『cs231n』作业2选讲_通过代码理解Dropout
Dropout

def dropout_forward(x, dropout_param):
p, mode = dropout_param['p'], dropout_param['mode']
if 'seed' in dropout_param:
np.random.seed(dropout_param['seed']) mask = None
out = None
if mode == 'train':
#训练环节开启
mask = (np.random.rand(*x.shape) < p) / p
out = x * mask
elif mode == 'test': #测试环节关闭
out = x cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False) return out, cache def dropout_backward(dout, cache):
dropout_param, mask = cache
mode = dropout_param['mode']
dx = None if mode == 'train':
dx = dout * mask
elif mode == 'test':
dx = dout return dx
Batch Normalization
Batch Normalization就是在每一层的wx+b和f(wx+b)之间加一个归一化(将wx+b归一化成:均值为0,方差为1
通常:Means should be close to zero and stds close to one
gamma, beta = np.ones(C), np.zeros(C)
先给出Batch Normalization的算法和反向求导公式:
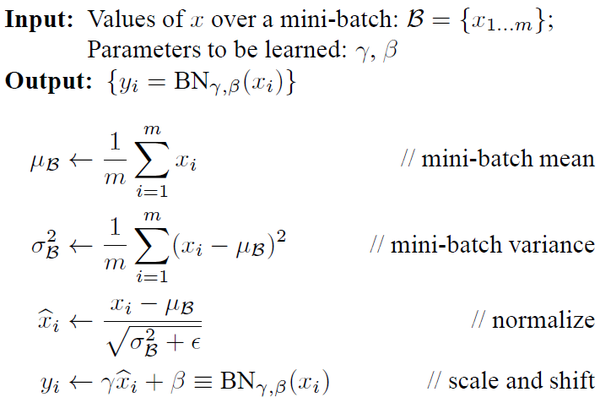
import numpy as np def batchnorm_forward(x, gamma, beta, bn_param):
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype)) out, cache = None, None
if mode == 'train':
sample_mean = np.mean(x, axis=0, keepdims=True) # [1,D]
sample_var = np.var(x, axis=0, keepdims=True) # [1,D]
x_normalized = (x - sample_mean) / np.sqrt(sample_var + eps) # [N,D]
out = gamma * x_normalized + beta
cache = (x_normalized, gamma, beta, sample_mean, sample_var, x, eps)
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
elif mode == 'test':
x_normalized = (x - running_mean) / np.sqrt(running_var + eps)
out = gamma * x_normalized + beta
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode) # Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var return out, cache def batchnorm_backward(dout, cache):
dx, dgamma, dbeta = None, None, None
x_normalized, gamma, beta, sample_mean, sample_var, x, eps = cache
N, D = x.shape
dx_normalized = dout * gamma # [N,D]
x_mu = x - sample_mean # [N,D]
sample_std_inv = 1.0 / np.sqrt(sample_var + eps) # [1,D]
dsample_var = -0.5 * np.sum(dx_normalized * x_mu, axis=0, keepdims=True) * sample_std_inv**3
dsample_mean = -1.0 * np.sum(dx_normalized * sample_std_inv, axis=0, keepdims=True) - \
2.0 * dsample_var * np.mean(x_mu, axis=0, keepdims=True)
dx1 = dx_normalized * sample_std_inv
dx2 = 2.0/N * dsample_var * x_mu
dx = dx1 + dx2 + 1.0/N * dsample_mean
dgamma = np.sum(dout * x_normalized, axis=0, keepdims=True)
dbeta = np.sum(dout, axis=0, keepdims=True) return dx, dgamma, dbeta
批量归一化(spatia Batch Normalization)
我们已经看到,批量归一化是训练深度完全连接网络的非常有用的技术。批量归一化也可以用于卷积网络,但我们需要调整它一点;该修改将被称为“空间批量归一化”。
通常,批量归一化接受形状(N,D)的输入并产生形状(N,D)的输出,其中我们在小批量维度N上归一化。对于来自卷积层的数据,批归一化需要接受形状(N,C,H,W),并且产生形状(N,C,H,W)的输出,其中N维给出小容器大小,(H,W)维给出特征图的空间大小。
如果使用卷积产生特征图,则我们期望每个特征通道的统计在相同图像内的不同图像和不同位置之间相对一致。因此,空间批量归一化通过计算小批量维度N和空间维度H和W上的统计量来计算C个特征通道中的每一个的平均值和方差。
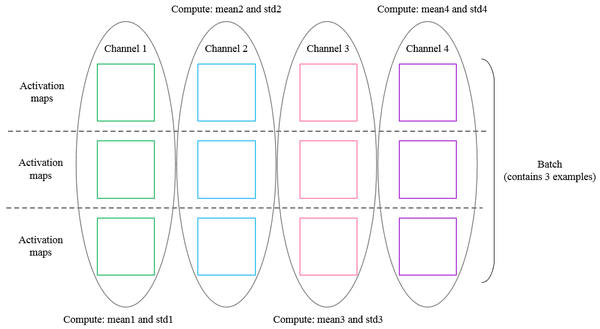
同样的:#Means should be close to zero and stds close to one
gamma, beta = np.ones(C), np.zeros(C)
代码如下,
def spatial_batchnorm_forward(x, gamma, beta, bn_param):
N, C, H, W = x.shape
x_new = x.transpose(0, 2, 3, 1).reshape(N*H*W, C)
out, cache = batchnorm_forward(x_new, gamma, beta, bn_param)
out = out.reshape(N, H, W, C).transpose(0, 3, 1, 2) return out, cache def spatial_batchnorm_backward(dout, cache):
N, C, H, W = dout.shape
dout_new = dout.transpose(0, 2, 3, 1).reshape(N*H*W, C)
dx, dgamma, dbeta = batchnorm_backward(dout_new, cache)
dx = dx.reshape(N, H, W, C).transpose(0, 3, 1, 2) return dx, dgamma, dbeta
『cs231n』作业2选讲_通过代码理解Dropout的更多相关文章
- 『cs231n』作业2选讲_通过代码理解优化器
1).Adagrad一种自适应学习率算法,实现代码如下: cache += dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps) 这种方法的 ...
