python3制作捧腹网段子页爬虫
0x01
春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就自己照猫画虎,抓了点图片。
科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬点笑话比较有益于身心健康。

0x02
在我们撸起袖子开始搞之前,先来普及点理论知识。
简单地说,我们要把网页上特定位置的内容,扒拉下来,具体怎么扒拉,我们得先分析这个网页,看那块内容是我们需要的。比如,这次爬取的是捧腹网上的笑话,打开 捧腹网段子页我们可以看到一大堆笑话,我们的目的就是获取这些内容。看完回来冷静一下,你这样一直笑,我们没办法写代码。在 chrome 中,我们打开 审查元素 然后一级一级的展开 HTML 标签,或者点击那个小鼠标,定位我们所需要的元素。
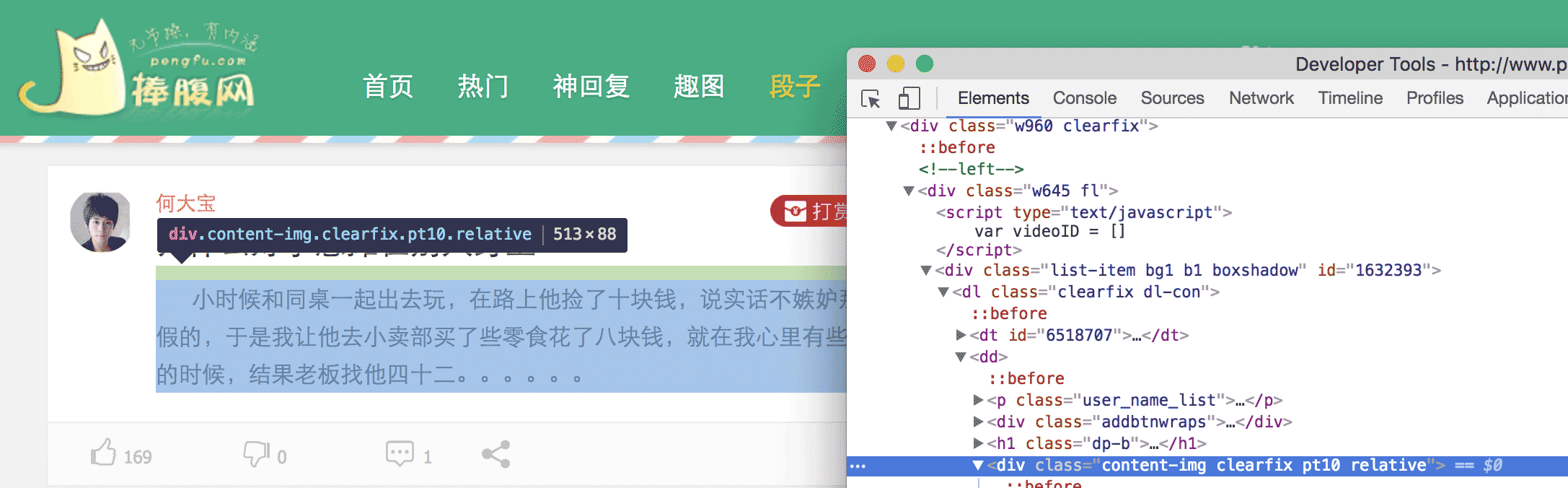
最后可以发现 <div> 中的内容就是我们所需要的笑话,在看第二条笑话,也是这样。于是乎,我们就可以把这个网页中所有的 <div> 找到,然后把里边的内容提取出来,就完成了。
0x03
好了,现在我们知道我们的目的了,就可以撸起袖子开始干了。这里我用的 python3,关于 python2 和 python3 的选用,大家可以自行决定,功能都可以实现,只是有些许不同。但还是建议用 python3。
我们要扒拉下我们需要的内容,首先我们得把这个网页扒拉下来,怎么扒拉呢,这里我们要用到一个库,叫 urllib,我们用这个库提供的方法,来获取整个网页。
首先,我们导入 urllib
然后,我们就可以使用 request 来获取网页了,
return request.urlopen(url).read()
人生苦短,我用 python,一行代码,下载网页,你说,还有什么理由不用 python。
下载完网页后,我们就得解析这个网页了来获取我们所需要的元素。为了解析元素,我们需要使用另外一个工具,叫做 Beautiful Soup,使用它,可以快速解析 HTML 和 XML并获取我们所需要的元素。
用 BeautifulSoup 来解析网页也就一句话,但当你运行代码的时候,会出现这么一个警告,提示要指定一个解析器,不然,可能会在其他平台或者系统上报错。
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))
解析器的种类 和 不同解析器之间的区别 官方文档有详细的说明,目前来说,还是用 lxml 解析比较靠谱。
修改之后
这样,就没有上述警告了。
利用 find_all 函数,来找到所有 class = content-img clearfix pt10 relative 的 div 标签 然后遍历这个数组
这样,我们就取到了目的 div 的内容。至此,我们已经达到了我们的目的,爬到了我们的笑话。
但当以同样的方式去爬取糗百的时候,会报这样一个错误
说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-import sysimport urllib.request as requestfrom bs4 import BeautifulSoupdef getHTML(url): headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} req = request.Request(url, headers=headers) return request.urlopen(req).read()def get_pengfu_results(url): soup = BeautifulSoup(getHTML(url), 'lxml') return soup.find_all('div', {'class':"content-img clearfix pt10 relative"})def get_pengfu_joke(): for x in range(1, 2): for x in get_pengfu_results(url): content = x.string try: string = content.lstrip() print(string + '\n\n') except: continue returndef get_qiubai_results(url): soup = BeautifulSoup(getHTML(url), 'lxml') contents = soup.find_all('div', {'class':'content'}) restlus = [] for x in contents: str = x.find('span').getText('\n','<br/>') restlus.append(str) return restlusdef get_qiubai_joke(): for x in range(1, 2): for x in get_qiubai_results(url): print(x + '\n\n') returnif __name__ == '__main__': get_pengfu_joke() get_qiubai_joke()python3制作捧腹网段子页爬虫的更多相关文章
- Go语言之进阶篇爬捧腹网
1.爬捧腹网 网页规律: https://www.pengfu.com/xiaohua_1.html 下一页 +1 https://www.pengfu.com/xiaohua_2.html 主页 ...
