python做单因素方差分析
方差分析的主要功能就是验证两组样本,或者两组以上的样本均值是否有显著性差异,即均值是否一样。
这里有两个大点需要注意:①方差分析的原假设是:样本不存在显著性差异(即,均值完全相等);②两样本数据无交互作用(即,样本数据独立)这一点在双因素方差分析中判断两因素是否独立时用。
原理:
方差分析的原理就一个方程:SST=SS组间+SSR组内 (全部平方和=组间平方和+组内平方和)
说明:方差分析本质上对总变异的解释。
- 组间平方和=每一组的均值减去样本均值
- 组内平方和=个体减去每组平方和
方差分析看的最终结果看的统计量是:F统计量、R2。
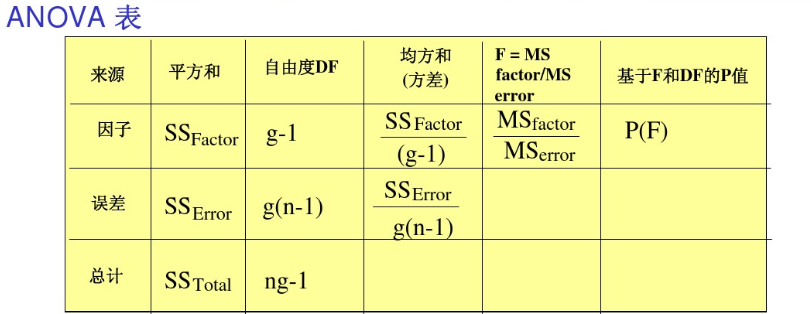
其中:g为组别个数,n为每个组内数据长度。
python实现:
from scipy import stats
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
from statsmodels.stats.multicomp import pairwise_tukeyhsd
import warnings
warnings.filterwarnings("ignore") import itertools df2=pd.DataFrame()
df2['group']=list(itertools.repeat(-1.,9))+ list(itertools.repeat(0.,9))+list(itertools.repeat(1.,9)) df2['noise_A']=0.0
for i in data['A'].unique():
df2.loc[df2['group']==i,'noise_A']=data.loc[data['A']==i,['','','']].values.flatten() df2['noise_B']=0.0
for i in data['B'].unique():
df2.loc[df2['group']==i,'noise_B']=data.loc[data['B']==i,['','','']].values.flatten() df2['noise_C']=0.0
for i in data['C'].unique():
df2.loc[df2['group']==i,'noise_C']=data.loc[data['C']==i,['','','']].values.flatten() df2

# for A
anova_reA= anova_lm(ols('noise_A~C(group)',data=df2[['group','noise_A']]).fit())
print(anova_reA)
#B
anova_reB= anova_lm(ols('noise_B~C(group)',data=df2[['group','noise_B']]).fit())
print(anova_reB)
#C
anova_reC= anova_lm(ols('noise_C~C(group)',data=df2[['group','noise_C']]).fit())
print(anova_reC)

从结果可以看出,A、B两样本,在每个组间均值显著无差异,C样本的组间均值是有差异的。
python做单因素方差分析的更多相关文章
- 用Python学分析 - 单因素方差分析
单因素方差分析(One-Way Analysis of Variance) 判断控制变量是否对观测变量产生了显著影响 分析步骤 1. 建立检验假设 - H0:不同因子水平间的均值无差异 - H1:不同 ...
- Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里: Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图 本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析. 依赖库: 豆瓣镜像比较快: ...
- Python:用pyinstrument做性能分析
导引 在计算密集型计算或一些Web应用中,我们常常需要对代码做性能分析.在Python中,最原始的方法即是使用time包中的time函数(该函数以秒为计时单位): from time import s ...
- Python文章相关性分析---金庸武侠小说分析
百度到<金庸小说全集 14部>全(TXT)作者:金庸 下载下来,然后读取内容with open('names.txt') as f: data = [line.strip() for li ...
- 使用Python做简单的字符串匹配
由于需要在半结构化的文本数据中提取一些特定格式的字段.数据辅助挖掘分析工作,以往都是使用Matlab工具进行结构化数据处理的建模,matlab擅长矩阵处理.结构化数据的计算,Python具有与matl ...
- 一步一步教你如何用Python做词云
前言 在大数据时代,你竟然会在网上看到的词云,例如这样的. 看到之后你是什么感觉?想不想自己做一个? 如果你的答案是正确的,那就不要拖延了,现在我们就开始,做一个词云分析图,Python是一个当下很流 ...
- 用python探索和分析网络数据
Edited by Markdown Refered from: John Ladd, Jessica Otis, Christopher N. Warren, and Scott Weingart, ...
- What exactly can you do with Python? Here are Python’s 3 main applications._你能用Python做什么?下面是Python的3个主要应用程序。
原文链接 Github地址 一.陈述 1,我到底能用Python做什么? 我观察注意到Python三个主要流行的应用: 网站开发: 数据科学——包括机器学习,数据分析和数据可视化: 做脚本语言. 二. ...
- [转]使用 mitmproxy + python 做拦截代理
使用 mitmproxy + python 做拦截代理 本文是一个较为完整的 mitmproxy 教程,侧重于介绍如何开发拦截脚本,帮助读者能够快速得到一个自定义的代理工具. 本文假设读者有基本的 ...
随机推荐
- jvm与程序的生命周期
yls 2019/11/5 java虚拟机结束生命周期的情况: 执行了System.exit(); 程序正常运行结束 程序在执行过程中遇到异常或错误而异常终止 由于操作系统出现错误而导致jvm进程终止 ...
- Spring Bean的定义及作用域
目录: 了解Spring的基本概念 Spring简单的示例 Bean的定义 简单地说Bean是被Spring容器管理的Java对象,Spring容器会自动完成对Bean的实例化. 那么什么是容器呢?如 ...
- 心里有点B树
在说B树之前最好先看看2-3树, 2-3树是B树的一种特例, 什么B树, B树就是2-3树, 2-3-4 树 , 2-3-4-5... 树的统称, 而B+树又是B树的一种变形 性质: 什么是二节点, ...
- hdu 1874 畅通工程续 (dijkstra(不能用于负环))
畅通工程续Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- 领扣(LeetCode)单词模式 个人题解
给定一种 pattern(模式) 和一个字符串 str ,判断 str 是否遵循相同的模式. 这里的遵循指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向 ...
- django_0:项目流程
1.django-admin(.py) startproject mysite——创建项目project 得到__init__.py(说明工程以包结构存在) settings.py(当前工程的一些配置 ...
- 页面加载和图片加载loading
准备放假了!也是闲着了 ,就来整理之前学到或用到的一下知识点和使用内容,这次记录的是关于加载的友好性loading!!!这里记录一下两种加载方法 1.页面加载的方法,它需要用到js里面两个方法 doc ...
- 【Linux系列】Centos 7安装 Redis(六)
目的 本文主要介绍以下两点: 一. 安装Redis 二. 设置开机启动项 演示 一. 安装Redis 打开Redis官网,右击复制链接. yum install -y gcc # 先更新下编译环境 c ...
- 以太网驱动的流程浅析(一)-Ifconfig主要流程【原创】
以太网驱动的流程浅析(一)-Ifconfig主要流程 Author:张昺华 Email:920052390@qq.com Time:2019年3月23日星期六 此文也在我的个人公众号以及<Lin ...
- MySQL5.6.36 自动化安装脚本
背景 很好的朋友邱启明同学,擅长MySQL,目前任职某大型互联网业MySQL DBA,要来一套MySQL自动安装的Shell脚本,贴出来保存一些. 此版本为 MySQL 5.6.365 ###### ...