oracle进阶之分析函数
本博客是自己在学习和工作途中的积累与总结,纯属经验之谈,仅供自己参考,也欢迎大家转载,转载时请注明出处。
http://www.cnblogs.com/king-xg/p/6797119.html
分析函数提供了跨行,多层级聚合引用值的能力,并且可以在数据子集中空值排序粒度。与分组函数不同的是,分析函数并不将结果集聚合为较少的行。
而且分析函数的查询速度比传统sql查询会快很多。
使用分析函数可以在不适用任何自连接的情况下得到一行中聚合和未聚合的值。
示例数据:
-- 创建销售表
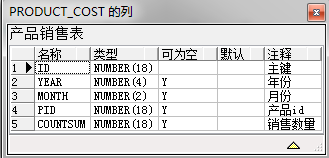
create table product_cost(
id number(18) primary key,
year number(4),
month number(2),
pid number(18),
countSum number(18)
); -- 创建产品表
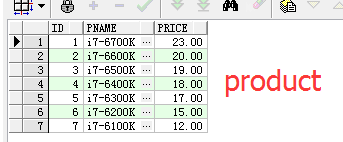
create table product(
id number(18) primary key,
pname varchar(100),
price number(8,2)
); -- 初始化产品表记录
insert into product (pname,price) values('i7-6700K','');
insert into product (pname,price) values('i7-6600K','');
insert into product (pname,price) values('i7-6500K','');
insert into product (pname,price) values('i7-6400K','');
insert into product (pname,price) values('i7-6300K','');
insert into product (pname,price) values('i7-6200K','');
insert into product (pname,price) values('i7-6100K',''); -- 初始化销售表记录
insert into product_cost(year,month,pid,countSum) values(2000,1,1,500);
insert into product_cost(year,month,pid,countSum) values(2000,1,2,630);
insert into product_cost(year,month,pid,countSum) values(2000,1,3,1200);
insert into product_cost(year,month,pid,countSum) values(2000,1,4,320);
insert into product_cost(year,month,pid,countSum) values(2000,1,5,250);
insert into product_cost(year,month,pid,countSum) values(2000,1,6,250);
insert into product_cost(year,month,pid,countSum) values(2000,1,7,350); insert into product_cost(year,month,pid,countSum) values(2000,2,1,1500);
insert into product_cost(year,month,pid,countSum) values(2000,2,2,1630);
insert into product_cost(year,month,pid,countSum) values(2000,2,3,200);
insert into product_cost(year,month,pid,countSum) values(2000,2,4,1320);
insert into product_cost(year,month,pid,countSum) values(2000,2,5,250);
insert into product_cost(year,month,pid,countSum) values(2000,2,6,350);
insert into product_cost(year,month,pid,countSum) values(2000,2,7,520); insert into product_cost(year,month,pid,countSum) values(2000,3,1,520);
insert into product_cost(year,month,pid,countSum) values(2000,3,2,660);
insert into product_cost(year,month,pid,countSum) values(2000,3,3,1900);
insert into product_cost(year,month,pid,countSum) values(2000,3,4,300);
insert into product_cost(year,month,pid,countSum) values(2000,3,5,210);
insert into product_cost(year,month,pid,countSum) values(2000,3,6,210);
insert into product_cost(year,month,pid,countSum) values(2000,3,7,320); insert into product_cost(year,month,pid,countSum) values(2000,4,1,1520);
insert into product_cost(year,month,pid,countSum) values(2000,4,2,1660);
insert into product_cost(year,month,pid,countSum) values(2000,4,3,2900);
insert into product_cost(year,month,pid,countSum) values(2000,4,4,1200);
insert into product_cost(year,month,pid,countSum) values(2000,4,5,980);
insert into product_cost(year,month,pid,countSum) values(2000,4,6,910);
insert into product_cost(year,month,pid,countSum) values(2000,4,7,620); insert into product_cost(year,month,pid,countSum) values(2001,1,1,500);
insert into product_cost(year,month,pid,countSum) values(2001,1,2,630);
insert into product_cost(year,month,pid,countSum) values(2001,1,3,1200);