- 『cs231n』作业1选讲_通过代码理解KNN&交叉验证&SVM
通过K近邻算法探究numpy向量运算提速 茴香豆的“茴”字有... ... 使用三种计算图片距离的方式实现K近邻算法: 1.最为基础的双循环 2.利用numpy的broadca机制实现单循环 3.利用 ...
- 『cs231n』作业3问题1选讲_通过代码理解RNN&图像标注训练
一份不错的作业3资料(含答案) RNN神经元理解 单个RNN神经元行为 括号中表示的是维度 向前传播 def rnn_step_forward(x, prev_h, Wx, Wh, b): " ...
- 『cs231n』作业3问题3选讲_通过代码理解图像梯度
Saliency Maps 这部分想探究一下 CNN 内部的原理,参考论文 Deep Inside Convolutional Networks: Visualising Image Classifi ...
- 『cs231n』作业3问题2选讲_通过代码理解LSTM网络
LSTM神经元行为分析 LSTM 公式可以描述如下: itftotgtctht=sigmoid(Wixxt+Wihht−1+bi)=sigmoid(Wfxxt+Wfhht−1+bf)=sigmoid( ...
- 『cs231n』作业3问题4选讲_图像梯度应用强化
[注],本节(上节也是)的model是一个已经训练完成的CNN分类网络. 随机数图片向前传播后对目标类优化,反向优化图片本体 def create_class_visualization(target ...
- 『cs231n』计算机视觉基础
线性分类器损失函数明细: 『cs231n』线性分类器损失函数 最优化Optimiz部分代码: 1.随机搜索 bestloss = float('inf') # 无穷大 for num in range ...
- 『cs231n』通过代码理解风格迁移
『cs231n』卷积神经网络的可视化应用 文件目录 vgg16.py import os import numpy as np import tensorflow as tf from downloa ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
随机推荐
- MySQL数据库读写分离、读负载均衡方案选择
MySQL数据库读写分离.读负载均衡方案选择 一.MySQL Cluster外键所关联的记录在别的分片节点中性能很差对需要进行分片的表需要修改引擎Innodb为NDB因此MySQL Cluster不适 ...
- aspose 小记
/// <summary> /// 定位书签替换值 /// </summary> /// <param name="documentBuilder"& ...
- Notes of Head.First.HTML.and.CSS.2nd.Edition
What does the web server do? tirelessly waiting for requests from webbrowsers What does the web brow ...
- 轻量级文本标记语言-Markdown
Markdown简介 接触过github的都知道,在发布项目的时候可以建立一个说明文件README.md,这个md文件就是Markdown文本编辑语言的文件. Markdown 是一种轻量级标记语言, ...
- Thinkphp5 引入第三方类库的方法
原文链接:http://www.zhaisui.com/article/42.html
- 20145206邹京儒 Exp8 Web基础
20145206邹京儒 Exp8 Web基础 一.实践过程记录 Apache (一)环境配置 1.查看端口占用:在这里apach2占用端口80 2.测试apache是否正常工作:在kali的火狐浏览器 ...
- 20145322 Exp5 Adobe阅读器漏洞攻击
20145322 Exp5 Adobe阅读器漏洞攻击 实验过程 IP:kali:192.168.1.102 windowsxp :192.168.1.119 msfconsole进入控制台 使用命令为 ...
- ["1", "2", "3"].map(parseInt) 为何返回[1,NaN,NaN]
转载自:http://blog.csdn.net/freshlover/article/details/19034079 这涉及到是否深入理解两个函数的格式与参数含义. 首先根据我对两个函数用法的了解 ...
- Educational Codeforces Round 21 Problem E(Codeforces 808E) - 动态规划 - 贪心
After several latest reforms many tourists are planning to visit Berland, and Berland people underst ...
- java 关于wait,notify和notifyAll
public synchronized void hurt() { //... this.wait(); //... } public synchronized void recover() { // ...