工作中遇到的99%SQL优化,这里都能给你解决方案(二)
-- 示例表
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(20) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=136326 DEFAULT CHARSET=utf8 COMMENT='员工表'
Order by与Group by优化
EXPLAIN select * from employees WHERE name='LiLei' and position='dev' order by age;

利用最左前缀法则:中间字段不能断,因此查询用到了name索引,从key_len=74也能看出,age索引列用在排序的过程中,因为Extra字段里没有using filesort。
EXPLAIN select * from employees WHERE name='LiLei' order by position;

从explain的执行结果来看:key_len=74, 查询使用name索引,由于用了position进行排序,跳过了age,出现了Using filesort。
EXPLAIN select * from employees WHERE name='LiLei' order by age,position;

查找只用到了name索引,age和position用于排序,无Using filesort。
EXPLAIN select * from employees WHERE name='LiLei' order by position,age;

和上一个case不同的是,Extra中出现了Using filesort,因为索引的创建顺序为name,age,position,但是排序的时候age和position颠倒了位置。
EXPLAIN select * from employees WHERE name='LiLei' order by age asc, position desc;

虽然排序的字段和联合索引顺序是一样的,且order by是默认升序,这里position desc是降序,导致与索引的排序方式不同,从而产生Using filesort。Mysql8以上版本有降序索引可以支持该种查询方式。
EXPLAIN select * from employees WHERE name in('LiLei', 'zhuge') order by age, position ;

对于排序来说,多个相等条件也是范围查询。
EXPLAIN select * from employees WHERE name > 'a' order by name;
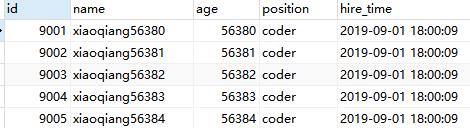
可以用覆盖索引优化
EXPLAIN select name,age,position from employees WHERE name > 'a' order by name;

filesort排序
EXPLAIN select * from employees where name='LiLei' order by position;

查看这条sql对应trace结果(只展示排序部分):
set session optimizer_trace="enabled=on",end_markers_in_json=on; ‐‐开启trace
select * from employees where name = 'LiLei' order by position;
select * from information_schema.OPTIMIZER_TRACE;
{
"join_execution": { --sql执行阶段
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": { --文件排序信息
"rows": 1, --预计扫描行数
"examined_rows": 1, --参与排序的行
"number_of_tmp_files": 0, --使用临时文件的个数,这个值为0代表全部使用sort_buffer内存排序,否则使用磁盘文件排序
"sort_buffer_size": 200704, --排序缓存的大小
"sort_mode": "<sort_key, additional_fields>" --排序方式,这里用的单路排序
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
修改max_length_for_sort_data=10
set max_length_for_sort_data = 10; --employees表所有字段长度总和肯定大于10字节
select * from employees where name = 'LiLei' order by position;
select * from information_schema.OPTIMIZER_TRACE;
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": {
"rows": 1,
"examined_rows": 1,
"number_of_tmp_files": 0,
"sort_buffer_size": 53248,
"sort_mode": "<sort_key, rowid>" --排序方式为双路排序
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
}
对比这两个排序模式,单路排序会把所有的需要查询的字段数据都放到sort_buffer中,而双路排序只会把主键id和需要排序的字段放到sort_buffer中进行排序,然后再通过主键id 回到原表 查询需要的字段数据。MySQL通过max_length_for_sort_data这个参数来控制排序,在不同场景下使用不同的排序模式,从而提升排序效率。
优化总结
- Mysql支持两种方式的排序filesort和index,using index是指Mysql扫描索引本身完成排序。index效率高,filesort效率低。
- order by满足两种情况会使用using index。
order by语句使用索引最左前列。
使用where子句和order by子句 条件列组合满足索引最左前列。 - 尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时候的最左前缀法则。
- 如果order by 的条件不在索引列上,就会产生using filesort。
还没关注我的公众号?
- 扫文末二维码关注公众号【小强的进阶之路】可领取如下:
- 学习资料: 1T视频教程:涵盖Javaweb前后端教学视频、机器学习/人工智能教学视频、Linux系统教程视频、雅思考试视频教程;
- 100多本书:包含C/C++、Java、Python三门编程语言的经典必看图书、LeetCode题解大全;
- 软件工具:几乎包括你在编程道路上的可能会用到的大部分软件;
- 项目源码:20个JavaWeb项目源码。

