HashMap实现详解 基于JDK1.8
HashMap实现详解 基于JDK1.8
1.数据结构
散列表:是一种根据关键码值(Key value)而直接进行访问的数据结构。采用链地址法处理冲突。
HashMap采用Node<K,V>数组作为散列表来存储数据。源码声明如下:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
Node<K,V>节点的源码如下,可见Node<K,V>有四个成员。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 其余方法省略
}
散列函数:HashMap的散列函数很简单,i = (n - 1) & hash,将hash值与Node<K,V>数组的大小n通过&运算即得到在Node<K,V>数组中的位置i。
2.关键变量
有几个关键的变量需要事先理解,源码定义如下:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 这一步位移运算,得到结果16,作为Node<K,V>数组的初始大小,每次扩容都为原先的2倍。
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 又称负载因子,定义了扩容的时机,默认为存储元素达到了16*75%时就要进行扩容。
static final int TREEIFY_THRESHOLD = 8;
// 因为采用链地址法处理冲突,当链表过长时,HashMap性能会下降,因此当链表的长度超过8时,会将链表转换为红黑树进行优化。
static final int UNTREEIFY_THRESHOLD = 6;
// 在哈希表扩容时,如果发现链表长度小于 6,则会由树重新退化为链表。
static final int MIN_TREEIFY_CAPACITY = 64;
// 只有存储数量大于 64 才会发生转换。这是为了避免在哈希表建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。
3.put方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断散列表是否为空,若是,则进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 判断散列表位置是否冲突,若否,直接存储
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 处理冲突
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
put流程图
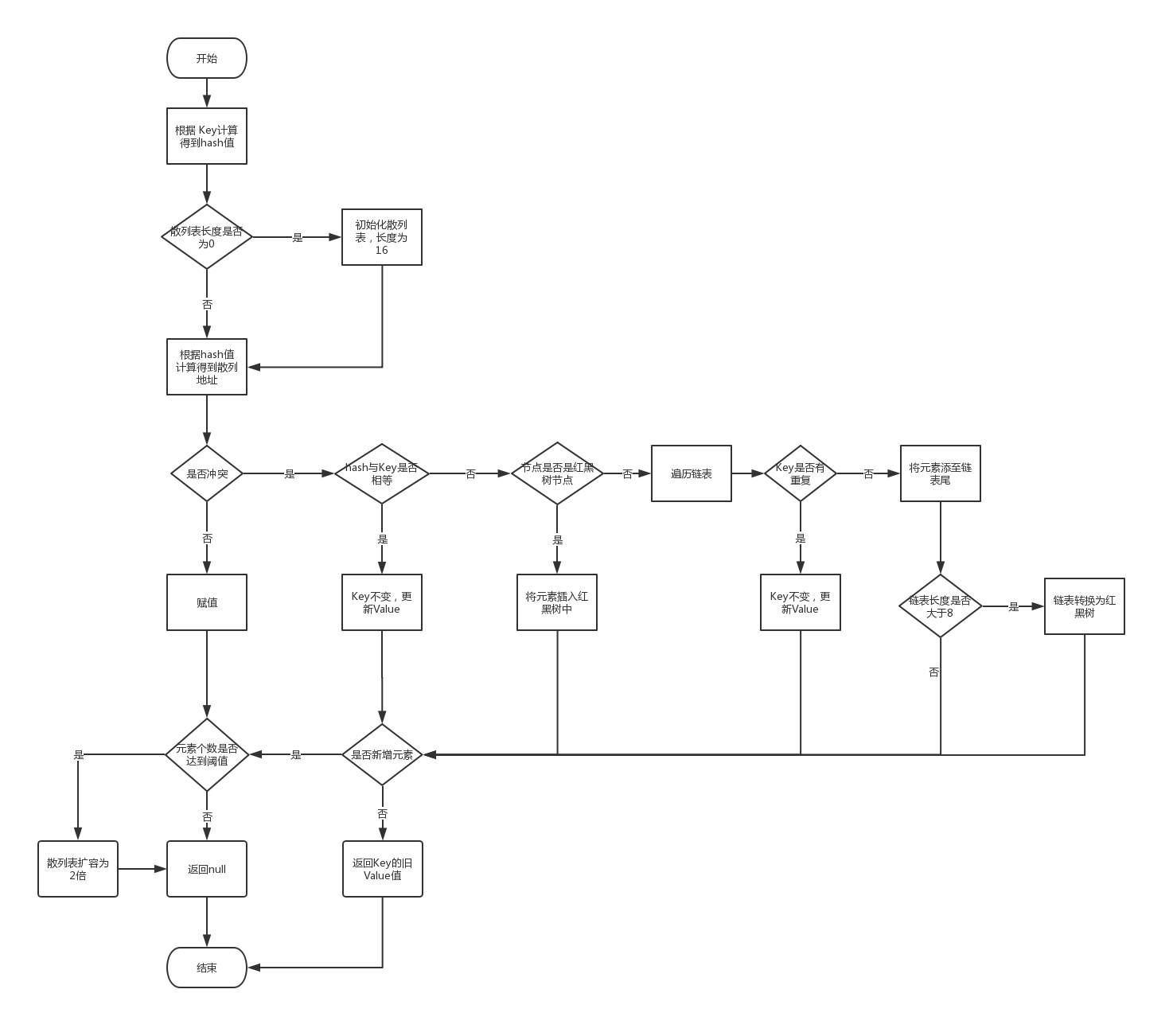
put流程总结:
1.根据Key计算hash,得到散列地址
2.若散列表大小为0,则初始化大小为16
3.若散列地址无冲突,则直接存储。若有冲突,则将元素存入链表或红黑树
4.当链表长度大于8,且总元素个数大于64时,将链表转换为红黑树
5.当总元素个数达到Capacity的75%时,将散列表扩容为2倍
4.get方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
