20169211《Linux内核原理与分析》 第十周作业
一、Linux内核之进程地址空间学习总结
Linux内核除了要管理物理内存还需要管理虚拟内存。用户进程的地址空间就是虚拟内存的一部分。每个用户进程都独有一个地址空间。由于是虚拟化的内存,所以从每个进程的角度来看似乎它可以访问所有的物理内存,实际上是不可以的。
进程的地址空间由进程可寻址的虚拟内存和进程被允许使用的虚拟内存里的地址组成。每个进程被分配一大块32位或64位的地址空间(有些系统的地址空间是由几个分离的小块组成的,不怎么常用),具体大小由系统的结果决定。正常来说那块地址空间是进程独用的。两进程之间的地址空间相互之间没有任何联系,所以两进程可以在各自的地址空间里相同的地址有不同的数据。当然进程也可以设置和其他进程共享地址空间,这些进程就变成了线程。
尽管一个进程可以寻址4GB的内存(对于32位的地址空间),他并不能访问所有的地址。进程只有权限访问某一段空间。这段空间叫做进程的内存区域。通过内核进程可以动态增加和删除内存区域。进程只能访问合法内存区域里面的内存地址。内存区域有可写,可读和可执行等属性。访问内存区域之外的地址或超出权限范围操作合法地址,都会导致进程被内核终止。
内存区域大致包括:
可执行文件的代码存在内存里面的区域,叫做文本区(text section).
可执行文件的初始化全局变量区域,叫做数据区(data section).
未初始化的全局变量区域,叫做bss section.
进程用户空间的堆栈区域
共享库的text, data,和bss区域
任何内存映射的文件
任何共享内存块
二、Linux内核之页高速缓存学习总结
1、页高速缓存概述
1.1 页高速缓存是Linux内核所使用的主要磁盘高速缓存。
1.2 页高速缓存中可能包含的内容:
(1)含有普通文件数据的页;
(2)含有目录的页;
(3)含有直接从块设备文件读出的数据的页;
(4)含有用户态进程数据的页;
(5)属于特殊文件系统文件的页。
注:内核的代码和内核数据不必从磁盘读也不必写入磁盘,因此页高速缓存中不可能有。
2、页高速缓存的组织
(1)页高速缓存的核心数据结构是address_space对象,它是一个嵌入在页所有者的索引节点对象中的数据结构。页描述符的struct address_space* mapping 字段指向address_space,unsigned long index 标志存放所有者的磁盘映像中页中数据的位置。
(2).如果页属于一个文件,那么页的所有者就是文件的索引节点,而且相应的address_space对象存放在VFS索引节点对象的i_data字段中。索引节点的i_mapping 字段指向同一个索引节点的i_data字段,而address_space对象的host字段也指向这个索引节点。
(3).address_space对象的关键字段是a_ops,它指向一个类型为address_space_operations的表,表中定义了对所有者的页进行各种操作的方法。
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
unsigned int i_mmap_writable;/* count VM_SHARED mappings */
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */
spinlock_t i_mmap_lock; /* protect tree, count, list */
unsigned int truncate_count; /* Cover race condition with truncate */
unsigned long nrpages; /* number of total pages */
pgoff_t writeback_index;/* writeback starts here */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
struct backing_dev_info *backing_dev_info; /* device readahead, etc */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
struct address_space *assoc_mapping; /* ditto */
} __attribute__((aligned(sizeof(long)))
(4)每个address_space对象对应一颗搜索树,address_space对象的page_tree字段是基树(radix tree)的根,它指向所有者的页描述符的指针。
3、页高速缓存的处理函数
3.1 查找页:
(1)find_get_page()//以指向address_space对象的指针和偏移量为参数,返回改页的地址或NULL
(2)find_lock_page()//与上类似,只是可以让调用者互斥的访问返回的页。
