ElasticSearch 中文分词插件ik 的使用

下载
IK 的版本要与 Elasticsearch 的版本一致,因此下载 7.1.0 版本。
安装
1、中文分词插件下载地址:https://github.com/medcl/elasticsearch-analysis-ik
2、拼音分词插件下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin
下载你对应的版本

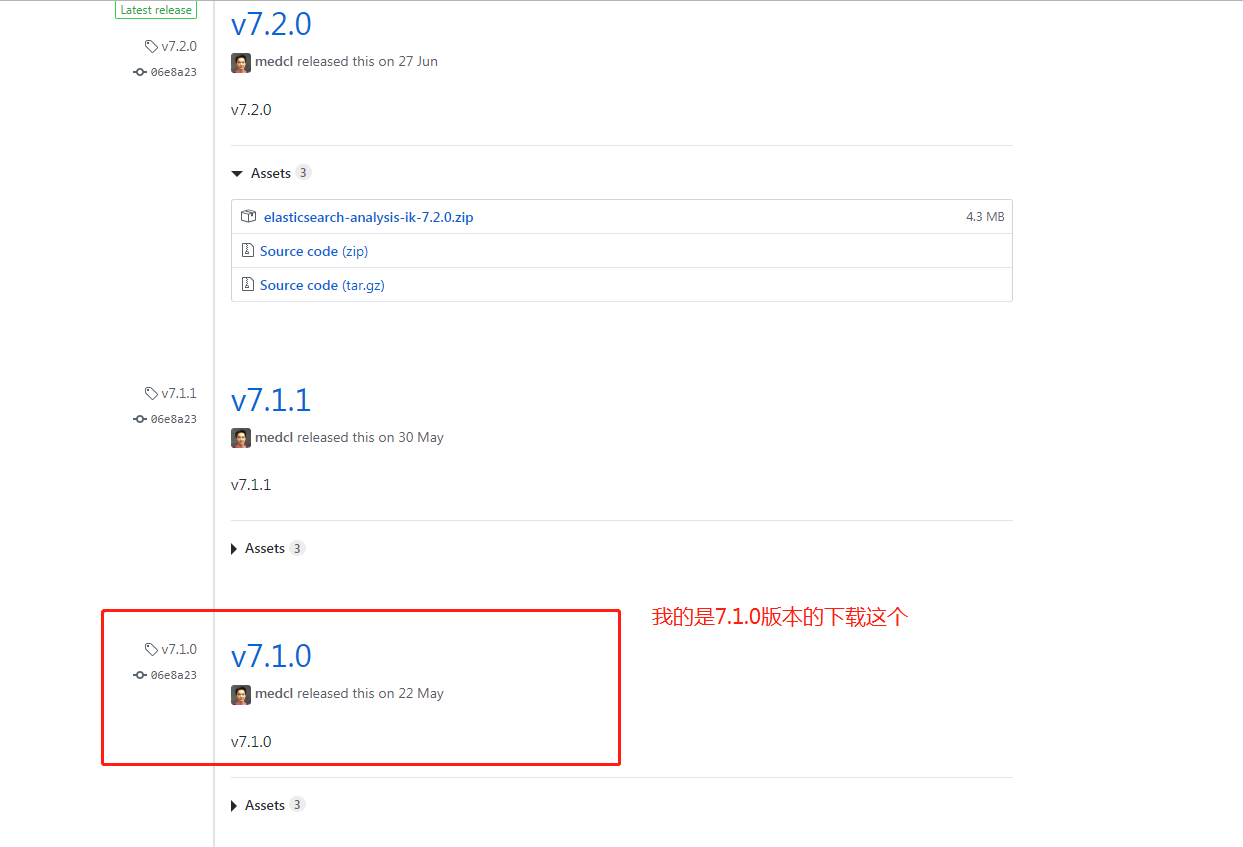
将解压后的 IK 文件夹,放入 elasticsearch 文件夹下的 plugins/ik 目录下。
启动 Elasticsearch 后,看到下图,表示启动成功。

扩展本地词库
在 plugins\ik\config\custom 目录下新增文件 hotwords.dic。如添加 洪荒之力 。每一个词语一行。
在 plugins\ik\config 文件夹下的 IKAnalyzer.cfg.xml 文件配置本地词库。
<!--用户可以在这里配置自己的扩展字典,如果多个字典,则用分号分隔 custom/mydict.dic;custom/single_word_low_freq.dic-->
<entry key="ext_dict">custom/hotwords.dic</entry>
重新启动 Elasticsearch 显示如下图,表示启动成功。