insert into product_cost(year,month,pid,countSum) values(2001,1,4,320);
insert into product_cost(year,month,pid,countSum) values(2001,1,5,150);
insert into product_cost(year,month,pid,countSum) values(2001,1,6,250);
insert into product_cost(year,month,pid,countSum) values(2001,1,7,350); insert into product_cost(year,month,pid,countSum) values(2001,2,1,1500);
insert into product_cost(year,month,pid,countSum) values(2001,2,2,1630);
insert into product_cost(year,month,pid,countSum) values(2001,2,3,200);
insert into product_cost(year,month,pid,countSum) values(2001,2,4,1320);
insert into product_cost(year,month,pid,countSum) values(2001,2,5,250);
insert into product_cost(year,month,pid,countSum) values(2001,2,6,350);
insert into product_cost(year,month,pid,countSum) values(2001,2,7,450); insert into product_cost(year,month,pid,countSum) values(2001,3,1,520);
insert into product_cost(year,month,pid,countSum) values(2001,3,2,660);
insert into product_cost(year,month,pid,countSum) values(2001,3,3,1900);
insert into product_cost(year,month,pid,countSum) values(2001,3,4,300);
insert into product_cost(year,month,pid,countSum) values(2001,3,5,180);
insert into product_cost(year,month,pid,countSum) values(2001,3,6,210);
insert into product_cost(year,month,pid,countSum) values(2001,3,7,320); insert into product_cost(year,month,pid,countSum) values(2001,4,1,1520);
insert into product_cost(year,month,pid,countSum) values(2001,4,2,1660);
insert into product_cost(year,month,pid,countSum) values(2001,4,3,2900);
insert into product_cost(year,month,pid,countSum) values(2001,4,4,1200);
insert into product_cost(year,month,pid,countSum) values(2001,4,5,980);
insert into product_cost(year,month,pid,countSum) values(2001,4,6,910);
insert into product_cost(year,month,pid,countSum) values(2001,4,7,620);
数据展示:


-- 常用分析函数列表 . leg -- 访问一个分区或结果集中的前一行
. lead -- 访问一个分区或结果集中的后一行
. first_value -- 访问一个分区或结果集中的第一行
. last_value -- 访问一个分区或结果集中的最后一行
. nth_value -- 访问一个分区或结果集的指定行
. rank -- 将数据行值按照排序后的顺序进行排名,在有并列的情况下排名值将被跳过
. dense_rank -- 将数据行值按照排序后的顺序进行排名,在有并列的情况下也不会跳过排名
. row_number -- 对行进行排序,并为每一行赋予一个随机且唯一的编号
. ratio_to_report -- 计算报告中值的比例
. percent_rank -- 将计算得到的排名标准化为0到1之间的值
. ntile -- 对每一个分区进行再分组,并为每一个分组提供一个唯一标识(仅在本分区中唯一),每组的数据行数为指定值,但每组之间最多相差一个数据行
. listagg -- 将来自不同行的列值转化为列表格式
分析函数的组成:
(1) 指定列或范围 解释: 分析函数一般带两个括号,第一个就是指定该函数所作用的列
(2) 分组 解释: 1. 将数据分区,关键字 partition by,有点像group by,但却有很大不同,group by分组后的列只存在唯一值,不存在等同的值(就像是将数据分类,只显示类型名称一样),而partition by 是将数据原封不动根据后面给的字段进行划分边界形成分区(即每个分区都存在边界)
2. group by 针对整个表或数据集,partition by 针对于每一行的记录
(3) 排序 解释: order by就是排序
(4) 窗口控制 解释: 1.控制边界的范围,默认是 rows between unbounded preceding and current row(起始边界到当前行),rows between unbounded preceding and unbounded following(整个分区),以及自定义的边界范围 rows between [number] preceding and [number] following(起始边界是该行的前xx行结束边界是该行的后xx行)
2.在没有分区的情况的,窗口控制会在一定程度上起到分区作用
举例:
1. (leg函数) 查询每一个产品的月销售总额与前一个月的对比
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(pc.countsum*p.price) as currentAmt,lag(pc.countsum*p.price,,pc.countsum*p.price) over(partition by year,pc.pid order by year,month,pid) as beforeAmt
from product_cost pc
left join product p on p.id=pc.pid
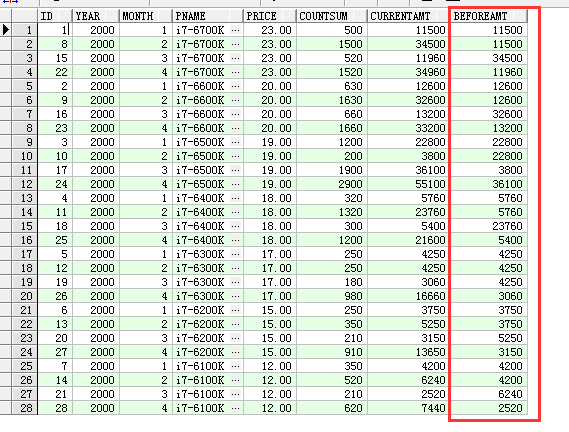
注意: leg分析函数中的字段区域,不能用别名(不能写"currentAmt"只能写"pc.countsum*p.price"),会报标识符无效的异常,除非用子查询,就能用别名,原因:select 同一层级,解析在同一时间,oracle是认识别名标注的字段,除非在解析分析函数之前,即子查询