3.2 增加页:add_to_page_cache()//把一个新页的描述符插入到页高速缓存。
参数:页描述符的地址page,
address_space对象的地址mapping,表示地址空间内页索引值的offset,为基树分配新节点时所使用的内存分配标志gfp_mask。
3.3 删除页:remove_from_page_cache()
3.4 更新页:read_cache_page()。
4、把块放在页高速缓存中
4.1 VFS和各种文件系统以叫做块的逻辑单位组织磁盘数据。所以一个页中存放有几个块,那么如何找到页中相应的块呢?每个块缓冲区都有buffer_head类型的缓冲去首部描述符,该描述符包含内核必须了解的有关如何处理块的所有信息。
4.2 缓冲区首部的管理
一个页包含多个块缓冲,每个块缓冲都有缓存器首部管理,而每个页描述符中包含多个缓冲区首部。这样就完成块缓冲区的管理。
三、实验总结
任务切换:
Linux任务切换是通过switch_to实现的。switch_to本身是一个宏,通过利用长跳指令,当长跳指令的操作数是TSS描述符的时候,就会引起CPU的任务的切换,此时,cpu将所有寄存器的状态保存到当前任务寄存器TR所指向的TSS段(当前任务的任务状态段)中,然后利用长跳指令的操作数(TSS描述符)找到新任务的TSS段,然后将其中的内容填写到各个寄存器中,最后,将新任务的TSS选择符更新到TR中。这样系统就正式开始运行新切换的任务了。
Linux系统中,一个进程的一般执行过程:
1)正在运行的用户态进程X
2)发生中断int 0x80
3)SAVE_ALL //保存现场
4)中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
5)标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
6)restore_all //恢复现场
7)iret
8)继续运行用户态进程Y
特殊情况:
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
1)内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
2)创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
3)加载一个新的可执行程序后返回到用户态的情况,如execve。
实验操作:
跟踪schedule函数来仔细分析系统进行进程调度和进程切换的过程。
运行MenuOS,设置3个断点:schedule、context_switch、switch_to。
运行到第一个断点处停止了,即schedule函数处停止,使用list命令查看其代码,s命令逐条分析。在这个过程中,我们要留心一下其中的执行轨迹,一会儿要分析。


继续运行,到第二个断点处停止了,即context_switch处停下。与上相同,继续单步执行。在这个过程中,要留心一下switch_to。

context_switch中调用了switch_to函数,这个switch_to的宏定义,我们是可以利用单步执行进入其内部观察的。
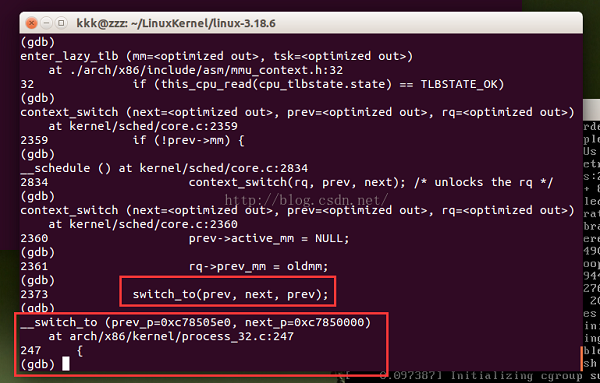
总结:
switch_to从A进程切换到B进程的步骤如下:
step1:复制两个变量到寄存器
[prev]"a" (prev)
[next]"d" (next)
即
eax <== prev_A
edx <== next_A
step2:保存进程A的ebp和eflags
pushfl /*将状态寄存器eflags压栈*/
pushl %ebp
注意,因为现在esp还在A的堆栈中,所以它们是被保存到A进程的内核堆栈中。
step3:保存当前esp到A进程内核描述符中:
movl%%esp, %[prev_sp]\n\t
即prev_A->thread.sp<== esp_A
在调用switch_to时,prev是指向A进程自己的进程描述符的。
step4:从next(进程B)的描述符中取出之前从B切换出去时保存的esp_B。
movl %[next_sp], %%esp\n\t
即esp_B <==next_A->thread.sp
注意,在A进程中的next是指向B的进程描述符的。从这个时候开始,CPU当前执行的进程已经是B进程了,因为esp已经指向B的内核堆栈。但是,现在的ebp仍然指向A进程的内核堆栈,所以所有局部变量仍然是A中的局部变量,比如next实质上是%n(%ebp_A),也就是next_A,即指向B的进程描述符。
step5:把标号为1的指令地址保存到A进程描述符的ip域:
movl $1f, %[prev_ip]\n\t
即prev_A->thread.ip<== %1f
当A进程下次从switch_to回来时,会从这条指令开始执行。具体方法要看后面被切换回来的B的下一条指令。