get流程比较简单,直接总结一下:
1.根据Key计算hash,然后根据hash计算散列地址
2.判断元素hash与Key是否同时相等,相等则返回
3.若不相等,节点属于红黑树节点则在红黑树中查找,不属于则遍历链表查找
4.没有此节点则返回null
5.hash方法
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这是HashMap中计算hash值的方法,可以看出,这里首先调用key.hashCode()得到key的hash,然后将hash右移16位(最高为补0),与自身进行^(异或)运算,得到最终hash。这里有一个疑问,为什么要将hash值右移16位再来一个异或呢,直接用初始值不行吗?下面来看解释:
我们知道,HashMap中的散列地址是根据hash值得到的,方法是 (capacity-1)&hash,这个方法虽然很快,但是也带来一些副作用,这里也解释了为什么HashMap每次扩容都为2倍,因为这样 (capacity-1)恰好是一个掩码。
10110001 10100101 | 11000100 00100101 // hash值
& 00000000 00000000 | 00000000 00001111 // 16-1, 假设capacity为初始值16
-----------------------------------------
00000000 00000000 | 00000000 00000101 // 最终值5
当计算散列地址时,直接舍弃了高位的信息,只使用了capacity大小的容量,因此很有可能造成大量的地址冲突,效率降低。因此要利用被舍弃的高位信息,一个办法就是将高位与地位做^(异或)运算,使低位参杂高位信息。
10110001 10101001 | 11000100 00100101 // h=key.hashCode()
^ 00000000 00000000 | 10110001 10101001 // h >>> 16
-----------------------------------------
10110001 10101001 | 01110101 10001100 // hash
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
总结:hash()函数的作用是为了减少散列函数的副作用。
HashMap实现详解 基于JDK1.8的更多相关文章
- HashMap详解 基于jdk1.7
转载自:http://zhangshixi.iteye.com/blog/672697 1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操 ...
- 转:Java HashMap实现详解
Java HashMap实现详解 转:http://beyond99.blog.51cto.com/1469451/429789 1. HashMap概述: HashMap是基于哈希表的M ...
- JS hashMap实例详解
链接:http://www.jb51.net/article/85111.htm JS hashMap实例详解 作者:囧侠 字体:[增加 减小] 类型:转载 时间:2016-05-26我要评论 这篇文 ...
