hbase概念
1. 概述(扯淡~)
HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统。
由此可见:
1. 几乎所有的HBase中的理念,都可以从BigTable论文中得到解释。原文是英语的,而且还有不少数学概念,看了有点儿懵,建议网上找找学习笔记看看,差不多也就可以入门了。
2. Google确实牛X。
3. 老外也爱山寨~
第一次看HBase, 可能看到以下描述会懵:“基于列存储”,“稀疏MAP”,“RowKey”,“ColumnFamily”。
其实没那么高深,我们需要分两步来理解HBase, 就能够理解为什么HBase能够“快速地”“分布式地”处理“大量数据”了。
1.内存结构
2.文件存储结构
2. 名词概念以及内存结构
假设我们有一张表(其中只有一条数据):
|
RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
|
Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
1) RowKey: 行键,可理解成MySQL中的主键列。
2) Column: 列,可理解成MySQL列。
3) ColumnFamily: 列族, HBase引入的概念:
- 将多个列聚合成一个列族。
- 可以理解成MySQL的垂直分区(将一张宽表,切分成几张不那么宽的表)。
- 此机制引入的原因,是因为HBase相信,查询可能并不需要将一整行的所有列数据全部返回。(就像我们往往在写SQL时不太会写select all一样)
- 对应到文件存储结构(不同的ColumnFamily会写入不同的文件)。
4) TimeStamp:在每次跟新数据时,用以标识一行数据的不同版本(事实上,TimeStamp是与列绑定的。)
那我们为何会得到HBase的读写高性能呢?其实所有数据库操作如何得到高性能,答案几乎都是一致的,就是做索引。
HBase的设计抛弃了传统RDBMS的行式数据模型,把索引和数据模型原生的集成在了一起。
以上图的表为例,表数据在HBase内部用Map实现,我们把它写成JSon的Object表述,即:

{
"com.google": {
CF1: {
C11:{
T1: good
}
C12:{
T1: good
}
CF2: {
C21:{
T1: bad
}
C22:{
T1: bad
}
}
}
}
由于Map本身可以通过B+树来实现,所以随机访问的速度大大加快(我们需要想象一下,表中有很多行的情况)。
现在我们在原来的表上修改一下(将Column: C22改为”good”):
|
RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
|
Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 good” |
T2 |
于是MAP变为了:
{
"com.google": {
CF1: {
C11:{
T1: good
}
C12:{
T1: good
}
CF2: {
C21:{
T1: bad
}
C22:{
T1: bad
T2:good
}
}
}
}
事实上,我们只需要在C22的object再加一个属性即可。如果我们把这个MAP翻译成表形状,也可以表示为:
|
RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
|
Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
|
“com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
|
“C12 good” |
T2 |
||||
我们发现,这个表里很多列是没有value的。想象一下,如果再加入一行RowKey不同的数据,其中Column:C11内容为空,就可以在Json中省略该属性了。
好了,扯了这么多,就是为了说明HBase是“稀疏的高阶MAP”。
为了查询效率,HBase内部对RowKey做了排序,以保证类似的或者相同的RowKey都集中在一起,于是HBase就变成了一张“稀疏的,有序的,高阶的MAP”。有没有觉得这样的表述很高冷? :)
3. 文件存储结构与进程模型
如上所述,HBase是一张“稀疏的,有序的,高阶的MAP”。
