YOLO V3 原理
基本思想V1:
- 将输入图像分成S*S个格子,每隔格子负责预测中心在此格子中的物体。
- 每个格子预测B个bounding box及其置信度(confidence score),以及C个类别概率。
- bbox信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化.
- 置信度反映是否包含物体,以及包含物体情况下位置的准确性。定义为Pr(Object)×IoU,其中Pr(Object)∈{0,1}
改进的V2:
YOLO v2主要改进是提高召回率和定位能力。
- Batch Normalization: v1中也大量用了Batch Normalization,同时在定位层后边用了dropout,v2中取消了dropout,在卷积层全部使用Batch Normalization。
- 高分辨率分类器:v1中使用224 × 224训练分类器网络,扩大到448用于检测网络。v2将ImageNet以448×448 的分辨率微调最初的分类网络,迭代10 epochs。
- Anchor Boxes:v1中直接在卷积层之后使用全连接层预测bbox的坐标。v2借鉴Faster R-CNN的思想预测bbox的偏移,移除了全连接层,并且删掉了一个pooling层使特征的分辨率更大。调整了网络的输入(448->416),以使得位置坐标为奇数,这样就只有一个中心点。加上Anchor Boxes能预测超过1000个。检测结果从69.5mAP,81% recall变为69.2 mAP,88% recall.
- YOLO v2对Faster R-CNN的首选先验框方法做了改进,采样k-means在训练集bbox上进行聚类产生合适的先验框。由于使用欧氏距离会使较大的bbox比小的bbox产生更大的误差,而IoU与bbox尺寸无关,因此使用IOU参与距离计算,使得通过这些anchor boxes获得好的IOU分值。
- 细粒度特征(fine grain features):借鉴了Faster R-CNN 和 SSD使用的不同尺寸的feature map,以适应不同尺度大小的目标。YOLOv2使用了一种不同的方法,简单添加一个pass through layer,把浅层特征图连接到深层特征图。通过叠加浅层特征图相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mapping。这个方法把26x26x512的特征图叠加成13x13x2048的特征图,与原生的深层特征图相连接,使模型有了细粒度特征。此方法使得模型的性能获得了1%的提升。
- Multi-Scale Training: 和YOLOv1训练时网络输入的图像尺寸固定不变不同,YOLOv2(在cfg文件中random=1时)每隔几次迭代后就会微调网络的输入尺寸。训练时每迭代10次,就会随机选择新的输入图像尺寸。因为YOLOv2的网络使用的downsamples倍率为32,所以使用32的倍数调整输入图像尺寸{320,352,…,608}。训练使用的最小的图像尺寸为320 x 320,最大的图像尺寸为608 x 608。 这使得网络可以适应多种不同尺度的输入。
- V2对V1的基础网络也做了修改。
改进的YOLO V3:
- 多尺度预测 ,类似FPN(feature pyramid networks)
- 更好的基础分类网络(类ResNet)和分类器
分类器:
- YOLOv3不使用Softmax对每个框进行分类,而使用多个logistic分类器,因为Softmax不适用于多标签分类,用独立的多个logistic分类器准确率也不会下降。
- 分类损失采用binary cross-entropy loss.
多尺度预测
- 每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3中尺度。
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息。
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍。
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
基础网络 Darknet-53:
仿ResNet, 与ResNet-101或ResNet-152准确率接近。
基础网络如下。
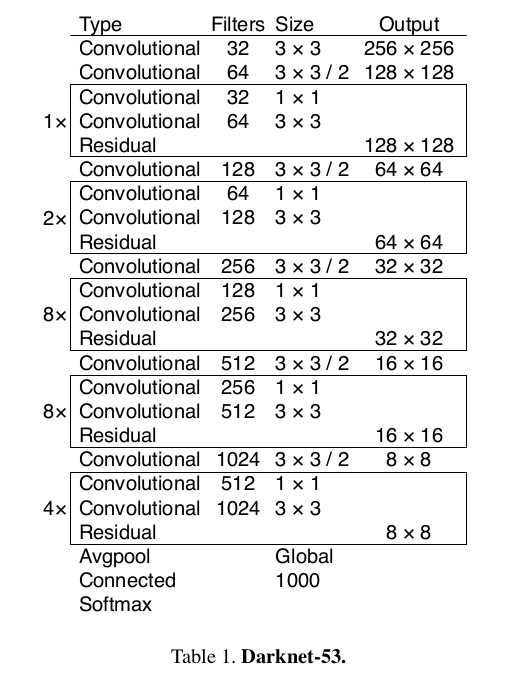

参考了:
http://www.cnblogs.com/makefile/p/YOLOv3.html
https://blog.csdn.net/qq_37541097/article/details/81214953
https://pjreddie.com/darknet/
YOLO V3 原理的更多相关文章
- Pytorch从0开始实现YOLO V3指南 part1——理解YOLO的工作
本教程翻译自https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/ 视频展示:https://w ...
