機器學習基石 机器学习基石(Machine Learning Foundations) 作业1 习题解答 (续)
这里写的是 习题1 中的 18 , 19, 20 题的解答。
Packet 方法,我这里是这样认为的,它所指的贪心算法是不管权重更新是否会对train data有改进都进行修正,因为这里面没有区分是否可以线性分割,如果线性可分那么每次的更新都注定是要使train data的分割效果得到提升,但是如果不是线性可分的,那么并不是每次的权重修正都可以使效果得到提升。 这时候的贪心算法是指不考虑每次权重的修正是否可以使优化效果得到提升,有错误的分割则进行一次权重修正。这种情况下我们不能保证一定会得到完美的分割,算法是否可以达到稳定而终止也是不确定的,该情况下则设置权重的最多更新次数。同时,将所有更新权重后得到的权重之中获得最优的权重。
根据上一个博客的实验,发现不管是不是线性可分的数据集,在权重更新的时候都不能保证一定会使数据分割的效果得到提升,也就是说每次的权重修正并不一定会使训练误差减小,基本可以说训练误差会随着权重修正而上下起伏的,但是线性可分的数据最终会得到完全的正确分割,线性不可分的数据最终也无法得到完全正确的分割,所以这时候Packet 方法上场了,也就是说对于不可以线性分割的数据我们如果还是用完全分割作为终止条件那么算法将永远不会停止,所以我们在Packet算法中以权重UPDATE的次数作为终止条件,又因为不论是线性可分还是不可分的数据集权重的优化效果都是上下起伏的,所以在Packet方法中我们只选择权重更新历史记录中最优的结果作为实验的最终答案。
第18题, Python编写:
#!/usr/bin/env python3
#encoding:UTF-8
import random
import copy
import urllib.request L=4
url_1="https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_train.dat"
url_2="https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_test.dat" "数据读入"
def dataLoad(url):
repones=urllib.request.urlopen(url)
dataList=repones.readlines()
dataList=[(float(v) for v in k.strip().split()) for k in dataList]
dataList=[(1.0,)+tuple(k) for k in dataList]
return dataList def test(dataList, w):
test_error=0 def sign(item):
s=0
for k in range(L+1):
s+=w[k]*item[k]
if(s>0):return 1
else:return -1 for item in dataList:
value=sign(item)
if(value!=item[-1]):
test_error+=1 error_rate=test_error/len(dataList)
return error_rate #训练过程
def train(train_data, test_data):
train_time=0
w_best=[0]*(L+1)
w_candidate=[0]*(L+1) def sign(item, w):
s=0
for k in range(L+1):
s+=w[k]*item[k]
if(s>0):return 1
else:return -1 def w_change(item):
nonlocal w_candidate
for k in range(L+1):
w_candidate[k]+=item[k]*item[-1] error_1=test(train_data, w_best) while(True):
for item in train_data:
value=sign(item, w_candidate)
if(value!=item[-1]):
w_change(item)
train_time+=1 error_2=test(train_data, w_candidate)
if(error_2<error_1):
w_best=copy.copy(w_candidate)
error_1=error_2 if(train_time==50):
return w_best if __name__=="__main__":
train_data=dataLoad(url_1) #train_data
test_data=dataLoad(url_2) #train_data error=[] for i in range(2000):
"打乱顺序"
random.shuffle(train_data)
w=train(train_data, test_data)
e=test(test_data, w)
print("第", i, "次实验,误差:", e)
error.append(e)
print(sum(error)/2000)

为了更好的理解 Packet 方法, 下面给出权重更新的部分过程:
第 370 次实验,误差: 0.154
error_1 0.39
error_2 0.61
error_2 0.346
error_2 0.39
error_2 0.374
error_2 0.61
error_2 0.316
error_2 0.61
error_2 0.364
error_2 0.608
error_2 0.212
error_2 0.604
error_2 0.186
error_2 0.61
error_2 0.264
