配置好Nginx后,通过flume收集日志到hdfs(记得生成本地log时,不要生成一个文件,)
生成本地log最好生成多个文件放在一个文件夹里,特别多的时候一个小时一个文件
配置好Nginx后,通过flume收集日志到hdfs
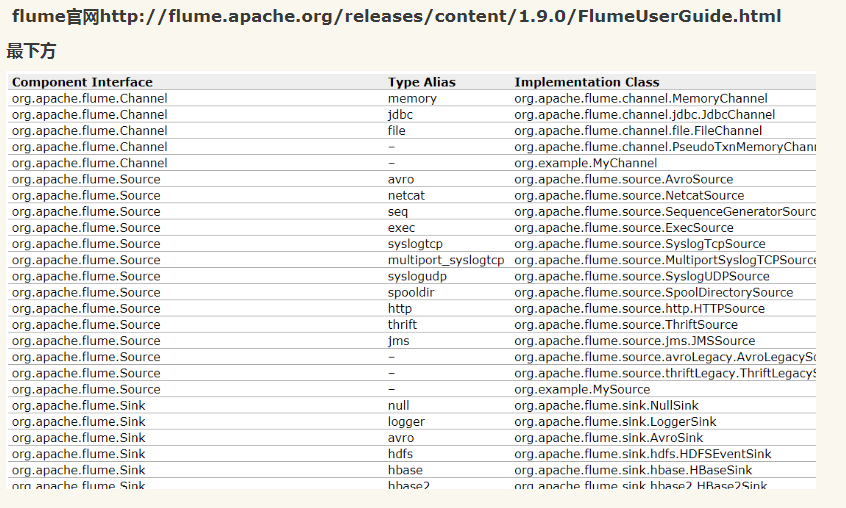
可参考flume的文件
执行的注意点




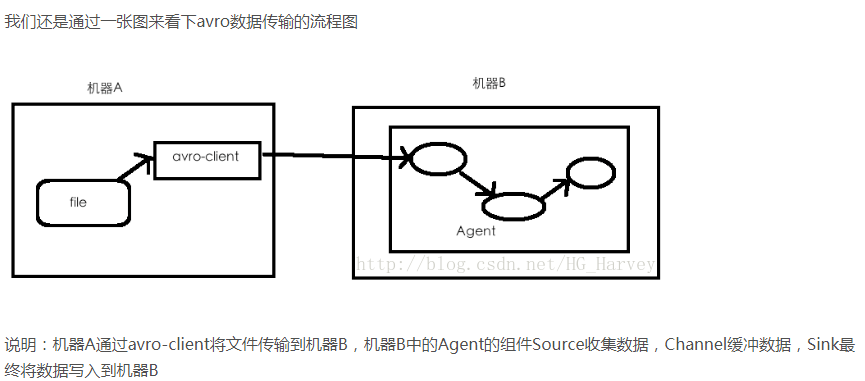
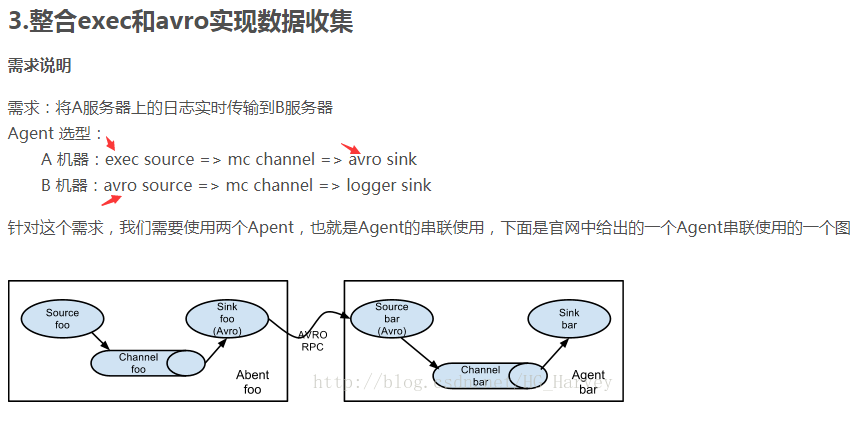
avro和exec联合用法
https://blog.csdn.net/HG_Harvey/article/details/78358304
exec实质是收集文件