- Android实战:手把手实现“捧腹网”APP(一)-----捧腹网网页分析、数据获取
Android实战:手把手实现"捧腹网"APP(一)-–捧腹网网页分析.数据获取 Android实战:手把手实现"捧腹网"APP(二)-–捧腹APP原型设计.实 ...
- Android实战:手把手实现“捧腹网”APP(三)-----UI实现,逻辑实现
Android实战:手把手实现"捧腹网"APP(一)-–捧腹网网页分析.数据获取 Android实战:手把手实现"捧腹网"APP(二)-–捧腹APP原型设计.实 ...
- Android实战:手把手实现“捧腹网”APP(二)-----捧腹APP原型设计、实现框架选取
Android实战:手把手实现"捧腹网"APP(一)-–捧腹网网页分析.数据获取 Android实战:手把手实现"捧腹网"APP(二)-–捧腹APP原型设计.实 ...
- py3+urllib+re,爬虫下载捧腹网图片
实现原理及思路请参考我的另外几篇爬虫实践博客 py3+urllib+bs4+反爬,20+行代码教你爬取豆瓣妹子图:http://www.cnblogs.com/UncleYong/p/6892688. ...
- Go语言 之捧腹网爬虫案例
package main import ( "fmt" "net/http" "os" "regexp" "s ...
- [GO]并的爬取捧腹的段子
package main import ( "fmt" "strconv" "net/http" "regexp" &q ...
- AJAX接口-拉购网职位搜索爬虫
拉购网职位搜索爬虫 分析职位搜索调用接口: 浏览器开发者模式(快捷键F12)切换手机模式,打开拉购网职位搜索链接 https://m.lagou.com/search.html 输入搜索关键词, 例如 ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
随机推荐
- (剑指Offer)面试题40:数组中只出现一次的数字
题目: 一个整型数组里除了两个数字之外,其他的数字都出现了两次.请写程序找出这两个只出现一次的数字. 思路: 这道题的简单版本是除了一个数字之外,其他数字都出现了两次,这个很简单,将所有的数异或一遍就 ...
- sql分页性能测试结果
--方案一: declare @d datetime set @d = getdate() ID from Info order by ID) order by ID select [not in方法 ...
- .NET破解之爱奇迪(二)
爱奇迪的其他系统软件我不感兴趣,但这个Database2Sharp看起来好像很有用的. 官网介绍: 一个简单点击几次鼠标就能完成一周代码量的代码生成工具,效率惊人.友好体贴,真正的开发好伴侣,提供了对 ...
- Python——Shell编程关于Sha-Bang(#!)
Q. #!的名字为什么叫Sha-Bang? A. Sha-Bang是Sharp和Bang的组合词.Sharp for #, Bang for ! 类似的情况是,C#通常被称为C Sharp Q. Sh ...
- python -c 处理shell字符串
$test="hello world" $python -c "print '$test'.split()[1]" world 或者 $test="h ...
- Java之JVM调优案例分析与实战(2) - 集群间同步导致的内存溢出
环境:一个基于B/S的MIS系统,硬件为两台2个CPU.8GB内存的HP小型机,服务器是WebLogic 9.2,每台机器启动了3个WebLogic实例,构成一个6个节点的亲合式集群. 说明:由于是亲 ...
- UIScrollView 循环滚动,代码超简单
如今非常多应用里面多多少少都用到了循环滚动,要么是图片.要么是view,或者是其它,我总结一下,写了个demo分享给大家. 先看代码之后在讲原理: 1.创建一个空的项目(这个我就不多说了). 2.加入 ...
- 关于为什么要在项目中使用FTP文件服务器
传统的上传一般做法是http上传,后台接收文件流,然后写入到服务器本地硬盘的某个位置. 如果我们想把文件单独存放在别的服务器上,那就可以借助ftp服务器了. 上传的流程则变为,http上传,后台接收文 ...
- Javascript遍历页面控件
function validate(){ //var Elements = document.all; var Elements = document.getElementsByTagName(&q ...
- Linux防火墙的关闭和开启(转)
1) 重启后生效 开启: chkconfig iptables on 关闭: chkconfig iptables off 2) 即时生效,重启后失效 开启: service iptables sta ...