[hadoop读书笔记] 第三章 HDFS
P49
当数据集的大小超过一台计算机存储能力时,就有必要对数据集分区(partition)并将分区存储到若干台独立的计算机上。
管理网络中跨多台计算机存储的系统就叫分布式文件系统 Distributed FileSystem
而基于Hadoop构建的DFS就称之为HDFS。
P49-50
HDFS的设计思路:以流数据访问模式来存储超大文件,运行在商用硬件集群上。


P51
HDFS 数据块:默认为64MB,是HDFS进行数据读写的最小单位,作为独立的存储单元存在。
一个打文件可以切分为多个块存储在不同节点的磁盘上,数据的备份是以块的方式来备份的。
P52
显示块信息命令:fsck
列出文件系统中各个文件由哪些块构成:hadoop fsck / -files -blocks
P56
fs.default.name - core-site.xml
用于设置Hadoop的默认文件系统,由URI指定,通常为:hdfs://ip:port/
表示将HDFS作为Hadoop的默认文件系统。HDFS的守护进程将会通过该属性来确定namenode的主机和端口。
如果不配置端口号 hdfs://ip/ 则默认端口为8020 ,namenode将会运行在8020端口上。
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.200.123:9000</value>
</property>
dfs.replication - hdfs-site.xml
用于设置数据块的副本数量,默认为3。如果是伪分布式配置时,则配置为1。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/wdcloud/data/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/wdcloud/data/hadoop/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
文件系统基本操作
查看帮助:hadoop fs -help
举例:
(1)将文件从本地文件系统复制到HDFS:
hadoop fs -copyFromLocal 本地文件路径/a.txt hdfs://ip:port/user/xxx/a.txt
当core-site.xml中配置了URI时,可以省略 hdfs://ip:port,直接运行
hadoop fs -copyFromLocal 本地文件路径/a.txt /user/xxx/a.txt
使用相对路径将文件复制到HDFS的home目录(/user/xxx/):
hadoop fs -copyFromLocal 本地文件路径/a.txt a.txt
(2)将文件从HDFS复制到本地文件系统
hadoop fs -copyToLocal xxx.txt(HDFS 的 home 下) xxx.copy.txt(本地文件系统)
(3)创建文件夹
hadoop fs -mkdir books
(4)列出目录文件
hadoop fs -ls .
drwxr-xr- - tom supergroup 0 2009-04-02 22:41 /user/tom/books
drwxr-xr- 1 tom supergroup 118 2009-04-02 22:29 /user/tom/xxx.txt
第一列文件模式
第二列数据块备份数目,目录作为元数据存储在namenode而非datanode中
3、4显示文件所属用户和组
5显示文件大小,字节为单位,目录为0
6、7列是文件的最后修改日期和时间
第8列是文件或目录的绝对路径
P58 Hadoop文件系统
Hadoop的文件系统的概念是抽象的 HDFS只是其中的一种实现。Java抽象类org.apache.hadoop.FileSystem定义了hadoop文件系统接口,有如下的具体实现:

使用URI可用于Hadoop与文件系统进行实时交互,如:
列出本地文件系统根目录下的文件:hadoop fs -ls file:///
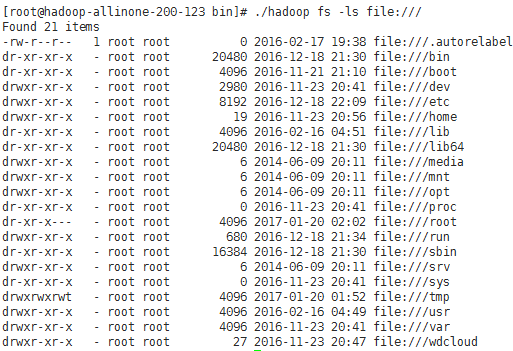
列出HDFS文件系统根目录下的文件

