聚类——密度聚类DBSCAN
Clustering 聚类
密度聚类——DBSCAN
前面我们已经介绍了两种聚类算法:k-means和谱聚类。今天,我们来介绍一种基于密度的聚类算法——DBSCAN,它是最经典的密度聚类算法,是很多算法的基础,拥有很多聚类算法不具有的优势。今天,小编就带你理解密度聚类算法DBSCAN的实质。
DBSCAN
基础概念
作为最经典的密度聚类算法,DBSCAN使用一组关于“邻域”概念的参数来描述样本分布的紧密程度,将具有足够密度的区域划分成簇,且能在有噪声的条件下发现任意形状的簇。在学习具体算法前,我们先定义几个相关的概念:
邻域:对于任意给定样本x和距离ε,x的ε邻域是指到x距离不超过ε的样本的集合;
核心对象:若样本x的ε邻域内至少包含minPts个样本,则x是一个核心对象;
密度直达:若样本b在a的ε邻域内,且a是核心对象,则称样本b由样本x密度直达;
密度可达:对于样本a,b,如果存在样例p1,p2,...,pn,其中,p1=a,pn=b,且序列中每一个样本都与它的前一个样本密度直达,则称样本a与b密度可达;
密度相连:对于样本a和b,若存在样本k使得a与k密度可达,且k与b密度可达,则a与b密度相连。
光看文字是不是绕晕了?下面我们用一个图来简单表示上面的密度关系: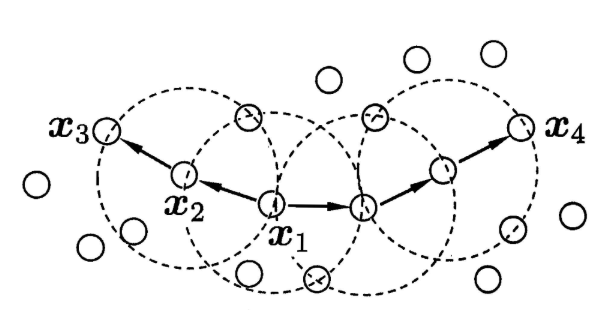
当minPts=3时,虚线圈表示ε邻域,则从图中我们可以观察到:
x1是核心对象;
x2由x1密度直达;
x3由x1密度可达;
x3与x4密度相连。
为什么要定义这些看上去差不多又容易把人绕晕的概念呢?其实ε邻域使用(ε,minpts)这两个关键的参数来描述邻域样本分布的紧密程度,规定了在一定邻域阈值内样本的个数(这不就是密度嘛)。那有了这些概念,如何根据密度进行聚类呢?
DBSCAN聚类思想
DBSCAN聚类的原理很简单:由密度可达关系导出最大密度相连的样本集合(聚类)。这样的一个集合中有一个或多个核心对象,如果只有一个核心对象,则簇中其他非核心对象都在这个核心对象的ε邻域内;如果是多个核心对象,那么任意一个核心对象的ε邻域内一定包含另一个核心对象(否则无法密度可达)。这些核心对象以及包含在它ε邻域内的所有样本构成一个类。
那么,如何找到这样一个样本集合呢?一开始任意选择一个没有被标记的核心对象,找到它的所有密度可达对象,即一个簇,这些核心对象以及它们ε邻域内的点被标记为同一个类;然后再找一个未标记过的核心对象,重复上边的步骤,直到所有核心对象都被标记为止。
算法的思想很简单,但是我们必须考虑一些细节问题才能产出一个好的聚类结果:
- 首先对于一些不存在任何核心对象邻域内的点,再DBSCAN中我们将其标记为离群点(异常);
- 第二个是距离度量,如欧式距离,在我们要确定ε邻域内的点时,必须要计算样本点到所有点之间的距离,对于样本数较少的场景,还可以应付,如果数据量特别大,一般采用KD树或者球树来快速搜索最近邻,不熟悉这两种方法的同学可以找相关文献看看,这里不再赘述;
- 第三个问题是如果存在样本到两个核心对象的距离都小于ε,但这两个核心对象不属于同一个类,那么该样本属于哪一个类呢?一般DBSCAN采用先来后到的方法,样本将被标记成先聚成的类。
DBSCAN算法流程

