Adversarial Detection methods
- Kernel Density (KD)
- Local Intrinsic Dimensionality (LID)
- Gaussian Discriminant Analysis (GDA)
- Gaussian Mixture Model (GMM)
- SelectiveNet
- Combined Abstention Robustness Learning (CARL)
- Energy-based Out-of-distribution Detection
- Confidence-Calibrated Adversarial Training: Generalizing to Unseen Attacks (CCAT)
Kernel Density (KD)
作者认为普通样本的特征和对抗样本的特征位于不同的流形中, 故可以通过密度估计的方法, 估计出普通样本的密度函数, 然后求得样本各自的置信度, 选择合适的阈值(通过ROC-AUC之类的), 便有了区分普通样本和对抗样本的方法.
假设
\]
为将样本\(x\)提取为特征\(z\)
- 选取合适的样本数目\(x_1, \cdots, x_N\);
- 提取特征\(z_1, \cdots, z_N\);
- 构建核密度估计函数:
k_{\sigma}(z, z') = \frac{1}{(2\pi)^{\frac{d}{2}}\sigma^d}\exp (-\frac{\|z' - z\|^2}{2\sigma^2}).
\]
选择合适的阈值\(t\), 对于样本\(x\), 判定其为对抗样本, 若\(\hat{f}(x) < t\).
有些时候, 可以对每一类构建一个\(\hat{f}(x)\), 但这个情况也就只能用在ROC-AUC了.
Local Intrinsic Dimensionality (LID)
Gaussian Discriminant Analysis (GDA)
作者假设特征\(z=h(x)\)(所属类别为\(c\))满足后验分布:
\]
即
\]
注意到对于不同的\(c\), 协方差矩阵\(\Sigma\)是一致的(这个假设是为了便于直接用于分类, 但是与detection无关, 便不多赘述).
均值和协方差矩阵通过如下方式估计:
\]
故可以用
\]
来区分\(x\)是否为abnormal的样本(对抗的或者偏离训练分布的样本).
在文中用的是log化(且去掉比例系数)的指标:
\]
改方法可以进一步拓展(实际上光用这个指标看实验结果似乎并不理想):
- Input pre-processing:
对于输入的样本进行如下变换:
\]
有点像fgsm生成对抗样本, 但感觉这么做的原因是让\(\hat{f}(x)\)之间的区别大一点.
- Feature ensemble:
即对不同层的特征\(h_l(x)\)都进行如上的操作, 然后得到\(\hat{f}_1, \cdots, \hat{f}_L\), 并通过SVM来训练得到权重\(\alpha_l\), 最后的score为
\]
注: 文中实际为\(M_l(x)\).
Gaussian Mixture Model (GMM)
类似的, 对于特征\(z=h(x)\), 假设其服从GMM:
\]
并用EM算法来估计.
注: 对每一个类别都需要估计一个GMM模型.
于是
\]
当其小于给定的threshold的时候, 便认为其不属于类别\(c\).
问: 所以当所有的\(c\)都被拒绝的时候, 就可以认为是对抗样本了?
SelectiveNet
本文的模型解释起来有点复杂, 在一个普通的判别网络\(f\)的基础上:
\left \{
\begin{array}{ll}
f(x) & \text{if } g(x) = 1, \\
\text{don't know} & \text{if } g(x) = 0.
\end{array}
\right .
\]
其中\(g\)是一个用来选择是否判断的模块.
作者给出了两个指标:
Coverage:
\]
以及
Selective Risk:
\]
Coverage不能太低, 因为如果全部拒绝判断模型就没有意义了, 然后\(R(f, g)\)自然是越低越好, 但是注意到, 虽然一味拒绝回答能够使得分子接近0, 但是分母也会接近0, 所以需要一个平衡.
二者的经验估计如下:
\phi(g|S_N):= \frac{1}{N}\sum_{i=1}^N g(x_i).
\]
注: 在实际使用中, \(g\)的取值往往在\([0, 1]\)间, 此时可以选取threshold t来选择是否判断.
