Hadoop中的java基本类型的序列化封装类
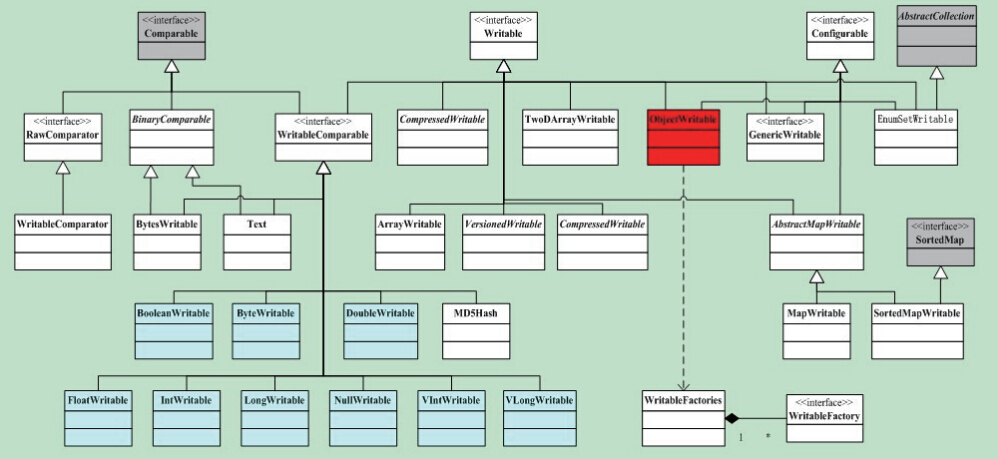
Hadoop将很多Writable类归入org.apache.hadoop.io包中,在这些类中,比较重要的有Java基本类、Text、Writable集合、ObjectWritable等,重点介绍Java基本类
1. Java基本类型的Writable封装
目前Java基本类型对应的Writable封装如下表所示。所有这些Writable类都继承自WritableComparable。也就是说,它们是可比较的。同时,它们都有get()和set()方法,用于获得和设置封装的值。
Java基本类型对应的Writable封装
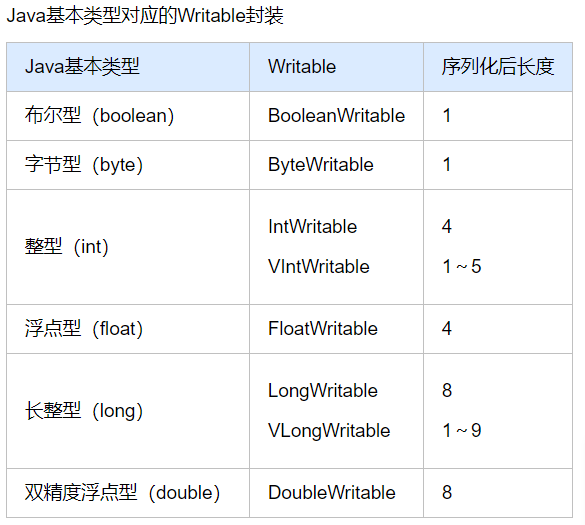
在表中,对整型(int和long)进行编码的时候,有固定长度格式(IntWritable和LongWritable)和可变长度格式(VIntWritable和VLongWritable)两种选择。固定长度格式的整型,序列化后的数据是定长的,而可变长度格式则使用一种比较灵活的编码方式,对于数值比较小的整型,它们往往比较节省空间。同时,由于VIntWritable和VLongWritable的编码规则是一样的,所以VIntWritable的输出可以用VLongWritable读入。下面以VIntWritable为例,说明Writable的Java基本类封装实现。代码如下:
public class VIntWritable implements WritableComparable {
private int value;
……
// 设置VIntWritable的值
public void set(int value) { this.value = value; }
// 获取VIntWritable的值
public int get() { return value; }
public void readFields(DataInput in) throws IOException {
value = WritableUtils.readVInt(in);
}
public void write(DataOutput out) throws IOException {
WritableUtils.writeVInt(out, value);
}
……
}
首先,每个Java基本类型的Writable封装,其类的内部都包含一个对应基本类型的成员变量value,get()和set()方法就是用来对该变量进行取值/赋值操作的。而Writable接口要求的readFields()和write()方法,VIntWritable则是通过调用Writable工具类中提供的readVInt()和writeVInt()读/写数据。方法readVInt()和writeVInt()的实现也只是简单调用了readVLong()和writeVLong(),所以,通过writeVInt()写的数据自然可以通过readVLong()读入。
writeVLong ()方法实现了对整型数值的变长编码,它的编码规则如下:
如果输入的整数大于或等于–112同时小于或等于127,那么编码需要1字节;否则,序列化结果的第一个字节,保存了输入整数的符号和后续编码的字节数。符号和后续字节数依据下面的编码规则(又一个规则):
如果是正数,则编码值范围落在–113和–120间(闭区间),后续字节数可以通过–(v+112)计算。
如果是负数,则编码值范围落在–121和–128间(闭区间),后续字节数可以通过–(v+120)计算。
后续编码将高位在前,写入输入的整数(除去前面全0字节)。代码如下:
public final class WritableUtils {
public stati cvoid writeVInt(DataOutput stream, int i) throws IOException
{
writeVLong(stream, i);
}
/**
* @param stream保存系列化结果输出流
* @param i 被序列化的整数
* @throws java.io.IOException
*/
public static void writeVLong(DataOutput stream, long i) throws……
{
//处于[-112, 127]的整数
if (i >= - && i <= ) {
stream.writeByte((byte)i);
return;
}
//计算情况2的第一个字节
int len = -;
if (i < ) {
i ^= -1L;
len = -;
}
long tmp = i;
while (tmp != ) {
tmp = tmp >> ;
len--;
}
stream.writeByte((byte)len);
len = (len < -) ? -(len + ) : -(len + );
//输出后续字节
for (int idx = len; idx != ; idx--) {
int shiftbits = (idx - ) * ;