或

P61
namenode内置web服务器:默认运行在50070端口上,提供目录服务
datanode内置web服务器:默认运行在50075端口上,以数据流方式传输
配置:
dfs.webhdfs.enable - true
访问namenode的hdfs使用50070端口,访问datanode的webhdfs使用50075端口。访问文件、文件夹信息使用namenode的IP和50070端口,访问文件内容或者进行打开、上传、修改、下载等操作使用datanode的IP和50075端口。要想不区分端口,直接使用namenode的IP和端口进行所有的webhdfs操作,就需要在所有的datanode上都设置hefs-site.xml中的dfs.webhdfs.enabled为true。
端口配置
Hadoop 管理介面 - mapred-site.xml
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:</value>
</property> Hadoop Task Tracker 状态 - mapred-site.xml
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:</value>
</property> Hadoop DFS 状态 - hdfs-site.xml
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:</value>
</property>
curl操作webhdfs
创建并写一个文件
curl -i -X PUT "http://localhost:50070/webhdfs/v1/<PATH>?op=CREATE
[&overwrite=<true|false>][&blocksize=<LONG>][&replication=<SHORT>]
[&permission=<OCTAL>][&buffersize=<INT>]“
curl -i -X PUT -T <LOCAL_FILE> "http://<DATANODE>:<PORT>/webhdfs/v1/<PATH>?
op=CREATE...“
注意这个地方填入的是DataNode的信息 在一个文件内追加内容
curl -i -X POST "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=APPEND[&buffersize=<INT>]”
curl -i -X POST -T <LOCAL_FILE> "http://<DATANODE>:<PORT>/webhdfs/v1/<PATH>?
op=APPEND...“
注意该条命令获得的是DataNode的信息。 打开并读取一个文件
curl -i -L "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=OPEN
[&offset=<LONG>][&length=<LONG>][&buffersize=<INT>]“ 创建一个目录
curl -i -X PUT "http://<HOST>:<PORT>/<PATH>?op=MKDIRS[&permission=<OCTAL>]“ 重名命文件、文件夹
curl -i -X PUT "<HOST>:<PORT>/webhdfs/v1/<PATH>?op=RENAME&destination=<PATH>" 删除文件/文件夹
curl -i -X DELETE "http://<host>:<port>/webhdfs/v1/<path>?op=DELETE [&recursive=<true|false>]“ 文件/ 文件夹的状态信息
curl -i “http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=GETFILESTATUS“ 目录列表
curl -i "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=LISTSTATUS” 获取目录的上下文环境汇总信息
curl -i "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=GETCONTENTSUMMARY" 获取Check Sum File
curl -i "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=GETFILECHECKSUM” 获取Home 目录
curl -i "http://<HOST>:<PORT>/webhdfs/v1/?op=GETHOMEDIRECTORY” 设置权限
curl -i -X PUT "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=SETPERMISSION [&permission=<OCTAL>]“ 设置所有者
curl -i -X PUT "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=SETOWNER [&owner=<USER>][&group=<GROUP>]" 设置备份
curl -i -X PUT "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=SETREPLICATION [&replication=<SHORT>]“
P63
使用Java接口与Hadoop文件系统进行交互
FileSystem:与Hadoop中某文件系统进行交互的API
DistributedFileSystem:与HDFS文件系统进行交互的API
P64 通过FileSystem API 读取数据
1、检索文件系统
public static FileSystem get(Configuration conf)
返回core-site.xml中配置的默认文件系统,若没有配置,使用本地文件系统
public static FileSystem get(URI uri,Configuration conf)
返回给定的URI指定的文件系统,若URI为空,返回默认文件系统
public static FileSystem get(URI uri,Configuration conf,String user)
作为给定用户访问文件系统
Configuration:封装了客户端或服务器的配置
如果确定获取本地文件系统,直接使用
public static LocalFileSystem getLocal(Configuration conf)
2、获取文件输入流
public FSDataInputStream open(Path f) - 默认缓冲区大小4KB
public abstract FSDataInputStream open(Path f,int bufferSize)
FSDataInputStream - 这个类继承了java.io.DataInputStream接口,支持随机访问,可以从流的任意位置读取数据
实例:

P68 通过FileSystem API 写入数据
public FSDataOutputStream create(Path f)
public FSDataOutputStream append(Path f)
例子:将本地文件复制到hadoop文件系统
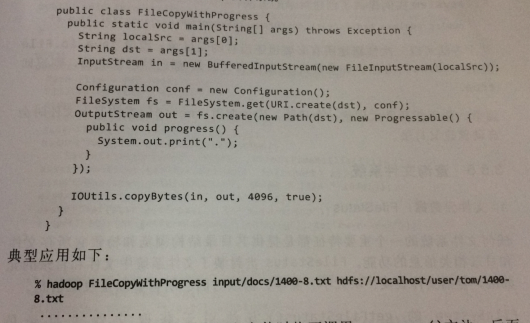
P72 查询文件系统

P83
Apache Flume:将大规模流数据导入HDFS的工具
典型应用:日志数据分析
Flume支持包含tail,通过管道的方式将本地文件写入Flume中,以及syslog和apcache log4j的系统
Apache sqoop:为了将数据从结构化存储设备(RDBMS)批量导入HDFS中设计的
用于将白天生产的数据库中的数据导入Hive仓库中进行分析
distcp:Hadoop分布式复制程序,用于在hadoop文件系统之间复制大量数据,作为MR作业来实现的。
复制数据命令行:hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
在namenode的bar/foo文件下存储复制的数据
更新数据:hadoop distcp -update hadfs://namenode1/foo hdfs://namenode2/bar/foo
注意,使用以上命令两个集群的HDFS版本必须相同,如果不同,则使用基于HTTp协议的HFTP文件系统读取源文件系统数据。
且这个作业必须运行在目标集群上,实现HDFS RPC版本的兼容
命令行:hadoop distcp hftp://namenode1:50070/foo hdfs://namenode2/bar
或直接使用webhdfs协议也可以:
hadoop distcp webhdfs://namenode1:50070/foo webhdfs://namenode2:50070/bar
P86 Hadoop 存档工具
为什么需要?
Hadopp文件按块存储,每个块的元数据存储在namenode的内存中,如果小文件过多,则大量的小文件会耗尽namenode的大量内存。
Hadoop存档文件/HAR文件是一个高效的文件存档工具,在减少namenode内存的同时,允许对文件进行透明的访问。
对一系列文件进行存档命令:hadoop archive -archiveName files.har /my/files(被打包目录) /my(存档文件输出目录)