spool用法
https://blog.csdn.net/a_drjiaoda/article/details/84954593


或者下面这个代码
名字为
conf/job/project/flume-hdfs.conf
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:9000/project/log/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 60000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.idleTimeout = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动hdfs的前提下
start-all.sh
执行
flume-ng agent --conf conf/ --name a1 --conf-file conf/job/project/flume-hdfs.conf
配置好Nginx后,通过flume收集日志到hdfs(记得生成本地log时,不要生成一个文件,)的更多相关文章
- flume收集日志直接sink到oracle数据库
因为项目需求,需要保存项目日志.项目的并发量不大,所以这里直接通过flume保存到oracle 源码地址:https://github.com/jaxlove/fks/tree/master/src/ ...
- 现象:当指定logback的FileNamePattern为日期2020-01-15后,如果有线程不断的往里写log,过了零点文件不会变成下一日2020-01-16,还是会在2020-01-15里继续写 结论:写log的线程不停,文件不会按日子更换。
logback版本:1.1.11 这个是我实验验证的,昨天我配置了一个logback,然后用两个线程不断往里写log,结果发现到了今天2020-01-16日,log文件还是昨天的logbackCfg. ...
- nginx日志切割并使用flume-ng收集日志
nginx的日志文件没有rotate功能.如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件.第一步就是重命名日志文件,不用担心重命名后nginx找不到日 ...
- EMQ配置通过nginx反向代理wss和ws
参考:https://www.cnblogs.com/succour/p/6305574.html EMQ官方文档:https://docs.emqx.io/broker/v3/cn/ 一,系统环境及 ...
- nginx 多域名配置 (nginx如何绑定多个域名)
nginx绑定多个域名可又把多个域名规则写一个配置文件里,也可又分别建立多个域名配置文件,我一般为了管理方便,每个域名建一个文件,有些同类域名也可又写在一个总的配置文件里. 一.每个域名一个 ...
- Nginx+Flume+Hadoop日志分析,Ngram+AutoComplete
配置Nginx yum install nginx (在host99和host101) service nginx start开启服务 ps -ef |grep nginx看一下进程 ps -ef | ...
- ELK安装配置及nginx日志分析
一.ELK简介1.组成ELK是Elasticsearch.Logstash.Kibana三个开源软件的组合.在实时数据检索和分析场合,三者通常是配合使用,而且又都先后归于 Elastic.co 公司名 ...
- Flume分布式日志收集系统
1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去.2.flume里面有个核心概念,叫做agent.agent是一个java进程,运行在日志收集节点.通过agent接收日志,然后暂存起 ...
- 基于Flume的日志收集系统方案参考
前言 本文将简单介绍两种基于Flume的日志收集系统可能的架构方案,可根据不同的实际场景参考使用. 方案一 示例图如下: 说明: 每个日志源(http上报.日志文件等)对应一个Agent-c用于收集对 ...
随机推荐
- sql计算总页数
1 计算总页数方法: public int getTotalCount() { Statement stmt = null; //提交SQL语句对象stmt Resu ...
- etcd 集群恢复
七个节点,挂了5个,etcd无法访问 参考: https://coreos.com/etcd/docs/latest/op-guide/recovery.html 此次我只恢复了v3的数据 在存活的节 ...
- windows服务启动的进程无窗口
勾选允许服务与桌面交互 指服务是否在桌面上提供用户界面,当服务启动后不论是谁登录都能使用.只有作为 LocalSystem 帐户(由“此帐户”指定)运行时,该选项才能使用. 如果一个服务需要界面(比如 ...
- ubuntu下搭建testlink
环境配置: 1. 安装mysql 教程网上找 2. 安装apache sudo apt-get install apache2 重启apache服务 sudo /etc/init.d/apache2 ...
- CloseableHttpClient(二)
package com.cmy.httpClient; import java.io.IOException; import org.apache.http.HttpEntity; import or ...
- python之字符串【str】
#Auther Bob#--*--conding:utf-8 --*-- #定义一个str的对象,有下面两种方法name = 'Bob abc'job = str('it')print(type(na ...
- 硬盘的 read0 read 1
Read 0:组建的时候必须2块容量相同的硬盘,每个程序的数据以一定的大小分别写在两个硬盘里,读的时候从两个硬盘里一起读,这种阵列方式理论上硬盘的读写速度是一块硬盘的2倍,实际应用中大约速度比一块硬盘 ...
- 9-sort使用时的错误
/* 矩形嵌套 题目内容: 有n个矩形,每个矩形可以用a,b来描述,表示长和宽.矩形X(a,b)可以嵌套在矩形 ...
- php iframe 上传文件
我们通过动态的创建iframe,修改form的target,来实现无跳转的文件上传. 具体的实现步骤 1.捕捉表单提交事件 2.创建一个iframe 3.修改表单的target,指向iframe ...
- vi编辑时出现E325:ATTENTION
我们用vi编辑文件时,系统会提示E325:ATTENTION. 这是由于在编辑该文件的时候异常退出了,因为vi在编辑文件时会创建一个交换文件swap file以保证文件的安全性. 但是每次打开文件时都 ...