HBase的Scan
HBase的Scan和Get不同,前者获取数据是串行,后者则是并行;是不是有种大跌眼镜的感觉?
Scan有四种模式:scan,(Table)snapScan,(Table)scanMR,snapshotscanMR;前面两个是串行玩;后面两个是放置到MapReduce中玩;其中性能最好的就是SnapshotScanMR;
首先解释一下什么是snapshort,snapshot是HBase数据表元数据的一个快照,是的,不包括数据;有一点概念要建立清楚,HBase的数据的存储并不是HBase管理,而是HDFS;其实关系型数据库的存储也是OSFS管理的。HBase的设计就是一旦数据写入了,就不改变了,改变操作(update,delete)并不是修改HFile,而是填充墓碑文件而已;所以快照尤其价值,比如可以快速拷贝一个HBase表(只是拷贝表结构,重用原始表的HDFS数据)。
刚才讲的snapshot在scan里面也有应用场景,就是snapshotscan以及snapshortscanMR;注意MR的scan模式就不再是最上面提到的串行查询,而是并行查询;底层机制是Map-reduce;所以就下来而言,MR是要高的;毕竟是多个region查询。
接着,就是ScanAPI的设计:
1. 业务调用HBase Client,HBaseClient首先是查找缓存是否还有数据,如果有则返回数据;
2. 如果没有数据,则通过向RegionServer继续请求下面的100条记录;
3. 作为服务器端接收到next请求之后,将会通过查询BlockCache→HFile→Memstore流程来一行一行的返回数据。
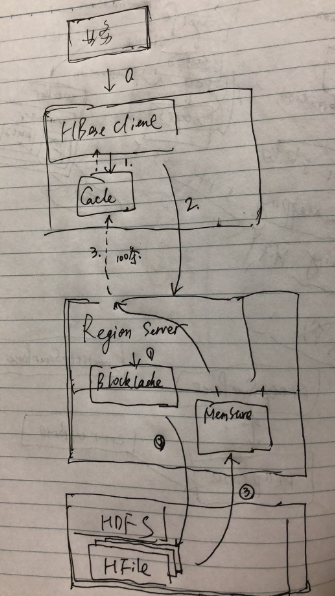
这种API的调用模式(每次返回100条)目的是避免网络资源以及HBase Client端内存资源发生压力;所以可以看到,scanAPI其实只是适合于少量数据的处理;
那么对于海量数据的查询怎么处理呢?就是上面提到的MR;MR整体分为两种:TableScanMR(对应的处理类:TableMapReduceUtil.initTableMapperJob)以及SnapshotScanMR(对应处理类:TableMapReduceUtil.initSnapshotMapperJob),下面两张图表示了在架构上面的差异:

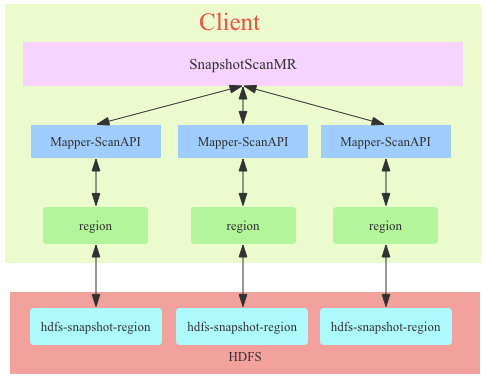
可以看到,模式很类似,都是在client中通过多线程模式进行并行处理;但是snapshotscanMR不再和region server交互,而是直接在客户端和HDFS交互;这样设计的好处即使减轻了Region Server的压力;但是需要事先和Region Server交互,获取snapshot的信息,即HBase的元数据信息(表结构以及hdfs存储信息),这样,就可以跳过region server直接和hdfs地址交互;但是snapshot有一个缺点:实时性不够;可能最近的一些数据的修改没有在snapshot中体现出来。可能会读到一些脏数据(删除更新数据仍然存在,只不过在墓碑记录而已,当然如果merge过后就没了),可能读不到一些最新数据。
参考:
http://hbasefly.com/2017/10/29/hbase-scan-3/
http://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/
HBase的Scan的更多相关文章
- Hbase 客户端Scan
Hbase 客户端Scan 标签(空格分隔): Hbase HBase扫描操作Scan 1 介绍 扫描操作的使用和get()方法类似.同样,和其他函数类似,这里也提供了Scan类.但是由于扫描工作方式 ...