删除har文件,要用递归的形式进行删除,因为基于文件系统来说,HAR文件是一个目录
hadoop fs -rmr /my/files.har
[hadoop读书笔记] 第三章 HDFS的更多相关文章
- Hadoop读书笔记(四)HDFS体系结构
Hadoop读书笔记(一)Hadoop介绍:http://blog.csdn.net/caicongyang/article/details/39898629 Hadoop读书笔记(二)HDFS的sh ...
- 《Linux内核设计与分析》第六周读书笔记——第三章
<Linux内核设计与实现>第六周读书笔记——第三章 20135301张忻估算学习时间:共2.5小时读书:2.0代码:0作业:0博客:0.5实际学习时间:共3.0小时读书:2.0代码:0作 ...
- Hadoop读书笔记(二)HDFS的shell操作
Hadoop读书笔记(一)Hadoop介绍:http://blog.csdn.net/caicongyang/article/details/39898629 1.shell操作 1.1全部的HDFS ...
- 《Linux内核设计与实现》读书笔记 第三章 进程管理
第三章进程管理 进程是Unix操作系统抽象概念中最基本的一种.我们拥有操作系统就是为了运行用户程序,因此,进程管理就是所有操作系统的心脏所在. 3.1进程 概念: 进程:处于执行期的程序.但不仅局限于 ...
- 《CSS3实战》读书笔记 第三章:选择器:样式实现的标记
第三章:选择器:样式实现的标记 选择器的魔力在于,让你完全实现对网页样式的掌控.不同的选择器可以用在不同的情况下使用.总之把握的原则是:规范的编码,根据合理地使用选择器,比去背选择器的定义有价值的多. ...
- 《linux内核设计与实现》读书笔记第三章
第3章 进程管理 3.1 进程 1.进程 进程就是处于执行期的程序. 进程包括: 可执行程序代码 打开的文件 挂起的信号 内核内部数据 处理器状态 一个或多个具有内存映射的内存地址空间 一个或多个执行 ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- 《R语言实战》读书笔记--第三章 图形初阶(二)
3.4添加文本.自定义坐标轴和图例 很多作图函数可以设置坐标轴和文本标注.比如标题.副标题.坐标轴标签.坐标轴范围等.需要注意的是并不是所有的绘图函数都有上述的参数,需要进行验证.可以将一些默认的参数 ...
- .net架构设计读书笔记--第三章 第9节 域模型实现(ImplementingDomain Model)
我们长时间争论什么方案是实现域业务领域层架构的最佳方法.最后,我们用一个在线商店案例来说明,其中忽略了许多之前遇到的一些场景.在线商店对很多人来说更容易理解. 一.在线商店项目简介 1. 用例 ...
随机推荐
- Java:concurrent包下面的Map接口框架图(ConcurrentMap接口、ConcurrentHashMap实现类)
Java集合大致可分为Set.List和Map三种体系,其中Set代表无序.不可重复的集合:List代表有序.重复的集合:而Map则代表具有映射关系的集合.Java 5之后,增加了Queue体系集合, ...
- Subclipse和TortoiseSVN版本不一致导致升到高版本的project后,低版本svn客户端无法使用。
- cannot send list of active checks to [ZabbixServerIp]: host [Zabbix server] not found
解决办法 因为web端上被监控端的主机名和zabbix_agentd.conf中的Hostname名字不一样,改为一样的即可 注意发现问题一定要看日志: tail -f /var/log/zabbix ...
- 不可恢复的生成错误mergemod.dll 2.0.2600.0
在进行Visual Studio 2008 进行Winform打包时,提示 不可恢复的生成错误,很是郁闷,1.在“开始 - 运行” 中输入以下内容分三次来重新注册下Mergemod.dll. regs ...
- 此编译单元不包含在frame元数据中指定的factoryClass,无法加载配置的运行时共享库
警告:此编译单元不包含在frame元数据中指定的factoryClass,无法加载配置的运行时共享库.要在没有运行时共享库的情况下进行编译,请将 -static-link-runtime-shared ...
- 【硅谷问道】Chris Lattner 访谈录(下)
[硅谷问道]Chris Lattner 访谈录(下) Chris Lattner 访谈录(下) 话题 Swift 在 Server 和操作系统方面有着怎样的雄心抱负? Swift 与 Objectiv ...
- 使用CountDownTimer实现倒计时功能
// 倒计时60s new CountDownTimer(60000, 1000) { @Override public void onTick(long millisUntilFinished) { ...
- Lua函数[转]
在大多数Lua语法分析中可以获得这些标准Lua函数. 无可争辩, 我们可以查阅Lua网站, 但是一些少了的函数被Blizzard进行了调整. 下面列出了所有Lua函数. WoW API中的Lua注意在 ...
- kindeditor自定义插件插入视频代码
kindeditor自定义插件插入视频代码 1.添加插件js 目录:/kindeditor/plugins/diy_video/diy_video.js KindEditor.plugin('diy_ ...
- SparkStreaming python 读取kafka数据将结果输出到单个指定本地文件
# -*- coding: UTF-8 -*- #!/bin/env python3 # filename readFromKafkaStreamingGetLocation.py import IP ...