error_2 0.388
error_2 0.14
error_2 0.526
error_2 0.332
error_2 0.332
error_2 0.368
error_2 0.422
error_2 0.226
error_2 0.564
error_2 0.224
error_2 0.478
error_2 0.246
error_2 0.386
error_2 0.204
error_2 0.422
error_2 0.264
error_2 0.262
error_2 0.264
error_2 0.434
error_2 0.226
error_2 0.53
error_2 0.234
error_2 0.39
error_2 0.232
error_2 0.418
error_2 0.2
error_2 0.48
error_2 0.21
error_2 0.542
error_2 0.234
error_2 0.538
error_2 0.232
error_2 0.558
error_2 0.25
error_2 0.466
error_2 0.332
第 371 次实验,误差: 0.138
error_1 0.39
error_2 0.61
error_2 0.448
error_2 0.39
error_2 0.348
error_2 0.61
error_2 0.382
error_2 0.602
error_2 0.326
error_2 0.488
error_2 0.3
error_2 0.526
error_2 0.164
error_2 0.61
error_2 0.21
error_2 0.61
error_2 0.262
error_2 0.61
error_2 0.19
error_2 0.604
error_2 0.252
error_2 0.556
error_2 0.176
error_2 0.572
error_2 0.208
error_2 0.5
error_2 0.252
error_2 0.454
error_2 0.228
error_2 0.378
error_2 0.61
error_2 0.388
error_2 0.334
error_2 0.386
error_2 0.26
error_2 0.516
error_2 0.244
error_2 0.374
error_2 0.298
error_2 0.248
error_2 0.372
error_2 0.156
error_2 0.602
error_2 0.128
error_2 0.382
error_2 0.138
error_2 0.38
error_2 0.11
error_2 0.568
error_2 0.142
error_2 0.588
第 372 次实验,误差: 0.106
第 19题:
#!/usr/bin/env python3
#encoding:UTF-8
import random
import copy
import urllib.request L=4
url_1="https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_train.dat"
url_2="https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_test.dat" "数据读入"
def dataLoad(url):
repones=urllib.request.urlopen(url)
dataList=repones.readlines()
dataList=[(float(v) for v in k.strip().split()) for k in dataList]
dataList=[(1.0,)+tuple(k) for k in dataList]
return dataList def test(dataList, w):
test_error=0 def sign(item):
s=0
for k in range(L+1):
s+=w[k]*item[k]
if(s>0):return 1
else:return -1 for item in dataList:
value=sign(item)
if(value!=item[-1]):
test_error+=1 error_rate=test_error/len(dataList)
return error_rate #训练过程
def train(train_data):
train_time=0
w_best=[0]*(L+1)
w_candidate=[0]*(L+1) def sign(item, w):
s=0
for k in range(L+1):
s+=w[k]*item[k]
if(s>0):return 1
else:return -1 def w_change(item):
nonlocal w_candidate
for k in range(L+1):
w_candidate[k]+=item[k]*item[-1] #error_1=test(train_data, w_best)
#print("error_1", error_1)
while(True):
for item in train_data:
value=sign(item, w_candidate)
if(value!=item[-1]):
w_change(item)
train_time+=1 #error_2=test(train_data, w_candidate)
#print("error_2", error_2)
#if(error_2<error_1):
# w_best=copy.copy(w_candidate)
# error_1=error_2 if(train_time==50):
#return w_best
