GAN算法笔记
本篇文章为Goodfellow提出的GAN算法的开山之作"Generative Adversarial Nets"的学习笔记,若有错误,欢迎留言或私信指正。
1. Introduction
GAN模型解决的问题
作者在首段指出了本课题的意义——能够避免深度生成模型中的两个局限性:
(1)最大似然估计等相关策略中难以处理的概率计算;
(2)在生成环境中难以利用分段线性单元的优势。
PS:深度生成模型是为了从原始的样本数据中模拟出数据分布,进而产生符合这一分布的新的样本。
GAN模型的构成
GAN模型主要分为两个部分:生成模型\(G\)(generative model)和判别模型\(D\)(discriminative model)。作者将这两个部分的关系类比为假币制造商和警察。判别模型(警察)来判断一个样本究竟是来自于数据分布还是模型分布,而生成模型(假币制造商)则是为了生成假的样本来骗过判别模型(警察)。这样产生的竞争驱使两方都不断更新自己的方法,直到假样本与真样本完全无法区分。框架中的生成模型通过将随机噪声输入多层感知机进而得到假样本,而判别模型则是将样本输入多层感知机来判断样本是否为真实样本。作者指出,同时训练这两个模型的方法是使用反向传播算法(backpropagation algorithm)和丢弃算法(应该是“随机失活算法”,之前表述有所错误)(dropout algorithm)。
ps:多层感知机(Multi Layer Perceptron) 为如下图所示的包括至少一个隐藏层(除去一个输入层和一个输出层以外)的多层神经元网络。
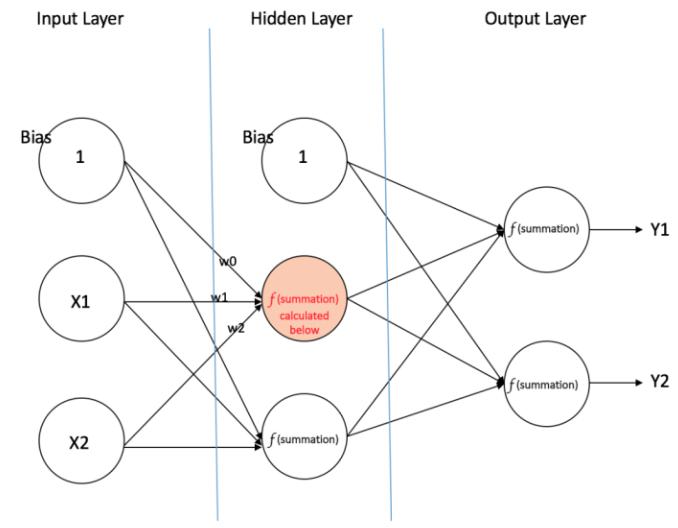
2. Related work
作者在这一部分介绍了有关深度生成网络的相关工作,由于还没有系统掌握深度学习,暂且跳过。。。
3. Adversarial nets
作者定义了两个函数:
- \(G\left(\boldsymbol{z} ; \theta_{g}\right)\)表示从噪音\(\boldsymbol{z}\)到数据样本空间的映射函数,其中\(\theta_{g}\)表示多层感知机的参数。
- \(D(\boldsymbol{x};\theta_d)\)表示对于输入样本\(\boldsymbol{x}\)输出判断为真实数据的概率(为一个标量)
GAN的目标
作者将GAN的目标定义为下面这个优化公式:
\]
这个公式由两部分构成,前一部分 \(\mathbb{E}_{\mathbf{x}\sim p_{data}(x)}[\log D(x)]\) 可以理解为判别模型正确判定真实数据的对数期望,后一部分\(\mathbb{E}_{\mathbf{z}\sim p_z}[\log (1-D(G(z)))]\)可以理解为判别模型正确识别假样本的对数期望。
相对熵?
后面重新看这个公式的时候突然想到一个问题:为什么公式中求期望时要在概率值的外面再套一个log函数呢?