2. (lead函数),同上就是查询的方向由向上查询改成向下查询而已。
3. (first_value函数) 统计每个月月销量第一的产品
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(p.price*pc.countsum) as currentAmt,first_value(p.price*pc.countsum) over(partition by year,month order by year,month,p.price*pc.countsum DESC) as sum
from product_cost pc
left join product p on pc.pid=p.id
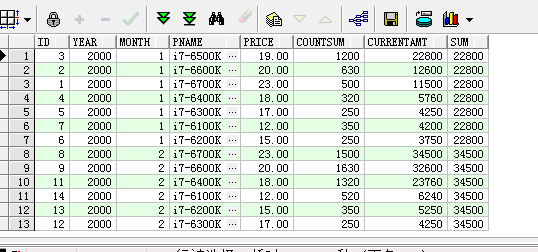
聚合函数也可以应用到里面,上面的sql可以换成下面的
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(p.price*pc.countsum) as currentAmt,max(p.price*pc.countsum) over(partition by year,month order by year,month,p.price*pc.countsum DESC) as sum
from product_cost pc
left join product p on pc.pid=p.id
4. last_value函数,同上,查询分区中排序或不排序的最后一条记录
5. nth_value函数,查询指定行的记录,比如: 计算当月销量第二名的产品销量总额
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,(p.price*pc.countsum) as currentAmt,nth_value(p.price*pc.countsum,) over(partition by year,month order by year,month,p.price*pc.countsum DESC rows between unbounded preceding and unbounded following) as sum
from product_cost pc
left join product p on pc.pid=p.id

6. rank函数,排名函数之一,特点:同名(排名)跳排,排名依据为order by 后的字段值,例子:对每个月的产品进行排名,依据月销量进行排名
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,rank() over(partition by year,month order by pc.countsum DESC) as orderName
from product_cost pc
left join product p on pc.pid=p.id
7. dense_rank函数,排名函数之一,特点:同名不跳排,排名依据order by后的字段值,例子:对每个月的产品进行排名,依据月销量进行排名
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,dense_rank() over(partition by year,month order by pc.countsum DESC) as orderName
from product_cost pc
left join product p on pc.pid=p.id
小结: rank函数和dense_rank函数的相同点,排序的字段值相同,则排名相同,唯一不同点就是rank会跳排,根据相同值的数量而定,跳排数为相等值的数量-1,dense_rank函数不跳排,无论存在多少相等的值
8. row_number函数,为数据行分配一个唯一标识,举例:
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,row_number() over(partition by year,month order by pc.countsum DESC) as orderName
from product_cost pc
left join product p on pc.pid=p.id
9. ratio_to_report函数,计算值在该分区或整个表或数据集中所占比例
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,trunc(*ratio_to_report(p.price*pc.countsum) over(partition by year,month),)||'%' as proportion
from product_cost pc
left join product p on pc.pid=p.id
order by year,month,p.price*pc.countsum DESC

注意: 在ratio_to_report函数中,不能使用排序,只能在外层使用order by
10. percent_rank函数,计算得到的排名,且排名值为0-1之间的数(排名值越低,排名越高)
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,percent_rank() over(partition by year,month order by countsum DESC) as proportion
from product_cost pc
left join product p on pc.pid=p.id
11. ntile函数,特点:方便将有问题的数据放到一个统一的容器中,举例:领导发话说客户不想看到这些销量低于300的数据记录
select pc.id as id, pc.year as year,pc.month as month,p.pname as pname,p.price as price,pc.countsum as countSum,ntile() over(partition by year,month order by countsum DESC) as proportion
from product_cost pc
left join product p on pc.pid=p.id

12. listagg函数拥有将列值转化成列表格的能力
select listagg(p.pname,',') within group (order by p.id) as str
from product p

// 结果: i7-6700K,i7-6600K,i7-6500K,i7-6400K,i7-6300K,i7-6200K,i7-6100K
顺便小结一下,字符串的拼接方法:
(1). 自定义函数拼接字符串
(2). "||" 符合进行拼接
(3). wmsys.wm_concat函数拼接字符串
(4). listagg函数拼接字符串
oracle进阶之分析函数的更多相关文章
- 利用Oracle内置分析函数进行高效统计汇总
分析函数是Oracle从8.1.6开始引入的一个新的概念,为我们分析数据提供了一种简单高效的处理方式.在分析函数出现以前,我们必须使用自联查询,子查询或者内联视图,甚至复杂的存储过程实现的语句,现 ...