文档的中文分词使用
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
下面我们分别测试下。
先测试ik_max_word,输入命令如下:
POST http://localhost:9200/_analyze
{
"analyzer": "ik_max_word",
"text": "世界如此之大"
}
响应结果如下:
{
"tokens": [
{
"token": "世界",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "如此之",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "如此",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "之大",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
再测试ik_smart,输入命令如下:
POST http://localhost:9200/_analyze
{
"analyzer": "ik_smart",
"text": "世界如此之大"
}
响应结果如下:
{
"tokens": [
{
"token": "世界",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "如此",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "之大",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
通过Docker 安装elasticsearch-analysis-ik-6.4.5插件
FROM docker.elastic.co/elasticsearch/elasticsearch:6.4.5
ADD elasticsearch-analysis-ik-6.4.5 /usr/share/elasticsearch/plugins/elasticsearch-analysis-ik-6.4.5
ElasticSearch 中文分词插件ik 的使用的更多相关文章
- ElasticSearch(三) ElasticSearch中文分词插件IK的安装
正因为Elasticsearch 内置的分词器对中文不友好,会把中文分成单个字来进行全文检索,所以我们需要借助中文分词插件来解决这个问题. 一.安装maven管理工具 Elasticsearch 要使 ...
- ElasticSearch(四) ElasticSearch中文分词插件IK的简单测试
先来一个简单的测试 # curl -XPOST "http://192.168.9.155:9200/_analyze?analyzer=standard&pretty" ...
- Elasticsearch安装中文分词插件ik
Elasticsearch默认提供的分词器,会把每一个汉字分开,而不是我们想要的依据关键词来分词.比如: curl -XPOST "http://localhost:9200/userinf ...
- Elasticsearch如何安装中文分词插件ik
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库. 安装步骤: 1.到github网站下载源代码,网站地址为:https://github.com/medcl/ ...
- ElasticSearch中文分词(IK)
ElasticSearch常用的很受欢迎的是IK,这里稍微介绍下安装过程及测试过程. 1.ElasticSearch官方分词 自带的中文分词器很弱,可以体检下: [zsz@VS-zsz ~]$ c ...
- ElasticSearch-5.0.0安装中文分词插件IK
Install IK 源码地址:https://github.com/medcl/elasticsearch-analysis-ik,git clone下来. 1.compile mvn packag ...
- ElasticSearch中文分词器-IK分词器的使用
IK分词器的使用 首先我们通过Postman发送GET请求查询分词效果 GET http://localhost:9200/_analyze { "text":"农业银行 ...
- Elasticsearch 中文分词器IK
1.安装说明 https://github.com/medcl/elasticsearch-analysis-ik 2.release版本 https://github.com/medcl/elast ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
随机推荐
- 阿里云ESC服务器centos6.9使用及注意事项
阿里云ESC服务器,配置低,但是足够新手尝试操作练习. 使用之前,注意事项: 选择操作系统 设置实例快照 安装终端工具 一,选择操作系统. 可以在购买服务器的时候进行选择系统盘,也可以在购买之后在实例 ...
- Tornado基础学习篇
1.1 Tornado是什么? Tornado是使用Python编写的一个强大的.可扩展的Web服务器.它在处理严峻的网络流量时表现得足够强健,但却在创建和编写时有着足够的轻量级,并能够被用在大量的应 ...
- Linux——基本命令
目录 一.目录切换命令 二.目录操作命令(增删改查) 2.1增加目录 2.2查看目录 2.3寻找目录(搜索) 2.4修改目录名称 2.5移动目录位置(剪切) 2.6拷贝目录 2.7删除目录 三.文件的 ...
- Go中使用seed得到相同随机数的问题
1. 重复的随机数 废话不多说,首先我们来看使用seed的一个很神奇的现象. func main() { for i := 0; i < 5; i++ { rand.Seed(time.Now( ...
- Java基础学习笔记(四) - 认识final关键字、权限修饰符和内部类
一.final关键字 为什么要使用 final 关键字? 通过继承我们知道,子类可以重写父类的成员变量和方法.final 关键字可以用于修饰父类,父类成员变量和方法,使其内容不可以被更改. 1.被修饰 ...
- RocketMQ 源码学习笔记————Producer 是怎么将消息发送至 Broker 的?
目录 RocketMQ 源码学习笔记----Producer 是怎么将消息发送至 Broker 的? 前言 项目结构 rocketmq-client 模块 DefaultMQProducerTest ...
- MongoDB 学习笔记之 GridFS
GridFS: GridFS 是 MongoDB 的一个用来存储/获取大型数据(图像.音频.视频等类型的文件)的规范.它相当于一个存储文件的文件系统,但它的数据存储在 MongoDB 的集合中.Gri ...
- Springboot + Mysql8实现读写分离
在实际的生产环境中,为了确保数据库的稳定性,我们一般会给数据库配置双机热备机制,这样在master数据库崩溃后,slave数据库可以立即切换成主数据库,通过主从复制的方式将数据从主库同步至从库,在业务 ...
- texlive支持中文的简单方法
1.确保tex文件的编码方式是UTF-8, 2.在文档开始处添加一行命令即可,即 \usepackage[UTF8]{ctex} , 如下所示: \documentclass{article} \us ...
- Android Studio 优秀插件:GsonFormat
作为一个Android程序猿,当你看到后台给你的json数据格式时: { "id":123, "url": "http://img.donever.c ...