作者设计了一个结构如下:
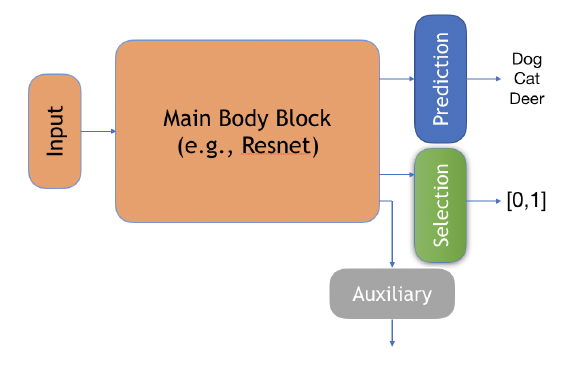
其中:
Prediction: \(f\);
Selection: \(g\);
Auxiliary: \(h\), 作者说此为别的任务来帮助训练的.
最后的损失:
\mathcal{L}_{(f, g)} = \hat{r}_{\ell} (f, g|S_N) + \lambda \Psi(c - \hat{\phi}(g | S_N)) \\
\Psi(a) = \max(0, a)^2 \\
\mathcal{L}_h = \hat{r}(h|S_N) = \frac{1}{N}\sum_{i=1}^N \ell (h(x_i), y_i).
\]
Combined Abstention Robustness Learning (CARL)
假设\(f\)将样本\(x\)映射为\(\mathcal{Y} \bigcup \{a\}\), 其中\(a\)表示弃权(don't know).
则我们可以定义:
\mathcal{R}_{adv}(f) := \mathbb{E}_{(x, y) \sim \mathcal{D}} \max_{\tilde{x} \in \mathcal{B}_{\epsilon}(x)} \mathbf{1}\{f(\tilde{x} \not = y \text{ and } f(\tilde{x}) \not = a\}.
\]
很自然的, 我们可以通过优化下列损失
\]
来获得一个带有弃权功能的判别器. 并且通过权重\(c\)我们可以选择更好的natural精度或者更保守但更加安全的策略.
直接优化上面的损失是困难的, 故选择损失来替换. 作者采用普通的交叉熵损失来代替nat:
\]
用下列之一替代adv:
\ell = \{\ell^{(1)}, \ell^{(2)}\} \\
\ell^{(1)} = -\log (p_y (\tilde{x}) + p_a (\tilde{x})) \\
\ell^{(2)} = (-\log (p_y (\tilde{x})) \cdot (-\log p_a (\tilde{x})) \\
\]
Adversarial Training with a Rejection Option
凸relax.
Energy-based Out-of-distribution Detection
普通的softmax分类网络可以从energy-based model的角度考虑:
E(x, y) = -f_y(x), \\
\]
Helmholtz free energy:
\]
实际上, 通过\(E(x;f)\)我们可以构建\(x\)的能量模型:
\]
故我们可以通过\(p(x)\)来判断一个样本是不是OOD的.
特别的, 由于对于所有的\(x\)
\]
都是一致的, 所以我们只需要比较
\]
的大小就可以了.
特别的, 作者指出为什么用\(p(y|x)\)来作为判断是否OOD的依据不合适:
\log \max_y p(y|x) &= \log \max_y \frac{e^{f_y(x)}}{\sum_i e^{f_i(x)}} \\
&= \log \frac{e^{f_{\max}(x)}}{\sum_i e^{f_i(x)}} \\
&= E(x;f(x) - f^{\max}(x)) \\
&= E(x;f) + f^{max}(x) \\
&= -\log p(x) + f^{max}(x) - \log Z \\
&\not\propto -\log p(x).
\end{array}
\]
WOW!
Confidence-Calibrated Adversarial Training: Generalizing to Unseen Attacks (CCAT)
假设\(f(x)\)为预测的概率向量, CCAT通过如下算法优化:
- 输入: \((x_1, y_1), \cdots, (x_B, y_B)\);
- 将其中一半用于对抗训练, 一半用于普通训练:
\]
- 其中
\tilde{y}_b = \lambda(\delta_b) \text{ one\_hot}(y_b) + (1 - \lambda(\delta_b)) \frac{1}{K}, \\
\delta_b = \mathop{\arg \max} \limits_{\delta_{\infty} \le \epsilon} \max_{k \not= y_b} f_k(x_b + \delta), \\
\lambda (\delta_b) := (1 - \min(1, \frac{\|\delta_b\|_{\infty}}{\epsilon}))^{\rho}. \\
\]
\(\tilde{y}\)是真实标签和均匀分布的一个凸组合, 这个还是挺有道理的.