return w_candidate if __name__=="__main__":
train_data=dataLoad(url_1) #train_data
test_data=dataLoad(url_2) #train_data error=[] for i in range(2000):
"打乱顺序"
random.shuffle(train_data)
w=train(train_data)
e=test(test_data, w)
print("第", i, "次实验,误差:", e)
error.append(e)
print(sum(error)/2000)

答案和 网上C++版的不太一样,那一版是0.27。
问题在哪,不知道,还在寻找中。
经过比对,最终找出了原因, c++版只进行了49次修正,而我写的是进行了50次修正,修改如下:
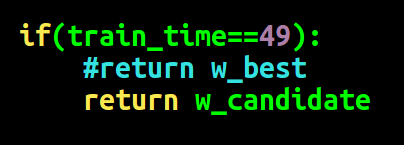
不随机情况下,Python 版结果:

C++ 版:
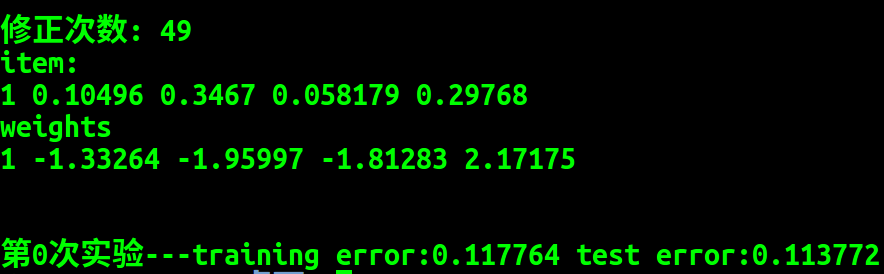
可以看到其结果大致相同, 错误排除成功。
第20题, 修改修正次数:
#!/usr/bin/env python3
#encoding:UTF-8
import random
import copy
import urllib.request L=4
url_1="https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_train.dat"
url_2="https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_test.dat" "数据读入"
def dataLoad(url):
repones=urllib.request.urlopen(url)
dataList=repones.readlines()
dataList=[(float(v) for v in k.strip().split()) for k in dataList]
dataList=[(1.0,)+tuple(k) for k in dataList]
return dataList def test(dataList, w):
test_error=0 def sign(item):
s=0
for k in range(L+1):
s+=w[k]*item[k]
if(s>0):return 1
else:return -1 for item in dataList:
value=sign(item)
if(value!=item[-1]):
test_error+=1 error_rate=test_error/len(dataList)
return error_rate #训练过程
def train(train_data, test_data):
train_time=0
w_best=[0]*(L+1)
w_candidate=[0]*(L+1) def sign(item, w):
s=0
for k in range(L+1):
s+=w[k]*item[k]
if(s>0):return 1
else:return -1 def w_change(item):
nonlocal w_candidate
for k in range(L+1):
w_candidate[k]+=item[k]*item[-1] error_1=test(train_data, w_best) while(True):
for item in train_data:
value=sign(item, w_candidate)
if(value!=item[-1]):
w_change(item)
train_time+=1 error_2=test(train_data, w_candidate)
if(error_2<error_1):
w_best=copy.copy(w_candidate)
error_1=error_2 if(train_time==100):
return w_best if __name__=="__main__":
train_data=dataLoad(url_1) #train_data
test_data=dataLoad(url_2) #train_data error=[] for i in range(2000):
"打乱顺序"
random.shuffle(train_data)
w=train(train_data, test_data)
e=test(test_data, w)
print("第", i, "次实验,误差:", e)
error.append(e)
print(sum(error)/2000)
结果:

機器學習基石 机器学习基石(Machine Learning Foundations) 作业1 习题解答 (续)的更多相关文章
- 機器學習基石(Machine Learning Foundations) 机器学习基石 课后习题链接汇总
大家好,我是Mac Jiang,非常高兴您能在百忙之中阅读我的博客!这个专题我主要讲的是Coursera-台湾大学-機器學習基石(Machine Learning Foundations)的课后习题解 ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 作业三 课后习题解答
今天和大家分享coursera-NTU-機器學習基石(Machine Learning Foundations)-作业三的习题解答.笔者在做这些题目时遇到非常多困难,当我在网上寻找答案时却找不到,而林 ...