DBSCAN算法小结
之前我们学过了kmeans算法,用户需要给出聚类的个数k,然而我们往往对k的大小无法确定。DBSCAN算法最大的优势就是无需给定聚类个数k,且能够发现任意形状的聚类,且在聚类过程中能自动识别出离群点。那么,我们在什么时候使用DBSCAN算法来聚类呢?一般来说,如果数据集比较稠密且形状非凸,用密度聚类的方法效果要好一些。
DBSCAN算法优点:
不需要事先指定聚类个数,且可以发现任意形状的聚类;
对异常点不敏感,在聚类过程中能自动识别出异常点;
聚类结果不依赖于节点的遍历顺序;
DBSCAN缺点:
对于密度不均匀,聚类间分布差异大的数据集,聚类质量变差;
样本集较大时,算法收敛时间较长;
调参较复杂,要同时考虑两个参数;
小结:
基于密度的聚类算法是广为使用的算法,特别是对于任意形状聚类以及存在异常点的场景。上面我们也提到了DBSCAN算法的缺点,但是其实很多研究者已经在DBSCAN的基础上做出了改进,实现了多密度的聚类,针对海量数据的场景,提出了micro-cluster的结构来表征距离近的一小部分点,减少存储压力和计算压力...还有很多先进的密度聚类算法及其应用,相信看完这篇文章再去读相关的论文会比较轻松。

扫码关注
获取有趣的算法知识


聚类——密度聚类DBSCAN的更多相关文章
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- DBSCAN密度聚类
1. 密度聚类概念 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密 ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- 【转】DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 31(1).密度聚类---DBSCAN算法
密度聚类density-based clustering假设聚类结构能够通过样本分布的紧密程度确定. 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得 ...
- 密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
随机推荐
- UVa12105 越大越好
题文:https://vjudge.net/problem/12364(或者见紫书) 题解: 因为题目中有两个限制条件,那么我们就顺着题目的意思来dp,设dp[i][j]表示目前还剩下的i个火柴,用这 ...
- 快速入门Maven(三)
一.整合ssh框架的Maven项目 1.传递依赖 只添加了一个struts2-core依赖,发现项目中出现了很多jar, 这种情况叫 依赖传递 2.依赖版本冲突的解决 (1)第一声明优先原则(就是谁写 ...
- Windows SDK version 8.1 下载地址
Windows SDK version 8.1 下载地址 https://go.microsoft.com/fwlink/p/?LinkId=323507
- Pycharm 常用快捷键大全
Pycharm 常用快捷键 常用快捷键 快捷键 功能 Ctrl + Q 快速查看文档 Ctrl + F1 显示错误描述或警告信息 Ctrl + / 行注释(可选中多行) Ctrl + Alt + L ...
- Tomcat源码分析三:Tomcat启动加载过程(一)的源码解析
Tomcat启动加载过程(一)的源码解析 今天,我将分享用源码的方式讲解Tomcat启动的加载过程,关于Tomcat的架构请参阅<Tomcat源码分析二:先看看Tomcat的整体架构>一文 ...
- Dell R720 RAID配置
Dell服务器上一般都带有Raid卡,Raid5配置请看下边,亲们 1. 将服务器接上电源,显示器,键盘,并开机 2. 按 ctrl + R进入Raid设置 3. 将光标放置在Raid卡那,按F2,选 ...
- Java代码优化建议
总结日常Java开发常见优化策略,持续更新. 尽可能使用局部变量 调用方法时传递的参数以及在调用中创建的临时变量都保存在栈中,速度较快,其他变量,如静态变量.实例变量等,都在堆中创建,速度较慢.另外, ...
- ESP8266开发之旅 网络篇⑧ SmartConfig——一键配网
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
- CentOS6.6-MySQL报Curses library not found
cmake . -DCMAKE_INSTALL_PREFIX=/application/mysql-5.6.40 \> -DMYSQL_DATADIR=/application/mysql-5. ...
- 百万年薪python之路 -- MySQL数据库之 常用数据类型
MySQL常用数据类型 一. 常用数据类型概览 # 1. 数字: 整型: tinyint int bigint 小数: float: 在位数比较短的情况下不精确 double: 在位数比较长的情况下不 ...