直接依赖路径比传 ...
- loj2542「PKUWC2018」随机游走
题目描述 给定一棵 nn 个结点的树,你从点 xx 出发,每次等概率随机选择一条与所在点相邻的边走过去. 有 QQ 次询问,每次询问给定一个集合 SS,求如果从 xx 出发一直随机游走,直到点集 SS ...
- 【noip模拟】D(==)
Portal --> who knows == Description 数轴上面有一些洞,有一些老鼠,每个洞有一个容量限制,一只位于\(x\)的老鼠进到位于\(y\)的洞要花费\(|x-y|\) ...
- 在eclipse中安装 Activiti Designer插件
转: Activiti系列——如何在eclipse中安装 Activiti Designer插件 这两天在评估jbpm和Activiti,需要安装一个Activiti Designer插件试用一下. ...