step6:将返回地址保存到堆栈,然后调用switch_to()函数,switch_to()函数完成硬件上下文切换。
pushl %[next_ip]\n\t
jmp switch_to\n
注意,如果之前B也被switch_to出去过,那么[next_ip]里存的就是下面这个1f的标号,但如果进程B刚刚被创建,之前没有被switch_to出去过,那么[next_ip]里存的将是ret_ftom_fork(参看copy_thread()函数)。
当这里switch_to()返回时,将返回值prev_A又写入了%eax,这就使得在switch_to宏里面eax寄存器始终保存的是prev_A的内容,或者,更准确的说,是指向A进程描述符的“指针”。
step7:从switch_to()返回后继续从1:标号后面开始执行,修改ebp到B的内核堆栈,恢复B的eflags:
popl %%ebp\n\t
popfl\n
如果从switch_to()返回后从这里继续运行,那么说明在此之前B肯定被switch_to调出过,因此此前肯定备份了ebp_B和flags_B,这里执行恢复操作。
此时ebp已经指向了B的内核堆栈,所以上面的prev,next等局部变量已经不是A进程堆栈中的了,而是B进程堆栈中的(B上次被切换出去之前也有这两个变量,所以代表着B堆栈中prev、next的值了),因为prev==%p(%ebp_B),而在B上次被切换出去之前,该位置保存的是B进程的描述符地址。如果这个时候就结束switch_to的话,在后面的代码中(即context_switch()函数中switch_to之后的代码)的prev变量是指向B进程的,因此,进程B就不知道是从哪个进程切换回来。而从context_switch()中switch_to之后的代码中,我们看到finish_task_switch(this_rq(),prev)中需要知道之前是从哪个进程切换过来的,因此,我们必须想办法保存A进程的描述符到B的堆栈中,这就是last的作用。
step8:将eax写入last,以在B的堆栈中保存正确的prev信息。
"=a"(last)
即last_B <== %eax
而从context_switch()中看到的调用switch_to的方法是:switch_to(prev,next, prev);
所以,这里面的last实质上就是prev,因此在switch_to宏执行完之后,prev_B就是正确的A的进程描述符了。这里,last的作用相当于把进程A堆栈中的A进程描述符地址复制到了进程B的堆栈中。
至此,switch_to已经执行完成,A停止运行,而开始执行B。此后,可能在某一次调度中,进程A得到调度,就会出现switch_to(C,A)这样的调用,这时,A再次得到调度,得到调度后,A进程从context_switch()中switch_to后面的代码开始执行,这时候,它看到的prev_A将指向C的进程描述符。
通过本次课程的学习,对进程调度时机及进程调度与进程切换的过程有了一定的认识。进程调度的时机:中断处理过程中,直接调用schedule,或者返回用户态时根据need_resched标记调用schedule;内核线程可以直接调用schedule进行进程切换,也可以在中断处理过程中进行调度,即内核线程作为一类特殊的进程可以主动调度,也可别动调度;用户态进程无法实现主动调度,只能在中断处理过程中进行调度。进程切换:schedule函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文的切换。
20169211《Linux内核原理与分析》 第十周作业的更多相关文章
- 20169212《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 这一周学习了MOOCLinux内核分析的第一讲,计算机是如何工作的?由于本科对相关知识的不熟悉,所以感觉有的知识理解起来了有一定的难度,不过多查查资 ...
- 20169210《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 本周作业分为两部分:第一部分为观看学习视频并完成实验楼实验一:第二部分为看<Linux内核设计与实现>1.2.18章并安装配置内核. 第 ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第九周作业
2018-2019-1 20189221 <Linux内核原理与分析>第九周作业 实验八 理理解进程调度时机跟踪分析进程调度与进程切换的过程 进程调度 进度调度时机: 1.中断处理过程(包 ...
- 2017-2018-1 20179215《Linux内核原理与分析》第二周作业
20179215<Linux内核原理与分析>第二周作业 这一周主要了解了计算机是如何工作的,包括现在存储程序计算机的工作模型.X86汇编指令包括几种内存地址的寻址方式和push.pop.c ...