通常来说,MAP可以用B+树来实现。B+树对查询性能而言表现良好,但是对插入数据有些力不从心,尤其对于插入的数据需要持久化到磁盘的情况而言。
我们对RowKey做了排序,为了保证查询效率,我们希望将连续RowKey的数值保存在连续的磁道上,以避免大量的磁盘随机寻道。所以在插入数据时,对于B+树而言,就面临着大量的文件搬移工作。
HBase使用了LSM树实现了MAP,简单说来,就是将插入/修改操作缓存在内存中,当内存中积累足够的数据后,再以块的形式刷入到磁盘上。
HBase的进程模型:
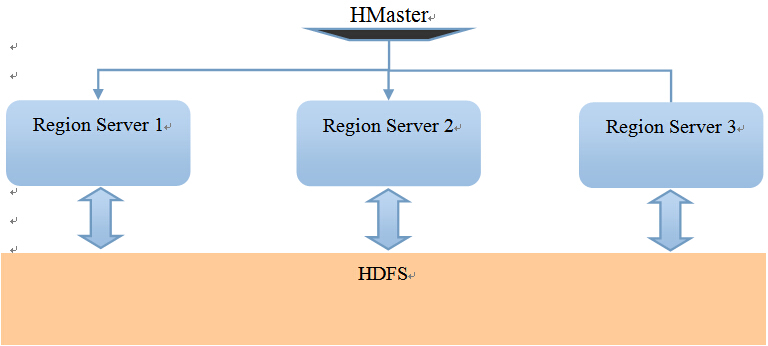
Region: 基于RowKey的分区,可理解成MySQL的水平切分。
每个Region Server就是Hadoop集群中一台机器上的一个进程。
比如我们的有1-300号的RowKey, 那么1-100号RowKey的行被分配到Region Server 1上,同样,101-200号分配到Region Server 2上, 201-300号分配到Region Server 3上。
在内存模型中,我们说RowKey保证了相邻RowKey的记录被连续地写入了磁盘。在这里,我们发现,RowKey决定了行操作(增,删,改,查)会被交与哪台Region Server操作。
让我们假设一下,如果我们的RowKey以记录的TimeStamp起始,从内存模型上说,这很合理,因为我们可能面临大量的用户流水记录查询,查询的条件会设置一个时间片段,我们希望一次性从磁盘中读取这些流水记录,从而避免频繁的磁盘寻道操作。
但是再另一方面,用户的流水记录查询会很频繁的出现“截至到至今”的查询条件,依照我们上面的进程模型,Region Server 3一定会被分配到(因为最近的记录排在最后),这样就可能造成Region Server 3的“过热”,而Region Server 1“过冷”的情况。
文件存储模型:
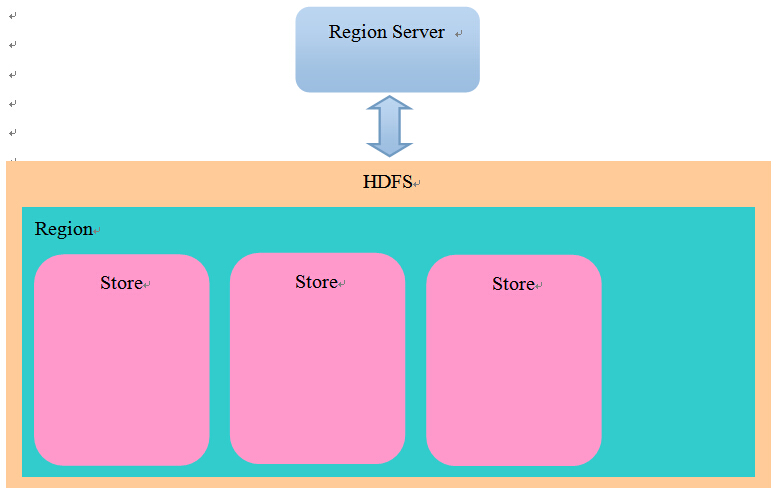
在HDFS中,每张表对应一个目录,在表目录下,每个Region对应一个目录,在Region目录下,每个Store对应一个目录(一个Store对应一个ColumFamily)。结构如下:
HBase
|
---Table
|
---XXXX(Region的hash)
| |
| ----ColumnFamily
| |
| ---文件
|
---YYYYY(另一个Region的hash)
我们的新发现是,不同的ColumnFamily对应不同的Store, 并且被写入了不同的目录, 这意味着:
1. 通过将一张表分解成了不同的ColumnFamily,HBase可以从磁盘一次读取更少的内容(IO操作往往是计算机系统中最慢的一环)。
2. 我们不应该将需要一次查询出的列,分解在不同的ColumnFamily中,否则以为着HBase不得不读取两个文件来满足查询要求。
另外,一个ColumnFamily中的每一列是连续存储的。即如果一个ColumnFamily中存在C1,C2两列,一段具有100行记录的存储格式是:
C1(1),C2(1),C1(2),C2(2),C1(3),C2(3).............C1(100),C2(100)
与其说HBase是基于列的数据库,更不如说HBase是基于“列族”的数据库。
4 理解:
基于以上的模型,大致的理解是:
1. RowKey决定了行操作任务进入RegionServer的数量,我们应该尽量的让一次操作调用更多的Region Server,已达到分布式的目的。
2. RowKey决定了查询读取连续磁盘块的数量,最理想的情况是一次查询,在每个Region Server上,只读取一个磁盘块。
3. ColumnFamily决定了一次查询需要读取的文件数(不同的文件不仅意味着分散的磁盘块,还意味着多次的文件打开关闭操作)。我们应尽量将希望查询的结果集合并到一个ColumnFamily中。同时尽量去除该ColumnFamily中不需要的列。
4. HBase官方建议尽量的减少ColumnFamily的数量。
再瞎总结一下:
1. RowKey由查询条件决定。
2. ColumnFamily由查询结果决定。
hbase概念的更多相关文章
- HBase概念及表格设计
HBase概念及表格设计 1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有 ...