还没有完全想明白,感觉有点像是交叉熵和相对熵的概念,但是又无法将上述公式和相对熵的公式定义一一对应起来。
可以先可以参考这个链接:机器学习中的各种“熵”(这个博客页面是真的卡)
后面作者在Theoretical Results部分果然用到了交叉熵的概念,用来证明这个公式的目标就是实现\(p_g=p_{data}\)
图形理解
下面这张图我看了一晚上没看懂,今天早上才明白是什么意思。
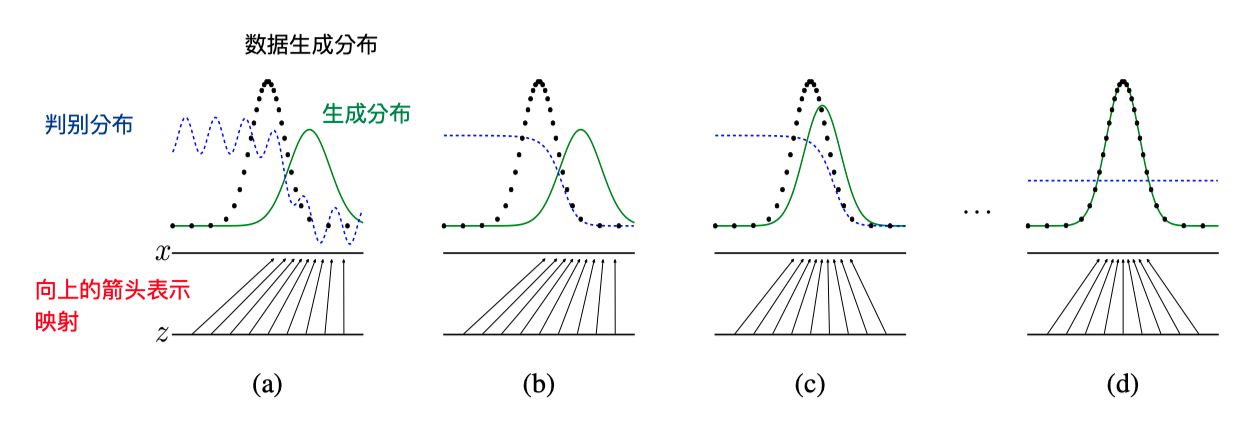
图中蓝色的虚线表示判别模型的概率分布,黑色的点线表示原始数据的概率分布,绿色实线表示生成模型的生成概率分布。
- 图(a)中表示训练还未开始或刚开始一段时间时,判别模型和生成模型都还没有经过大量的训练,因此判别概率分布还有些波动,生成分布距离真实数据生成分布还有不小的距离。
- 图(b)表示经过一段时间的训练后,判别模型可以较好的判别出原始样本和生成样本,蓝色虚线的高度表示当前位置对应横坐标的样本为真实数据样本的概率,越高表示为真实样本的概率越大。
- 图(c)表示继续训练一段时间之后,原始样本和生成样本更加接近,判别模型还是有相对不错的判别效果。
- 图(d)表示经过足够的训练之后,原始样本与生成样本的概率分布特征基本一致,判别模型失去判别效果。
算法1
算法1原文描述
算法1中文python伪代码描述(这是个什么鬼东西)
for i in range(训练的迭代次数)):
for j in range(k步):
从噪音分布中取出m个噪音样本
从数据分布中取出m个样本
利用随机梯度上升法更新判别器D
从噪音分布中取出m个噪音样本
利用随机梯度下降法更新生成器G
4. Theoretical Results
全局最优\(p_g=p_{data}\)
作者给出了第一个命题:当生成模型\(G\)固定时,最优判别器为:$$D^*G(x)=\frac{p{data}(x)}{p_{data}(x)+p_g(x)}$$
并且作者也给出了证明,证明的思路很简单,形如\(y \rightarrow a \log (y)+b \log (1-y)\)的式子在\([0,1]\)区间内有固定的最大值为\(\frac{a}{a+b}\)。
这样一来,原公式就可以替换成下式:
\]
再利用KL散度(相对熵)公式:
\]
可以将刚刚的式子替换为
\]
进一步可以利用JS散度公式进行替换:
\]
由JS散度公式的性质——即取值范围为\([0,1]\)因此可知\(C(G)\)的最小值为\(-\log (4)\),此时JS散度公式取0,并且此时唯一解为\(p_g=p_{data}\)
5. Experiments
6. Advantages and disadvantages
作者指出,生成式对抗网络有以下四个优势:
- 根据实验结果来看,比其他模型产生了更锐利、清晰的样本。
- 生成式对抗网络能够被用来训练任何一种生成器网络。
- 不需要设计遵循任何种类的因式分解的模型。
- 无需利用马尔可夫链反复采样,回避了棘手的近似计算的概率问题。
GAN目前存在的主要问题是:
- 解决不收敛的问题
GAN算法笔记的更多相关文章
- 学习Java 以及对几大基本排序算法(对算法笔记书的研究)的一些学习总结(Java对算法的实现持续更新中)
Java排序一,冒泡排序! 刚刚开始学习Java,但是比较有兴趣研究算法.最近看了一本算法笔记,刚开始只是打算随便看看,但是发现这本书非常不错,尤其是对排序算法,以及哈希函数的一些解释,让我非常的感兴 ...