- 機器學習基石 (Machine Learning Foundations) 作业1 Q15-17的C++实现
大家好,我是Mac Jiang.今天和大家分享Coursera-台湾大学-機器學習基石 (Machine Learning Foundations) -作业1的Q15-17题的C++实现. 这部分作业 ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 作业四 Q13-20 MATLAB实现
大家好,我是Mac Jiang,今天和大家分享Coursera-NTU-機器學習基石(Machine Learning Foundations)-作业四 Q13-20的MATLAB实现. 曾经的代码都 ...
- 機器學習基石 机器学习基石 (Machine Learining Foundations) 作业2 Q16-18 C++实现
大家好,我是Mac Jiang,今天和大家分享Coursera-NTU-機器學習基石(Machine Learning Foundations)-作业2 Q16-18的C++实现.尽管有非常多大神已经 ...
- 機器學習基石 机器学习基石(Machine Learning Foundations) 作业2 第10题 解答
由于前面分享的几篇博客已经把其他题的解决方法给出了链接,而这道题并没有,于是这里分享一下: 原题: 这题说白了就是求一个二维平面上的数据用决策树来分开,这就是说平面上的点只能画横竖两个线就要把所有的点 ...
- 我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)【中英双语】
我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)[中英双语] 视频地址:https://www.bilibili.com/video/av9912938/ t ...
- 机器学习(Machine Learning)
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科.
- Domain adaptation:连接机器学习(Machine Learning)与迁移学习(Transfer Learning)
domain adaptation(域适配)是一个连接机器学习(machine learning)与迁移学习(transfer learning)的新领域.这一问题的提出在于从原始问题(对应一个 so ...
随机推荐
- CNN笔记:通俗理解卷积神经网络【转】
本文转载自:https://blog.csdn.net/v_july_v/article/details/51812459 通俗理解卷积神经网络(cs231n与5月dl班课程笔记) 1 前言 2012 ...
- ThreadPoolExecutor源码浅析
目录 初始化 ctl变量 添加任务 addWorker方法 worker实现 执行任务 关闭连接池 参考 初始化 ThreadPoolExecutor重载了多个构造方法,不过最终都是调用的同一个: p ...
- 在linux上使用tomcat服务器图片验证码不显示问题
背景描述:在liunx系统上,使用tomcat中间件,访问web项目,登录页面的图片验证码显示不出来,但是在window系统上可以正常显示 解决方案:设置一下这个文件tomcat/bin/catali ...
- SpringMVC两种处理器适配器
1.实现Controller接口的处理器适配器 package com.xiaostudy; import javax.servlet.http.HttpServletRequest; import ...
- Ice Cream Tower
2017-08-18 21:53:38 writer:pprp 题意如下: Problem D. Ice Cream Tower Input file: Standard Input Output f ...
- Maximal Rectangle, 求矩阵中最大矩形,参考上一题
问题描述: Given a 2D binary matrix filled with 0's and 1's, find the largest rectangle containing only 1 ...
- wamp升级php7
原文:http://blog.csdn.net/cheng6251/article/details/50730441 1.下载php7 http://windows.PHP.net/downloa ...
- ElasticSearch介绍与安装
什么是ES? 1基于Apache Lucene构建的开源搜索引擎 2采用java编写,提供简单易用的RESTFul API 3轻松的横向扩展,可支持PB级的结构化或非结构化数据处理 ES的应用场景? ...
- 转 tensorflow模型保存 与 加载
使用tensorflow过程中,训练结束后我们需要用到模型文件.有时候,我们可能也需要用到别人训练好的模型,并在这个基础上再次训练.这时候我们需要掌握如何操作这些模型数据.看完本文,相信你一定会有收获 ...
- 堆 Heap
2018-03-01 20:38:34 堆(Heap)是可以用来实现优先的队列的数据结构,而不是堆栈. 若采用数组或者链表实现优先队列 若采用树的结构 如果采用二叉搜索树,那么每次删除,比如删除最大值 ...