- Oracle 中的分析函数
Oracle常用分析函数介绍(排名函数+窗口函数) 2014年11月30日 ⁄ 数据库 ⁄ 共 3903字 ⁄ 暂无评论 ⁄ 阅读 7,772 次 评级函数 常见评级函数如下: RANK():返回数据 ...
- 【Oracle】oracle之listagg分析函数
oracle分析函数——listagg篇 (1)使用listagg将多行数据合并到一行 例表: select deptno, ename from emp order by deptno, ename ...
- oracle累积求和分析函数sum over的使用
oracle sum()over函数的使用 over不能单独使用,要和分析函数:rank(),dense_rank(),row_number()等一起使用. over函数的参数:over(partit ...
- Oracle进阶研究问题收集
1. buffer busy waits http://www.itpub.net/thread-1801066-1-4.html 2. 深入理解oracle log buffer http://ww ...
- 求学生单科流水表中单科最近/最新的考试成绩表的新增可行性方案 使用Oracle提供的分析函数rank
在 https://www.cnblogs.com/xiandedanteng/p/12327809.html 一文中,提到了三种求学生单科最新成绩的SQL可行性方案,这里还有另一种实现,那就是利用分 ...
- oracle进阶之connect by笔记
本博客是自己在学习和工作途中的积累与总结,仅供自己参考,也欢迎大家转载,转载时请注明出处. http://www.cnblogs.com/king-xg/p/6794562.html 如果觉得对您有帮 ...
- oracle 进阶之model子句
本博客是自己在学习和工作途中的积累与总结,仅供自己参考,也欢迎大家转载,转载时请注明出处. http://www.cnblogs.com/king-xg/p/6692841.html 一, mode ...
- Oracle row_number() over() 分析函数--取出最新数据
语法格式:row_number() over(partition by 分组列 order by 排序列 desc) 一个很简单的例子 1,先做好准备 create table test1( id v ...
随机推荐
- Chapter 5 软件工程中的形式化方法
从广义上讲,形式化方法是指将离散数学的方法用于解决软件工程领域的问题,主要包括建立精确的数学模型以及对模型的分析活动.狭义的讲,形式化方法是运用形式化语言,进行形式化的规格描述.模型推理和验证的方法. ...
- 进阶系列(4)—— C#文件与流
一. 驱动器 在Windows操作系统中,存储介质统称为驱动器,硬盘由于可以划分为多个区域,每一个区域称为一个驱动器..NET Framew ork提供DriveInfo类和 DriveType枚 ...
- C语言:一个能自动生成小学四则运算题目的程序
完成这个程序,半个小时内完成了,这个程序,可以自动生成小学简易的四则运算,提供菜单让用户选择,然后判断加减乘除,判断答对答错的题目个数,用户同时也可以重新选择继续答题或重新选择或退出程序. 源程序: ...
- java编程的一些注意事项
下面是参考网络资源和总结一些在java编程中尽可能做到的一些地方 1.尽量在合适的场合使用单例 使用单例可以减轻加载的负担,缩短加载的时间,提高加载的效率,但并不是所有地方都适用于单例,简单来说,单例 ...
- APP分析----饿了么
产品 饿了么 选择原因:有了外卖就可以轻松拥有一个不用出门也饿不着的爽歪歪周末. 第一部分 调研, 评测 下载软件并使用起来,描述最简单直观的个人第一次上手体验. 主界面: 第一次上手是大一 ...
- 通过cmd命令安装、卸载、启动和停止Windows Service(InstallUtil.exe)
步骤: 1.运行--〉cmd:打开cmd命令框 2.在命令行里定位到InstallUtil.exe所在的位置 InstallUtil.exe 默认的安装位置是在C:/Windows/Microsoft ...
- Windows 10 正式版原版ISO镜像
Win10正式版32位简体中文版(含家庭版.专业版)文件名: cn_windows_10_multiple_editions_x86_dvd_6846431.isoSHA1:21B824F402927 ...
- vue 组件 模板input双向数据数据
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>T ...
- 01.基于IDEA+Spring+Maven搭建测试项目--综述
目前公司的测试工作中常见两种接口:HTTP和Dubbo,这两种接口类型均可以使用相关测试工具进行测试,但都会有一定的局限性和不便之处,具体如下: 1.HTTP接口,当需要对于参数进行加密解密时,就得对 ...
- Day 5 笔记 dp动态规划
Day 5 笔记 dp动态规划 一.动态规划的基本思路 就是用一些子状态来算出全局状态. 特点: 无后效性--狗熊掰棒子,所以滚动什么的最好了 可以分解性--每个大的状态可以分解成较小的步骤完成 dp ...