- 算法笔记--数位dp
算法笔记 这个博客写的不错:http://blog.csdn.net/wust_zzwh/article/details/52100392 数位dp的精髓是不同情况下sta变量的设置. 模板: ]; ...
- 算法笔记--lca倍增算法
算法笔记 模板: vector<int>g[N]; vector<int>edge[N]; ][N]; int deep[N]; int h[N]; void dfs(int ...
- 算法笔记--STL中的各种遍历及查找(待增)
算法笔记 map: map<string,int> m; map<string,int>::iterator it;//auto it it = m.begin(); whil ...
- 算法笔记--priority_queue
算法笔记 priority_queue<int>que;//默认大顶堆 或者写作:priority_queue<int,vector<int>,less<int&g ...
- 算法笔记--sg函数详解及其模板
算法笔记 参考资料:https://wenku.baidu.com/view/25540742a8956bec0975e3a8.html sg函数大神详解:http://blog.csdn.net/l ...
- 算法笔记——C/C++语言基础篇(已完结)
开始系统学习算法,希望自己能够坚持下去,期间会把常用到的算法写进此博客,便于以后复习,同时希望能够给初学者提供一定的帮助,手敲难免存在错误,欢迎评论指正,共同学习.博客也可能会引用别人写的代码,如有引 ...
- 算法笔记_067:蓝桥杯练习 算法训练 安慰奶牛(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 Farmer John变得非常懒,他不想再继续维护供奶牛之间供通行的道路.道路被用来连接N个牧场,牧场被连续地编号为1到N.每一个牧场都是 ...
- 算法笔记(c++)--回文
算法笔记(c++)--回文 #include<iostream> #include<algorithm> #include<vector> using namesp ...
随机推荐
- Codeforces Technocup 2017 - Elimination Round 2 E Subordinates(贪心)
题目链接 http://codeforces.com/contest/729/problem/E 题意:给你n个人,主管id为s,然后给你n个id,每个id上对应一个数字表示比这个人大的有几个. 最后 ...
- yzoj1985 最长公共单调上升子序列 题解
题面给两个序列a,b长度分别为n,m求最长公共上升子序列,百度了一下求公共子序列的问题好像叫做LCS,而上升的叫做LCIS.都是dp的例题. 先来说说最长公共子序列,这是一道比较经典的dp题,我们可以 ...
- Erlang模块gen_fsm翻译
模块摘要 通用有限状态机行为. 描述 用于实现有限状态机的行为模块.使用该模块实现的通用有限状态机进程(gen_fsm)将具有一组标准的接口函数,并包括用于跟踪和错误报告的功能.它 ...
- 获取mysql自主生成的主键
一.sql语句 CREATE TABLE `testgeneratedkeys` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) ...
- 自荐RedisViewer一个有情怀的跨平台Redis可视化客户端工具
自荐一个有情怀的跨平台Redis可视化客户端工具--RedisViewer 转载自 最美分享Coder 2019-09-17 06:31:00 介绍 在以往的文章中曾经介绍过几款Redis的可视化工具 ...
- Nginx 的三大功能
1.HTTP服务器 Nginx是一个HTTP服务器,可以将服务器上的静态文件(如HTML.图片)通过HTTP协议展现给客户端. 2.反向代理服务器 Nginx也是反向代理服务器. 说反向代理之前先说一 ...
- SpringBoot启动zipkin-server报错Error creating bean with name ‘armeriaServer’ defined in class path resource
目前,GitHub 上最新 release 版本是 Zipkin 2.12.9,从 2.12.6 版本开始有个较大的更新,迁移使用 Armeria HTTP 引擎. 从此版本开始,若直接添加依赖的 S ...
- 使用Nexus3搭建Maven私服
1.搭建Maven私服背景 公司还是按捺不住,要搭建一个自己的Maven本地仓库,可以让开发人员down架包,从内网还是快很多. 这样公司的maven本地仓库就是 开发人员自己电脑上的maven仓库 ...
- (intellij ieda激活码、CLion激活码、php storm激活码、webstorm激活码、jetbrains全家桶激活码)
中华民族传统美德 下载地址 https://www.jetbrains.com/zh/phpstorm/promo/?utm_source=baidu&utm_medium=cpc&u ...
- SPSS基础学习方差分析—单因素分析
为什么要进行方差分析? 单样本.两样本t检验其最终目的都是分析两组数据间是否存在显著性差异,但如果要分析多组数据间是否存在显著性差异就很困难,因此用方差分析解决这个问题:举例:t检验可以分析一个班男女 ...