- HBASE概念补充
HBASE概念补充 HBase的工作方式: hbase中的表在行的方向上分隔为多个HRegion,分散在不同的RegionServer中 这样做的目的是在查询时可以将工作量分布到多个RegionSer ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- HBase概念入门
HBase简介 HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系统,可以提供大规模数据集的实时随机读写. 下面通过一个小场景认识HBase存储.同样的一个数据 ...
- hbase 概念
在hbase里面有几个通俗的名称会经常出现 1)Hregion = region 2)Hregionserver = regionserver 3)Hmaster = master 4)Hmamsto ...
- hbase概念解析
hbase是一种nosql数据库.是一个高可靠,高性能,面向列,可伸缩,实时读取的分布式数据库. hbase一般由行键,时间戳,列族,列,表格单元,行组成. 行一般由一个行键和一个或多个具有关联关系值 ...
- HBase 概念视图
- HBASE学习笔记-初步印象
HBASE概念: HBASE是一个分布式架构的数据库,通过对数据进行多层的分块打散储存.从而改写传统数据库的储存能力和读取速度. HBASE的集群服务器: HBASE的集群主要分为Zookeeper集 ...
- 分布式数据库 HBase
原文地址:http://www.oschina.net/p/hbase/ HBase 概念 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用 ...
随机推荐
- python selenium-4自动化测试模型
1.线性测试 特点:每一个脚本都是完整且独立的,可以单独执行. 缺点:用例的开发与维护成本很高 2.模块化驱动测试 特点:把重复的操作独立成公共模块,提高测试用例的可维护性 示例:将搜索封装到func ...
- freemarker ,DEFAULT_INCOMPATIBLE_IMPROVEMENTS 找不到
一般出现这种问题的原因是,spring的版本和freemarker不匹配造成的~ nested exception is org.springframework.beans.factory.BeanC ...
- HTC Vive的定位技术
Lighthouse空间定位,chaperone系统避免实际障碍物 HTC vive所用的Lighthouse技术属于激光定位技术,Oculus Rift以及索尼PlayStation VR所用的定位 ...
- Erasure Coding(纠删码)深入分析
http://blog.sina.com.cn/s/blog_57f61b490102viq9.html 1.前言 Swift升级到2.0大版本后宣称开始支持纠删码,这其实是一个很有意义的特性,主要是 ...
- web service初探
概述:Web service是一个平台独立.低耦合的.自包含的.基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述.发布.发现.协调和配置这些应用程序,用于开发 ...
- jQuery更新
jQuery jQuery介绍 jQuery是一个轻量级的.兼容多浏览器的JavaScript库. jQuery使用户能够更方便地处理HTML Document.Events.实现动画效果.方便地进行 ...
- js中的数组操作
<!DOCTYPE HTML> <html > <head> <meta http-equiv="Content-Type" conten ...
- api 1.1构架篇
首先让其自动加载??? 在YiiBase.php里面 改写autoload方法: /** * Class autoload loader. * This method is p ...
- aspx后台代码写在前段
合并cs的代码 <%@ Page Language="C#" AutoEventWireup="true" Inherits="System.W ...
- AS3 os与version 区别 使用Capabilities类获取Flash Player的信息
AS3中flash.system.Capabilities类提供诸多静态的只读属性来描述应用程序当前所运行在的系统和运行时信息,如Flash Player,Adobe AIR,Flash Lite.通 ...