- HBase shell scan 模糊查询
0.进入hbase shell ./hbase shell help help "get" #查看单独的某个命令的帮助 1. 一般命令 status 查看状态 version 查看 ...
- hbase查询,scan详解
一.shell 查询 hbase 查询相当简单,提供了get和scan两种方式,也不存在多表联合查询的问题.复杂查询需通过hive创建相应外部表,用sql语句自动生成mapreduce进行.但是这种简 ...
- HBase shell scan 过滤器用法总结
比较器: 前面例子中的regexstring:2014-11-08.*.binary:\x00\x00\x00\x05,这都是比较器.HBase的filter有四种比较器: (1)二进制比较器:如’b ...
- hbase的查询scan功能注意点(setStartRow, setStopRow)
来自http://hi.baidu.com/7636553/blog/item/982beb17713bc004972b43ee.html hbase的scan查询功能注意项: Scan scan = ...
- PySpark操作HBase时设置scan参数
在用PySpark操作HBase时默认是scan操作,通常情况下我们希望加上rowkey指定范围,即只获取一部分数据参加运算.翻遍了spark的python相关文档,搜遍了google和stackov ...
- HBase最佳实践之Scan
一.简介 HBase中Scan从大的层面来看主要有三种常见用法:ScanAPI.TableScanMR以及SnapshotScanMR.三种用法的原理不尽相同,扫描效率当然相差甚远,最重要的是这几种用 ...
- HBase scan setBatch和setCaching的区别
HBase的查询实现只提供两种方式: 1.按指定RowKey获取唯一一条记录,get方法(org.apache.hadoop.hbase.client.Get) 2.按指定的条件获取一批记录,scan ...
- HBase scan setBatch和setCaching的区别【转】
转自:http://blog.csdn.net/caoli98033/article/details/44650497 HBase的查询实现只提供两种方式: 1.按指定RowKey获取唯一一条记录,g ...
随机推荐
- Java中List的排序方法
方法一:实现Comparable接口 package com.java.test; public class Person implements Comparable<Person> { ...
- js判断数组,对象是否存在某一未知元素
1.对象 var obj = { aa:'1111', bb:'2222', cc: '3333' }; var str='aa'; if(str in obj){ console.log(obj[s ...
- echatrs可视化图在隐藏后显示不出来或是宽度出现问题
最近在做一个可视化的项目,用了百度的ECharts.js作为可视化的视图框架,echarts的实例很多,基本能满足项目的需求,而且文档也相对完整.清晰,是个很不错的前端可视化框架. 我们的项目是使用b ...
- Inno Setup 编译器操作
Inno Setup 编译器 1◆ 下载inno ha_innosetup5502_skygz_DownG.com 2◆ 安装 next 3◆ 操作 success 4◆ 测试安装 5◆ 卸载 uni ...
- POJ 3220 位运算+搜索
转载自:http://blog.csdn.net/lyhypacm/article/details/5813634 DES:相邻的两盏灯状态可以互换,给出初始状态.询问是否能在三步之内到达.如果能的话 ...
- 浅谈:当程序员的N多好处,逆袭高富师
选择一份职业,除了要要分析有没有钱途外(为什么要选择 IT 行业,IT 业有多火爆你造吗?),还要平衡其他方面的利弊.有很多想进入这个行业的小伙伴问我,程序员到底有什么好处.看样子这是很多小伙伴关心的 ...
- hibernate一对一关联
hibernate一对一主键关联 一对一主键关联指的是两个表通过主键形成的一对一映射. 数据表要求:A表的主键也是B表的主键同时B表的主键也是A表的外键 sql: create table peopl ...
- L224 词汇题
Elaborate 精心的 preparations were being made for the Prime Minister’s official visit to the four forei ...
- 将PS/2接口鼠标改造成USB接口鼠标
改造接线图 不是所有PS/2鼠标都可以改为USB鼠标的,可以改的PS/2鼠标的特征: A.早期PS/2鼠标电路板一般带有两块集成电路,(一块光电感应,一块按键或USB协议转换,和一只24M的晶体振荡器 ...
- Java中生产者与消费者模式
生产者消费者模式 首先来了解什么是生产者消费者模式.该模式也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例.该问题描述了两个共享固定大小缓冲区的线 ...