- YOLO v3
yolo为you only look once. 是一个全卷积神经网络(FCN),它有75层卷积层,包含跳跃式传递和降采样,没有池化层,当stide=2时用做降采样. yolo的输出是一个特征映射(f ...
- YOLO系列:YOLO v3解析
本文好多内容转载自 https://blog.csdn.net/leviopku/article/details/82660381 yolo_v3 提供替换backbone.要想性能牛叉,backbo ...
- 深度学习笔记(十三)YOLO V3 (Tensorflow)
[代码剖析] 推荐阅读! SSD 学习笔记 之前看了一遍 YOLO V3 的论文,写的挺有意思的,尴尬的是,我这鱼的记忆,看完就忘了 于是只能借助于代码,再看一遍细节了. 源码目录总览 tens ...
- Yolo V3整体思路流程详解!
结合开源项目tensorflow-yolov3(https://link.zhihu.com/?target=https%3A//github.com/YunYang1994/tensorflow-y ...
- 非最大抑制,挑选和目标重叠框 yolo思想原理
非最大抑制,挑选和目标重叠框 yolo思想原理 待办 https://blog.csdn.net/shuzfan/article/details/52711706 根据分类器类别分类概率做排序,(框的 ...
- YOLO v3算法介绍
图片来自https://towardsdatascience.com/yolo-v3-object-detection-with-keras-461d2cfccef6 数据前处理 输入的图片维数:(4 ...
- 一文看懂YOLO v3
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf论文:YOLOv3: An Incremental Improvement YOLO系列的 ...
- Pytorch从0开始实现YOLO V3指南 part5——设计输入和输出的流程
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
随机推荐
- mysqli_fetch_row()函数返回结果的理解
在PHP处理对数据库查询返回的结果集,即mysqli_query()函数返回的结果集,我们可以把它处理为数组形式以便于处理. 我们一般会用下面四个函数: 1.array mysqli_fetch_ar ...
- sql语句优化原理
前言 网上有很多关于sql语句优化的文章,我这里想说下为什么这样...写sql语句,能够提高查询的效率. 1 sql语句优化原理 要想写出好的sql,就要学会用数据库的方式来思考如何执行sql,那么什 ...
- Geoserver通过ajax跨域访问服务数据的方法(含用户名密码认证的配置方式)
Goeserver数据有两种,一种需进行用户密码的权限认证,一种无须用户密码.对于网上跨域访问Geoserver数据的种种方法,对这2种数据并非通用. 笔者将Geoserver官方下载的Geoserv ...
- 《Node+MongoDB+React 项目实战开发》已出版
前言 从深圳回长沙已经快4个月了,除了把车开熟练了外,并没有什么值得一提的,长沙这边要么就是连续下一个月雨,要么就是连续一个月高温暴晒,上班更是没啥子意思,长沙这边的公司和深圳落差挺大的,薪资也是断崖 ...
- HTTP协议GET方法传参最大长度理解误区
结论 HTTP 协议未规定GET和POST的长度 GET的最大长度是因为浏览器和WEB服务器显示了URI的长度 不同浏览器和WEB服务器,限制的最大长度不同 若要支持IE,则最大长度为2083 byt ...
- Spring Cloud分区发布实践(1) 环境准备
最近研究了一下Spring Cloud里面的灰度发布, 看到各种各样的使用方式, 真是纷繁复杂, 眼花缭乱, 不同的场景需要不同的解决思路. 那我们也来实践一下最简单的场景: 区域划分: 服务分为be ...
- Dapr 客户端 搭配 WebApiClientCore 玩耍服务调用
使用Dapr 客户端 处理服务调用,需要遵循的他的模式,通常代码是这个样子的: var client = DaprClient.CreateInvokeHttpClient(appId: " ...
- Input 只能输入正数以及2位小数点
<input onkeyup="this.value= this.value.match(/\d+(\.\d{0,2})?/) ? this.value.match(/\d+(\.\d ...
- CSS样式逐li添加,执行完,清空,反复执行
function change_light(el) { el.hide() let i = 0; function temp() { if (i > el.length - 1) { el.hi ...
- BUUCTF[强网杯 2019]随便注(堆叠注入)
记一道堆叠注入的题.也是刷BUU的第一道题. ?inject=1' 报错 ?inject=1'--+ //正常 存在注入的.正常查询字段数,字段数为2.在联合查询的时候给了新提示 ?inject=0' ...