- HashMap 源码分析 基于jdk1.8分析
HashMap 源码分析 基于jdk1.8分析 1:数据结构: transient Node<K,V>[] table; //这里维护了一个 Node的数组结构: 下面看看Node的数 ...
- nrf52——DFU升级USB/UART升级方式详解(基于SDK开发例程)
摘要:在前面的nrf52--DFU升级OTA升级方式详解(基于SDK开发例程)一文中我测试了基于蓝牙的OTA,本文将开始基于UART和USB(USB_CDC_)进行升级测试. 整体升级流程: 整个过程 ...
- MapReduce过程详解(基于hadoop2.x架构)
本文基于hadoop2.x架构详细描述了mapreduce的执行过程,包括partition,combiner,shuffle等组件以及yarn平台与mapreduce编程模型的关系. mapredu ...
- 详解基于linux环境MySQL搭建与卸载
本篇文章将从实际操作的层面,讲解基于linux环境的mysql的搭建和卸载. 1 搭建mysql 1.1 官网下载mysql压缩包 下载压缩包时,可以先把安装包下载到本地,再上传到服务器,也可以在 ...
- 【Java基础】HashMap原理详解
哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中Has ...
- nrf52——DFU升级OTA升级方式详解(基于SDK开发例程)
在我们开始前,默认你已经安装好了一些基础工具,如nrfutil,如果你没有安装过请根据官方中文博客去安装好这些基础工具,连接如下:Nordic nRF5 SDK开发环境搭建(nRF51/nRF52芯片 ...
随机推荐
- C++学习——输入输出及头文件
C++学习 ——输入输出及头文件 一.输入输出 (1)cin与cout C++中也可以用printf与scanf,但是相对于这个,cin与cout更加方便一点.让我们先来看一段代码. 运行结果: 这里 ...
- 基于 HTML5 + WebGL 的无人机 3D 可视化系统
前言 近年来,无人机的发展越发迅速,既可民用于航拍,又可军用于侦察,涉及行业广泛,也被称为“会飞的照相机”.但作为军事使用,无人机的各项性能要求更加严格.重要.本系统则是通过 Hightopo 的 ...
- 洛谷$P$3168 任务查询系统 $[CQOI2015]$ 主席树
正解:主席树 解题报告: 传送门! 首先考虑如果是单点修改,那就是个线段树板子嘛$QwQ$ 然后现在是区间修改,对于区间修改,显然就考虑差分下,就变成单点修改辣$QwQ$ 同时单点查询前$k$小也就变 ...
- 超详细Node安装教程
今天周末休息,我制定了我的2020年度规划,其中包含编写50篇养成写博文的习惯.算下来平均每周一篇,感觉也不是很难,但我的写作能力不是很好,争取一次比一次好!希望自己能够坚持下去.2020为自己而活, ...
- 手摸手。完成一个H5 抽奖功能
要完成一个这样的抽奖功能 构思 奖励物品是通过接口获取的(img) 奖励结果是通过接口获取的(id) 抽奖的动画需要由慢到快再到慢 抽奖转动时间不能太短 抽奖结束需要回调 业务代码和功能代码要分离 先 ...
- 面试中经常问到的Redis七种数据类型,你都真正了解吗?
前言 Redis不是一个简单的键值对存储,它实际上是一个支持各种类型数据结构的存储.在传统的键值存储中,是将字符串键关联到字符串值,但是在Redis中,这些值不仅限于简单的字符串,还可以支持更复杂的数 ...
- python利用scapy嗅探流量
能实时监测流量, 只显示有问题的流量, 可疑流量要显示出在那个数据包里 所有流量都保存到为pcap 每5000个包保存一个 第3个自动下载到本地 def sniff(count=0, st ...
- 如何应用threejs实现立方体每个面用图片替换
var geometry = new THREE.BoxGeometry(200, 200, 200);var materialsbg = []; for (var i = 0; i < geo ...
- 沈阳网络赛 F - 上下界网络流
"Oh, There is a bipartite graph.""Make it Fantastic." X wants to check whether a ...
- LCA - 求任意两点间的距离
There are n houses in the village and some bidirectional roads connecting them. Every day peole alwa ...