long mask = 0xFFL << shiftbits;
stream.writeByte((byte)((i & mask) >> shiftbits));
}
}
}
原文链接:https://www.cnblogs.com/wuyudong/p/hadoop-writable.html
Hadoop中的java基本类型的序列化封装类的更多相关文章
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
- restframework中根据请求的类型修改序列化类
只要在视图中重写get_serializer_class方法就可以,用if对请求的类型进行判断 def get_serializer_class(self): if self.action == &q ...
- Java中Enum类型的序列化(转)
在Java中,对Enum类型的序列化与其他对象类型的序列化有所不同,今天就来看看到底有什么不同.下面先来看下在Java中,我们定义的Enum在被编译之后是长成什么样子的. Java代码: Java代码 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
- hadoop中的序列化
此文已由作者肖凡授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近在学习hadoop,发现hadoop的序列化过程和jdk的序列化有很大的区别,下面就来说说这两者的区别都有 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- hadoop 中对Vlong 和 Vint的压缩方法
hadoop 中对java的基本类型进行了writeable的封装,并且所有这些writeable都是继承自WritableComparable的,都是可比较的:并且,它们都有对应的get() 和 s ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
随机推荐
- Wannafly Winter Camp 2020 Day 5I Practice for KD Tree - 二维线段树
给定一个 \(n \times n\) 矩阵,先进行 \(m_1 \leq 5e4\) 次区间加,再进行 \(m_2 \leq 5e5\) 次询问,每次询问要求输出矩形区间内的最大数.\(n \leq ...
- Time series data mining
from here 论文Timeseries data mining(2012)中提出:时间序列数据挖掘包括7个基本任务和3个基础问题: 7 tasks: query by content clust ...
- vue.js中用npm安装vue-router时报错处理办法
当在使用npm安装东西的时候,最怕遇到的就是,电脑并不想和你说话,只向你抛出一大堆错误...比如在vue.js中用npm安装vue-router的时候,我就遇到 一脸蒙逼的我默默的念了一句:卧..槽. ...
- 题解 P5712 【【深基3.例4】Apples】
题目传送门 思路 仔细读题后,我们可以发现,输出可以分成\(2\)种情况,apple加s与apple不加s,所以我们可以使用if/else来实现. 接着,我们读入n. int n; cin>&g ...
- GYCTF easy_thinking
前期储备:ThinkPHP6 任意文件操作漏洞分析 https://paper.seebug.org/1114/ 学习链接: https://www.freebuf.com/articles/web/ ...
- qsort 与sort 对结构体排序实例
qsort 与sort 对结构体排序实例 #include<bits/stdc++.h> using namespace std; typedef struct { string book ...
- 安装配置oracle11gR2、client、plsql developer及学习
本文是一个目录,以后会持续更新 1,安装oracle11gR2 https://www.cnblogs.com/suterfo/p/10659208.html 2,安装oracle client及配置 ...
- MATLAB用“fitgmdist”函数拟合高斯混合模型(一维数据)
MATLAB用“fitgmdist”函数拟合高斯混合模型(一维数据) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在MATLAB中“fitgmdis ...
- jQuery---动态创建节点
动态创建节点 js的方法 var box = document.getElementById("box"); var a = document.createElement(&quo ...
- 自动生成admin(后台)
public --->>>>index.php 入口文件如下: // +---------------------------------------------------- ...