最后, 倘若如果
\]
即置信度比较小的话, 拒绝判断(这个可靠的原因是目标函数让对抗样本趋于均匀分布).
Adversarial Detection methods的更多相关文章
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- [转]Jailbreak Detection Methods
Source: http://blog.spiderlabs.com/2014/10/jailbreak-detection-methods.html Many iOS applications co ...
- 生成对抗网络资源 Adversarial Nets Papers
来源:https://github.com/zhangqianhui/AdversarialNetsPapers AdversarialNetsPapers The classical Papers ...
- CVPR 2011 Global contrast based salient region detection
Two salient region detection methods are proposed in this paper: HC AND RC HC: Histogram based contr ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Anomaly Detection
数据集中的异常数据通常被成为异常点.离群点或孤立点等,典型特征是这些数据的特征或规则与大多数数据不一致,呈现出“异常”的特点,而检测这些数据的方法被称为异常检测. 异常数据根据原始数据集的不同可以分为 ...
- PP: Time series clustering via community detection in Networks
Improvement can be done in fulture:1. the algorithm of constructing network from distance matrix. 2. ...
- (转) AdversarialNetsPapers
本文转自:https://github.com/zhangqianhui/AdversarialNetsPapers AdversarialNetsPapers The classical Pap ...
- [转]GAN论文集
really-awesome-gan A list of papers and other resources on General Adversarial (Neural) Networks. Th ...
随机推荐
- adb命令对app进行测试
1.何为adb adb android debug bridge ,sdk包中的工具,将Platform-tooks 和tools 两个路径配置到环境变量中 2.SDK下载链接:http://t ...
- Linux学习 - 目录表
目录名 作用 权限 说明 /bin/ 存放系统命令的目录 所有用户 存放在/bin/下的命令单用户模式下也可以执行 /sbin/ 保存和系统环境设置相关的命令 root ...
- File类及常用操作方法
import java.io.File; import java.io.IOException; public class file { public static void main(String[ ...
- String类型和包装类型作为参数传递时,是属于值传递还是引用传递呢?
原理知识: 如果参数类型是原始类型,那么传过来的就是这个参数的一个副本,也就是这个原始参数的值,这个跟之前所谈的传值是一样的.如果在函数中改变了副本的 值不会改变原始的值. 如果参数类型是引用类型,那 ...
- 【Spark】【RDD】初次学习RDD 笔记 汇总
RDD Author:萌狼蓝天 [哔哩哔哩]萌狼蓝天 [博客]https://mllt.cc [博客园]萌狼蓝天 - 博客园 [微信公众号]mllt9920 [学习交流QQ群]238948804 目录 ...
- 第44篇-为native方法设置解释执行入口
对于Java中的native方法来说,实际上调用的是C/C++实现的本地函数,由于可能会在Java解释执行过程中调用native方法,或在本地函数的实现过程中调用Java方法,所以当两者相互调用时,必 ...
- 项目集成seata和mybatis-plus冲突问题解决方案:(分页插件失效, 自动填充失效, 自己注入的id生成器失效 找不到mapper文件解决方案)
项目集成seata和mybatis-plus,seata与mybatis-plus冲突问题(所有插件失效,自动填充失效,找不到mapper文件解决方案) 自动填充代码: package com.fro ...
- ios http 同步异步请求处理
转自:http://www.cnblogs.com/edisonfeng/p/3830224.html 一.服务端 1.主要结构:
- 【二进制】【WP】MOCTF逆向题解
moctf 逆向第一题:SOEASY 这个是个 64 位的软件,OD 打不开,只能用 IDA64 打开,直接搜字符串(shift+F12)就可以看到 moctf 逆向第二题:跳跳跳 这个题当初给了初学 ...
- box-shadow(盒子阴影)
box-shadow 属性可以设置一个或多个下拉阴影的框 可以在同一个元素上设置多个阴影效果,并用逗号将他们分隔开.该属性可设置的值包括阴影的X轴偏移量.Y轴偏移量.模糊半径.扩散半径和颜色. 语法: ...