工作中遇到的99%SQL优化,这里都能给你解决方案(二)的更多相关文章
- 工作中遇到的99%SQL优化,这里都能给你解决方案
前几篇文章介绍了mysql的底层数据结构和mysql优化的神器explain.后台有些朋友说小强只介绍概念,平时使用还是一脸懵,强烈要求小强来一篇实战sql优化,经过周末两天的整理和总结,sql优化实 ...
- 工作中遇到的99%SQL优化,这里都能给你解决方案(三)
-- 示例表 CREATE TABLE `employees` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(24) NOT NULL ...
- 收集一些工作中常用的经典SQL语句
作为一枚程序员来说和数据库打交道是不可避免的,现收集一下工作中常用的SQL语句,希望能给大家带来一些帮助,当然不全面,欢迎补充! 1.执行插入语句,获取自动生成的递增的ID值 INSERT INTO ...
- 在工作中常用到的SQL
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 最近在公司做了几张报表,还记得刚开始要做报表的时候都 ...
- 工作中常用到的sql命令!!!
一.mysql数据库日常操作. 1.启动mysql:/etc/init.d/mysql start (前面为mysql的安装路径) 2.重启mysql: /etc/init.d/my ...
- 工作中遇到的一道SQL应用题
登录日志表 CREATE TABLE [dbo].[LoginLog]([Seq] [int] NOT NULL IDENTITY(1, 1), --Seq[UserId] [varchar] (2 ...
- 分享一个工作中遇得到的sql(按每天每人统计拖车次数与小修次数)
查询每人每天的数据 首先先建表 CREATE TABLE `user` ( `name` ) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CR ...
- 《高性能SQL调优精要与案例解析》一书谈SQL调优(SQL TUNING或SQL优化)学习
<高性能SQL调优精要与案例解析>一书上市发售以来,很多热心读者就该书内容及一些具体问题提出了疑问,因读者众多外加本人日常工作的繁忙 ,在这里就SQL调优学习进行讨论并对热点问题统一作答. ...
- Oracle SQl优化总结
对数据库技术的热爱是我唯一的安慰,毕竟这是自己喜欢的事情,还可以做下去. 因为客户项目的需要,我又开始接触Oracle,大部分工作在工作流的优化和业务数据的排查上.为了更好的做这份工作,我有参考过or ...
随机推荐
- 【React踩坑记四】React项目中引入并使用js-xlsx上传插件(结合antdesign的上传组件)
最近有一个前端上传并解析excel/csv表格数据的需求. 于是在github上找到一个14K star的前端解析插件 github传送门 官方也有,奈何实在太过于浅薄.于是做了以下整理,避免道友们少 ...
- python_Tensorflow学习(三):TensorFlow学习基础
一.矩阵的基本操作 import tensorflow as tf # 1.1矩阵操作 sess = tf.InteractiveSession() x = tf.ones([2, 3], &qu ...
- excel 导入 下载模板 demo
import org.apache.commons.beanutils.PropertyUtils;import org.apache.commons.lang3.StringUtils;import ...
- Jersey用户指南学习笔记1
Jersey用户指南是Jersey的官方文档, 英文原版在这:https://jersey.github.io/documentation/latest/index.html 中文翻译版在这:http ...
- 鲜为人知的maven标签解说
目录 localRepository interactiveMode offline pluginGroups proxies servers mirrors profiles 使用场景 出现位置 激 ...
- vue+element搭建后台管理界面(支持table条件搜索)
代码地址(如果有帮助,请点个Star) vue:https://github.com/wwt729/ElementUIAdmin-master.git springboot后端:https://git ...
- docker配置国内镜像地址
docker的官方镜像站被大天朝强了,今天发现阿里有镜像加速这个功能,目前好像是在公测中,废话不多说,接下来告诉你怎么操作. 点击进入阿里镜像库 https://cr.console.aliyun.c ...
- cs231n---语义分割 物体定位 物体检测 物体分割
1 语义分割 语义分割是对图像中每个像素作分类,不区分物体,只关心像素.如下: (1)完全的卷积网络架构 处理语义分割问题可以使用下面的模型: 其中我们经过多个卷积层处理,最终输出体的维度是C*H*W ...
- Fabric项目学习总结
1.Hyperledger Fabric的基本架构 2.PKI机制
- Cocos2d-x 学习笔记(3.2) TransitionScene 过渡场景和场景切换的过程
1. 简介 过渡场景TransitionScene直接继承了场景Scene.能够在场景切换过程中实现“过渡”效果,而不是让窗口在下一帧突然展示另一个场景. 2. create 构造函数: Transi ...