- 2019-2020-1 20199329《Linux内核原理与分析》第九周作业
<Linux内核原理与分析>第九周作业 一.本周内容概述: 阐释linux操作系统的整体构架 理解linux系统的一般执行过程和进程调度的时机 理解linux系统的中断和进程上下文切换 二 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第二周作业
<Linux内核原理与分析>第二周作业 一.上周问题总结: 未能及时整理笔记 Linux还需要多用 markdown格式不熟练 发布博客时间超过规定期限 二.本周学习内容: <庖丁解 ...
- 2019-2020-1 20209313《Linux内核原理与分析》第二周作业
2019-2020-1 20209313<Linux内核原理与分析>第二周作业 零.总结 阐明自己对"计算机是如何工作的"理解. 一.myod 步骤 复习c文件处理内容 ...
- 2018-2019-1 20189221《Linux内核原理与分析》第一周作业
Linux内核原理与分析 - 第一周作业 实验1 Linux系统简介 Linux历史 1991 年 10 月,Linus Torvalds想在自己的电脑上运行UNIX,可是 UNIX 的商业版本非常昂 ...
- 《Linux内核原理与分析》第一周作业 20189210
实验一 Linux系统简介 这一节主要学习了Linux的历史,Linux有关的重要人物以及学习Linux的方法,Linux和Windows的区别.其中学到了LInux中的应用程序大都为开源自由的软件, ...
- 2018-2019-1 20189221《Linux内核原理与分析》第二周作业
读书报告 <庖丁解牛Linux内核分析> 第 1 章 计算工作原理 1.1 存储程序计算机工作模型 1.2 x86-32汇编基础 1.3汇编一个简单的C语言程序并分析其汇编指令执行过程 因 ...
随机推荐
- 动态规划:POJ 3616 Milking Time
#include <iostream> #include <algorithm> #include <cstring> #include <cstdio> ...
- python学习笔记3-函数的递归
递归就是指自己函数的自我调用 #递归 #自己调用自己,函数的循环 def test1(): num = int(input('please enter a number:')) if num%2==0 ...
- Swift控制手电筒操作(iOS)
手电筒是iphone的一个常用功能,最常用的操作就是turn on和turn off,下面我们来实现一个简单的手电筒操作程序:一个按钮来控制iphone手电筒的On和Off,并且按钮的text也做相应 ...
- Python核心编程——Chapter9
好久没写过Python了,前一阵子忙这忙那的,都几乎把Python给丢掉了,话不多说,马上开始. 9.1.文件过滤.显示一个文件的所有行,并且忽略以井号开头的行. 其实这个题目比较基础,用shell语 ...
- Kafka消息系统基础知识索引
一些观念的修正 从 0.9 版本开始,Kafka 的标语已经从“一个高吞吐量,分布式的消息系统”改为"一个分布式流平台". Kafka不仅仅是一个队列,而且是一个存储,有超强的堆积 ...
- Linux下ssh的使用
更多内容推荐微信公众号,欢迎关注: 摘抄自:https://www.cnblogs.com/kevingrace/p/6110842.html 对于linux运维工作者而言,使用ssh远程远程服务器是 ...
- js实现数组、对象深度克隆的两种办法
1.深度克隆的原理 JS中的深度克隆,指的是原对象改变了,克隆出来的新对象也不会改变,原对象与新对象是完全独立的关系. 实现深度克隆的原理得从对象是一种引用类型说起 众所周知,对象是一种引用类型,对象 ...
- vue总结 06组件
组件基础 基本示例 这里有一个 Vue 组件的示例: // 定义一个名为 button-counter 的新组件Vue.component('button-counter', { data: func ...
- node练习笔记
一.用http模块实现客户端 1. 这个错误的原因是:客户端http_client.js里面的端口和服务端里面的端口不一样 2.querystring.stringify 字符串转换成对象 q ...
- CNN Architectures(AlexNet,VGG,GoogleNet,ResNet,DenseNet)
AlexNet (2012) The network had a very similar architecture as LeNet by Yann LeCun et al but was deep ...